本文转载自微信公众号「codeasy」,作者阎华 。转载本文请联系codeasy公众号。
要弄清楚使用富领域模型有什么问题,我们要先从应用服务层怎么使用富领域模型说起。
应用服务是编舞者
领域模型具有了行为以后,就成为了一个个动作灵活的舞蹈家,但很多情况下观众并不想只看某一个舞蹈家展示他们的动作,所以,应用服务需要把一个或若干个领域模型的行为编排起来,来完成符合某个场景(Use Case)需要的一支舞蹈。
我们来看看 SprintApplicationService 这个应用服务里的一个方法:
- /**
- * 将一个BacklogItem提交到一个Sprint中
- * @param aCommand 表示客户端发起的一个命令
- */
- public void commitBacklogItemToSprint(
- CommitBacklogItemToSprintCommand aCommand) {
- TenantId tenantId = new TenantId(aCommand.getTenantId());
- //Step1:加载一个sprint到内存
- Sprint sprint =
- this.sprintRepository()
- .sprintOfId(
- tenantId,
- new SprintId(aCommand.getSprintId()));
- //Step2: 加载一个BacklogItem到内存
- BacklogItem backlogItem =
- this.backlogItemRepository()
- .backlogItemOfId(
- tenantId,
- new BacklogItemId(aCommand.getBacklogItemId()));
- //Step3:将BacklogItem提交到一个sprint,内存级操作
- sprint.commit(backlogItem);
- //Step4:持久化sprint
- this.sprintRepository().save(sprint);
- }
这里Sprint和BacklogItem是两个聚合根,他们分别对应了一组实体。
第一步和第二步从数据库加载了两个聚合到内存,在内存里有两个对象图:
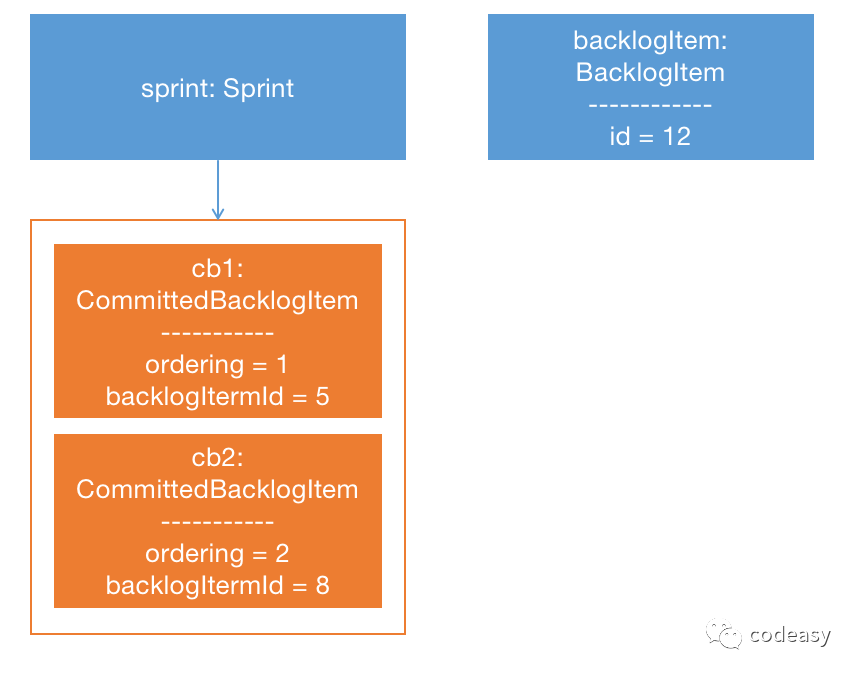
而当我们执行完第三步时(即执行 sprint.commit(backlogItem) 后),内存里的对象图变成了:
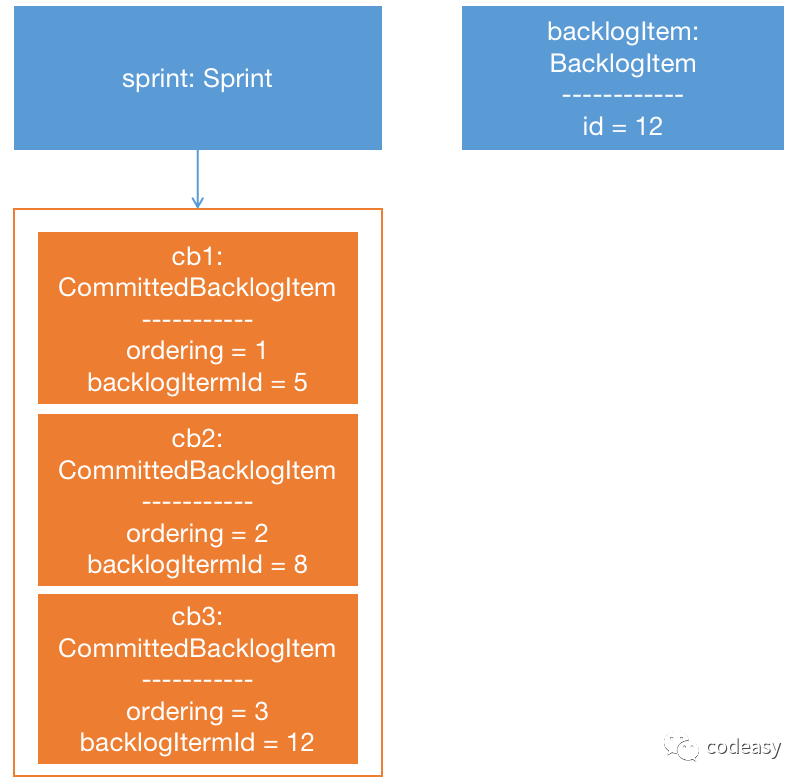
这时,在 sprint的backlogItems 这个集合里,多出一个 cb3 ,它 的 ordering 是 3 , backlogItemId 是 12 。
当把 id 是 12 的 backlogItem 加入到 spint 里,需要做一些校验,以及新产生一个 cb3 并正确设定它的 ordering 的值,这些都是 sprint 这个聚合内部发生的逻辑,应用服务是不知道这些领域逻辑的,甚至都不知道有这些逻辑的存在。
更复杂的场景,可能导致聚合内多个对象的内存状态发生了变化。
注意,这时候只是内存里对象的状态发生了变化。到了第四步时,应用服务委托 sprintRepository 去持久化 sprint 后,内存对象的变化才会反应到对应的数据库的表(一个或多个)内容的变化(即更新或插入了数据)—— 导致多少表的什么变化,应用服务也是不知道的。
正是由于这样职责划分,才会出现我们第一篇文章里看到的结果 —— 领域层的代码很丰富,而应用层的代码很少,只有这里看到的编排逻辑。这带来的好处前两篇文章说了很多了,不再赘述了。
但这样做有什么问题呢?
为什么会投鼠忌器
我们说不敢使用富领域模型一定是有顾虑的,既然投鼠忌器,那这个“器”是什么呢?
可能有些人已经看出来了,“器”有两个:
- 性能
- 并发冲突
如果我们只是按面向对象的设计方法去实现富领域模型,可能会导致对象关联太多,内存中的对象图会是下面这个样子:
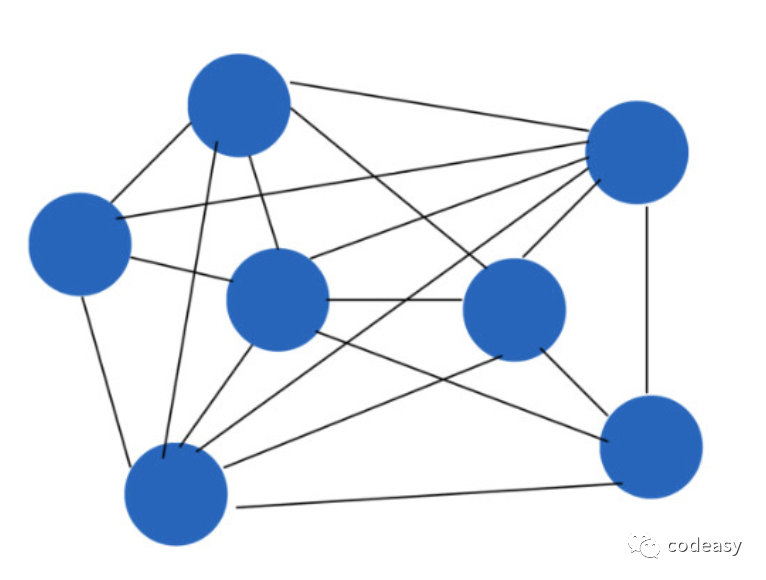
image.png
连线表示对象引用
那在应用服务层可能会加载非常多的对象到内存里,很费内存。另外,修改时可能导致很多对象状态的变更,修改引发的并发冲突会比较多。
DDD恰恰是要解决这个问题的,它推荐把对象分成不同的“小组”,也就是我们前面说的聚合。聚合和聚合之间是不能做对象引用的,只能用ID引用,这样加载一个聚合时不会把其他聚合也加载到内存。
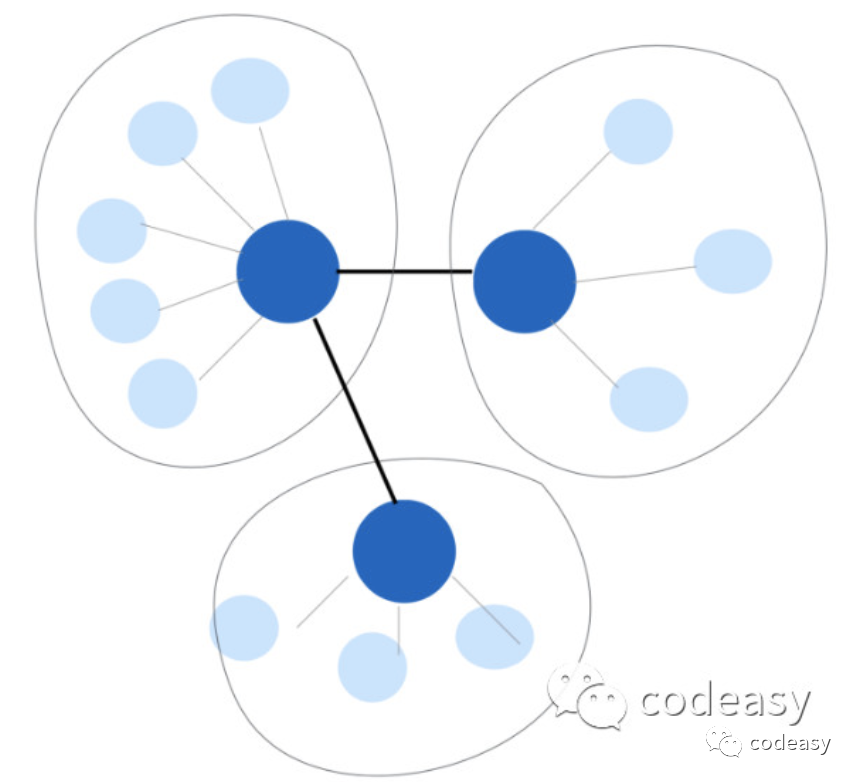
image.png
黑色的链接线表示的是ID引用
总结一句话,要通过小的聚合来避免性能和修改的并发冲突问题。
但是……
聚合要多小才合适
但是聚合多小才算合适呢?极端情况下,一个表一个聚合就足够小了,但这又回到了贫血模型。
聚合还是要代表一个业务一致性边界的,比如OrderItem的属性变化,和Order的属性变化应该保证一定的业务规则不被破坏,在这个前提下,聚合要设计的尽可能小。
从IDDD_Sample的代码里,我们是看不到设计聚合的分析过程的,只能看到结果,想知道分析的过程,推荐去看《实现领域驱动设计》书中对这个例子的分析过程。
我们在后续的文章会分析另外一个开源示例(Library),那个例子里给出了分析过程的记录,到时候再详细讲解聚合的识别过程。
在我实践的过程中,发现大部分人设计的聚合都偏大。最近我尝试使用领域故事会和事件风暴这两个方法来识别聚合,发现得到的聚合比以前的更小更合理。这得益于基于场景去分析,而不是从技术的角度去建模。
《领域驱动设计模式、原理与实践》是另一本非常棒的关于DDD的书,里面曾经说过“如果你发现一个聚合可能会带来性能和并发的问题,就要回过头去看看聚合是不是设计的太大了”。之前我一直觉得这是因果倒置的无奈之举。现在感觉是有合理的逻辑在的:
- 按场景分析的话,聚合的粒度会比较小
- 如果发现有性能和并发的问题,说明聚合太大了
- 那可能是没有按场景分析,所以要再按场景重新审视一下聚合的设计
所以这个技术问题本质上是一个模型分析/设计的问题,但分析/设计的问题比技术问题更难解决,更难有固定的套路。后续我也打算写另外一个系列,是关于DDD设计过程中的反模式的,其中就有很多是关于不合理的聚合设计的。
接下来聊聊CQRS
现在,我们还是聚焦在IDDD_Sample示例的代码分析。聚合设计过大其中有一个原因,是开发人员考虑了太多的查询的需要。合理地使用CQRS模式可以避免这个问题。另外,使用CQRS本身也能解决很多的性能问题。
我们下一篇看看IDDD_Sample中是怎么运用CQRS这个模式的。