根据某一条件从数据库表中查询『有』与『没有』,只有两种状态,那为什么在写 SQL 的时候,还要 SELECT COUNT(*) 呢?
图片来自 Pexels
无论是刚入道的程序员新星,还是精湛沙场多年的程序员老白,都是一如既往的 COUNT。
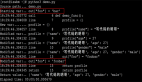
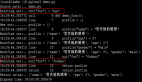
目前多数人的写法
多次 REVIEW 代码时,发现如现现象:业务代码中,需要根据一个或多个条件,查询是否存在记录,不关心有多少条记录。
普遍的 SQL 及代码写法如下:
- ##### SQL写法:
- SELECT count(*) FROM table WHERE a = 1 AND b = 2
- ##### Java写法:
- int nums = xxDao.countXxxxByXxx(params);
- if ( nums > 0 ) {
- //当存在时,执行这里的代码
- } else {
- //当不存在时,执行这里的代码
- }
是不是感觉很 OK,没有什么问题?
优化方案
推荐写法如下:
- ##### SQL写法:
- SELECT 1 FROM table WHERE a = 1 AND b = 2 LIMIT 1
- ##### Java写法:
- Integer exist = xxDao.existXxxxByXxx(params);
- if ( exist != NULL ) {
- //当存在时,执行这里的代码
- } else {
- //当不存在时,执行这里的代码
- }
SQL 不再使用 COUNT,而是改用 LIMIT 1,让数据库查询时遇到一条就返回,不要再继续查找还有多少条了。
业务代码中直接判断是否非空即可!
根据查询条件查出来的条数越多,性能提升的越明显,在某些情况下,还可以减少联合索引的创建。
总结
COUNT() 有两个非常不同的作用:
它可以统计某个列值的数量,也可以统计行数。在统计列值时要求列值是非空的(不统计 NULL)。
如果在 COUNT() 的括号中定了列或者列表达式,则统计的就是这个表达式有值的结果数。......COUNT() 的另一个作用是统计结果集的行数。当 MySQL 确认括号内的表达式值不可能为空时,实际上就是在统计行数。
最简单的就是当我们使用 COUNT(*) 的时候,这种情况下通配符 * 并不像我们猜想的那样扩展成所有的列,实际上,他会忽略所有列而直接统计所有的行数。
——《高性能MySQL》
不管怎样,我们判断是否存在。只需确定,有和无,而不是,无还是有多少!在有的情况下,直接返回,而不需要继续统计行数!
巧妙的使用 LIMIT 1,获得更高效率,尤其是在某些复杂且不规范的语句中效果更明显!
作者:程序猿囧途
编辑:陶家龙
出处:toutiao.com/i6826511837840802315