













深夜,领导:“你写的接口有问题!赶紧起床瞧瞧”。Ding!催命软件一响,你就知道,该 Work 了......
图片来自 Pexels
可思来想去,觉得不可能啊。我的代码,就是一个简单的 Redis 查询啊,难不成是 Redis 挂了?
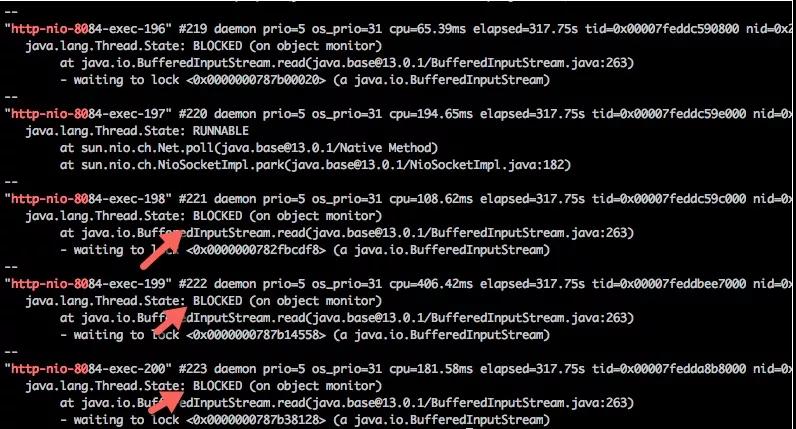
同事把证据全部发到了群里,是你的接口无疑。一个简单的 Get 查询,平均耗时达到了 2 秒。jstack,promethus 的监控,把问题全部指向到了你的接口!
登录 Redis 服务器,一切正常。该怎么办?要这么不明不白不清不楚的背个章丘大铁锅么?
快是原罪
这种情况下,要相信自己的直觉。你的接口又快又好,很可能是木秀于林,鹤立鸡群,当了替罪鸟。
在 “某些” "高并发"环境下,由于资源未做隔离,在发生问题的时候,一些日志和工具的表现,会有非常强的迷惑性。
发生问题的,都是速度最快、请求最多的接口,但理论上并不可能。
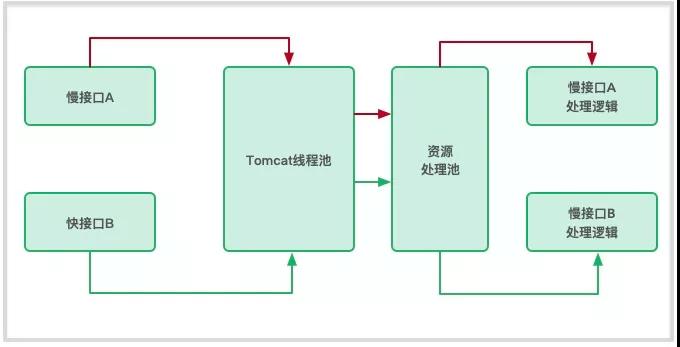
如上图。这种情况很常见。大多数请求,通过 Tomcat 线程池的调度,进行真正的业务处理。
当然线程池是不干这种脏活的,它把请求交给资源处理池去处理,比如:
- 一个数据库连接池,执行耗时的统计操作和迅速的查询操作。
- 一个 Redis 连接池,执行阻塞性的慢查询和简单的 GET SET。
- 一个 Http 连接池(HTTPClient、OkHTTP 等),远程调用速度不等的资源。
- ...
我们平常的编码中,通常都会共用这样的资源池。因为它写起代码来简单,不需要动脑。
但如果你的服务本身,并没有做好拆分以及隔离,问题就是致命的。比如,你把报表接口和高并发的 C 端接口放在了一个实例上。
这时候,你就有可能被报表接口给坑了。
一个例子
我们以数据库连接池为例,来说明一下这个过程,先看一下以下基础信息:
- Tomcat 的连接池,配置大小为 200 个。
- MySQL 的连接池,配置大小为 50 个,算是比较大了。
- 接口 A 需要调用耗时的查询,耗时为 5 秒。
- 接口 B 速度非常快,查询数据库响应时间在 200ms 以下。
速度快的 B 接口,请求量是远远大于接口 A 的,平常情况下相安无事。
有一天,接口 A 忽然有了大量的查询,由于它的耗时比较长,迅速把数据库的 50 个连接池给占满了(接口 B 由于响应快,持有时间短,慢慢连接会被 A 吃掉)。
这时候,无论是接口 A,还是接口 B 的请求,都需要等待至少 5 秒钟,才能获取下一条数据库连接,业务才能正常走下去。
不一小会儿,服务的状态就变成这样:
- 数据库连接池 50 个连接,迅速占满,而且几乎全被慢查询占满。
- Tomcat 连接池的 200 个连接,迅速被占满,其中大部分是速度快的接口 B,因为它的请求量大速度快。
- 所有接口都 Block 在 Tomcat 的线程上。进而造成:哪怕是查询一个非数据库的请求,也要等待 5 秒左右。
一般在遇到这种问题的时候,我们都倾向于使用 jstack 打印信息堆栈,或者查看一些内部的监控曲线。
可惜的是,这些信息,大部分都是骗人的,你看到的慢查询,并不是真正的慢查询。
从上面的分析中,你应该很容易看出问题的症结所在:未隔离的瓶颈资源引起上游资源的连锁反应。
但在平常的工作中,我不止一次看到有同学对此手忙脚乱。很多证据都指向了一些又快又好的接口,而这些根本和它们一点关系都没有。他们乐呵呵的截图,@相关人等,嚣张至极。
在遇到这种情况的时候,你可以使用下面的脚本进行初步分析:
$ cat 10271.tdump| grep "waiting to lock " | awk '{print $5}' | sort | uniq -c | sort -k1 -r
26 <0x0000000782e1b590>
18 <0x0000000787b00448>
16 <0x0000000787b38128>
10 <0x0000000787b14558>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
上面的例子,我们找到给 0x0000000782e1b590 上锁的执行栈,可以发现全部是卡在 HttpClient 的读操作上了。
在实际场景中,可以看下排行比较靠前的几个锁地址,找一下共性:
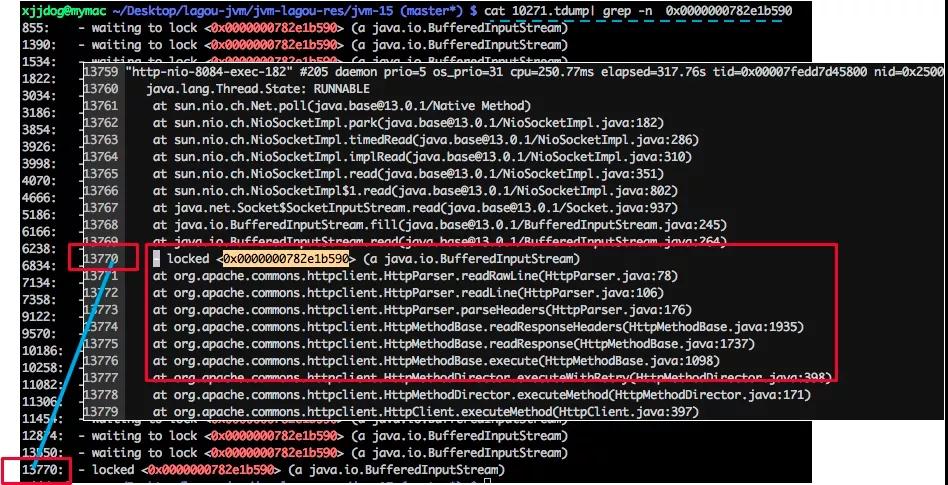
而这些显示信息非常少的堆栈,才是问题的根本原因。
如何解决
增加 Tomcat 连接池的大小,或者增加连接池的大小,并不能解决问题,大概率还会复现。
最好的解决方式,当然是把耗时的服务和正常的服务拆分开来,比如时下流行的微服务。你的服务查询慢,自己访问超时,和我的服务,一丁点儿关系都没有。
但是,你的服务即然能遇到这种问题,就证明你的公司缺乏这种改造的条件。就只能在单体服务上来做文章。
这种做法,就是隔离:
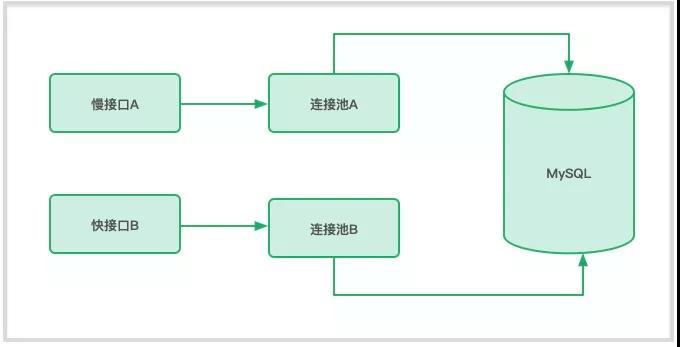
如上图,我们在同一个工程里,创建了两个 MySQL 数据库连接池,指向了相同的 MySQL 地址。
使用这种方式,连接池的操作,就能够相对做到互不影响。但到现在为止,还没完,因为你的 Tomcat 连接池依然是共享的。
慢查询相关的,从连接池中获取连接的策略,要改一下,不能一直等待,而应该采用 FailFast 的方式(获取连接短时间的超时也是可以的),否则症状还是一样。
时下流行的熔断概念,也在一定程度上实践这种隔离性。
结语
我们还可以联想到类似的场景:
JVM 发生 STW,停顿期间,受影响最大的,就是那些又快请求又大的接口。而那些耗时接口,由于平常就是那个鸟样,倒没人关注它的异常情况。
一堆接口连接了同一个数据库,当数据库发生抖动,受影响最大的,依然是那些又快请求又大的接口。因为那些耗时的慢查询,一直就是那样表现的,没人会怀疑到它们身上来。
殊不知,只要这些烂接口请求量一上升,就会像一颗老鼠屎,坏了整锅汤,所有的请求都会被拖累。
这有点类似于我们平常的工作:低效的人一增多,就会拖累整个项目的进度。领导一直在纳闷,为什么那么多技术好手,效率那么低呢?
这是因为,他们被拖累了。过于关注个体,最根本性的问题却掩盖在表象之下。
公司内部的研发,从来不应该一视同仁。不同技术追求的员工,也应该做到类似的隔离,宁缺毋滥。
好手组成的团队,交流顺畅,目标一致,效率奇高;而那些擅长拖慢项目的员工,就应该放在低效的团队,将加班进行到底。
说了这么多,问题的关键就在于:并不是每一个人都能了解这个规律,很少有人会关注这背后的根本原因。你要给领导解释你的接口没有问题,需要花费很大的力气。
“老板,我找到原因了。是因为一个 MySQL 慢查询,把 Tomcat 的连接池占满了,造成了 Redis 对应的 Http 请求响应慢。”这样错综复杂的关系,真的让人很头痛。
“很好”,领导说,“这个问题,就有你牵头来解决一下吧”。
你瞧,做领导的,大多不会关注问题产生的原因,他只关注谁能解决这个问题,哪怕不是你的问题。谁让你代码写得好,需求又做的快呢!
作者:小姐姐味道,一个不允许程序员走弯路的公众号。聚焦基础架构和 Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。
编辑:陶家龙
出处:转载自公众号小姐姐味道(ID:xjjdog)



















