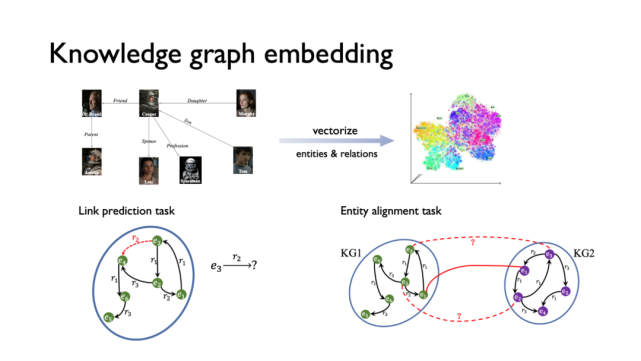
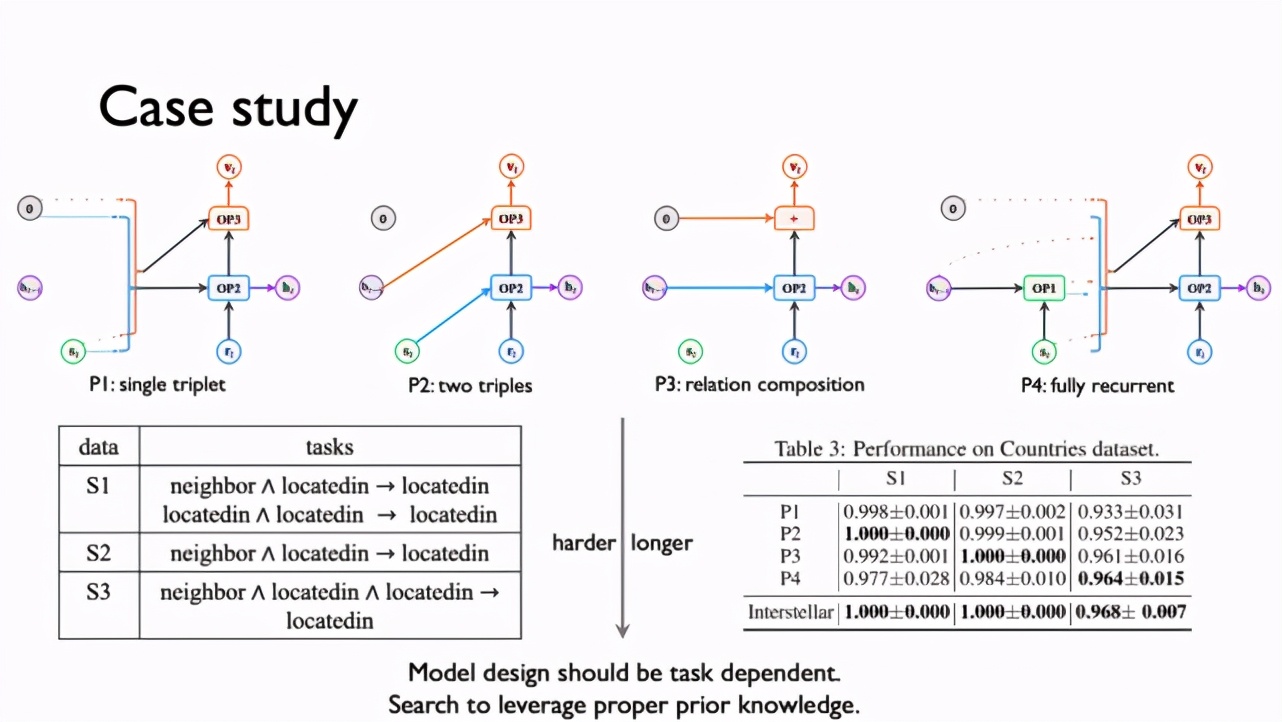
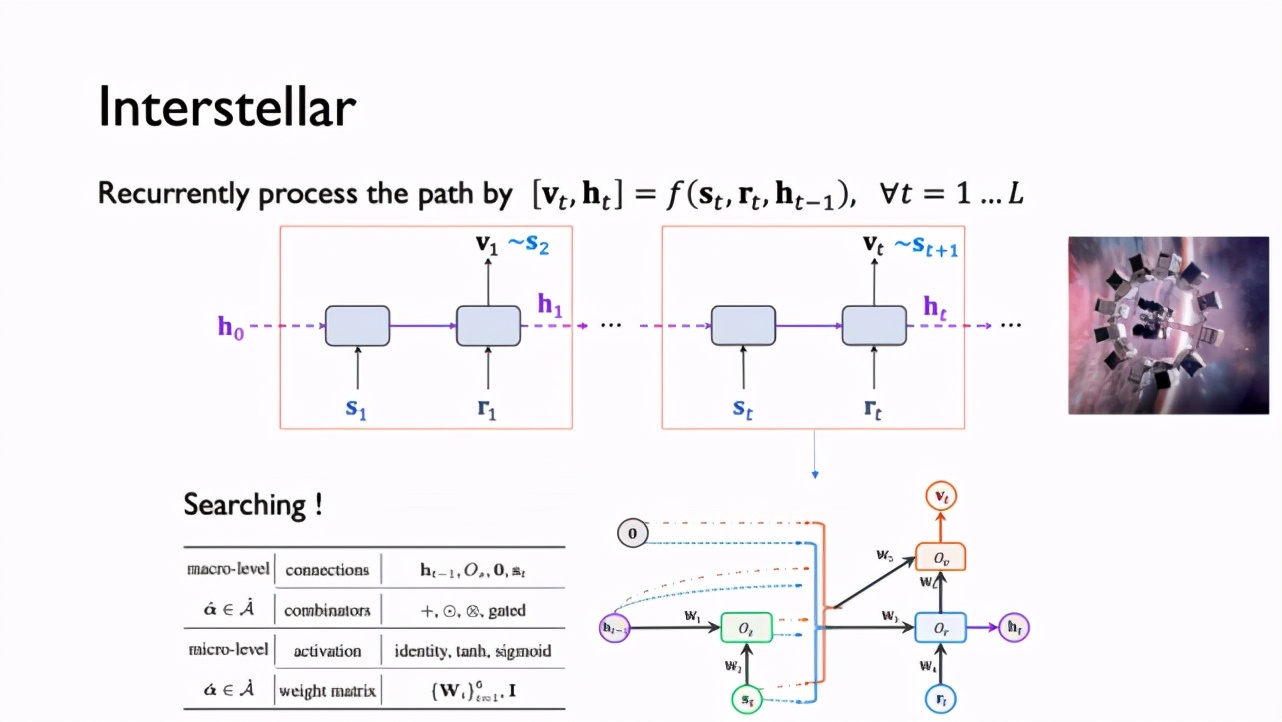
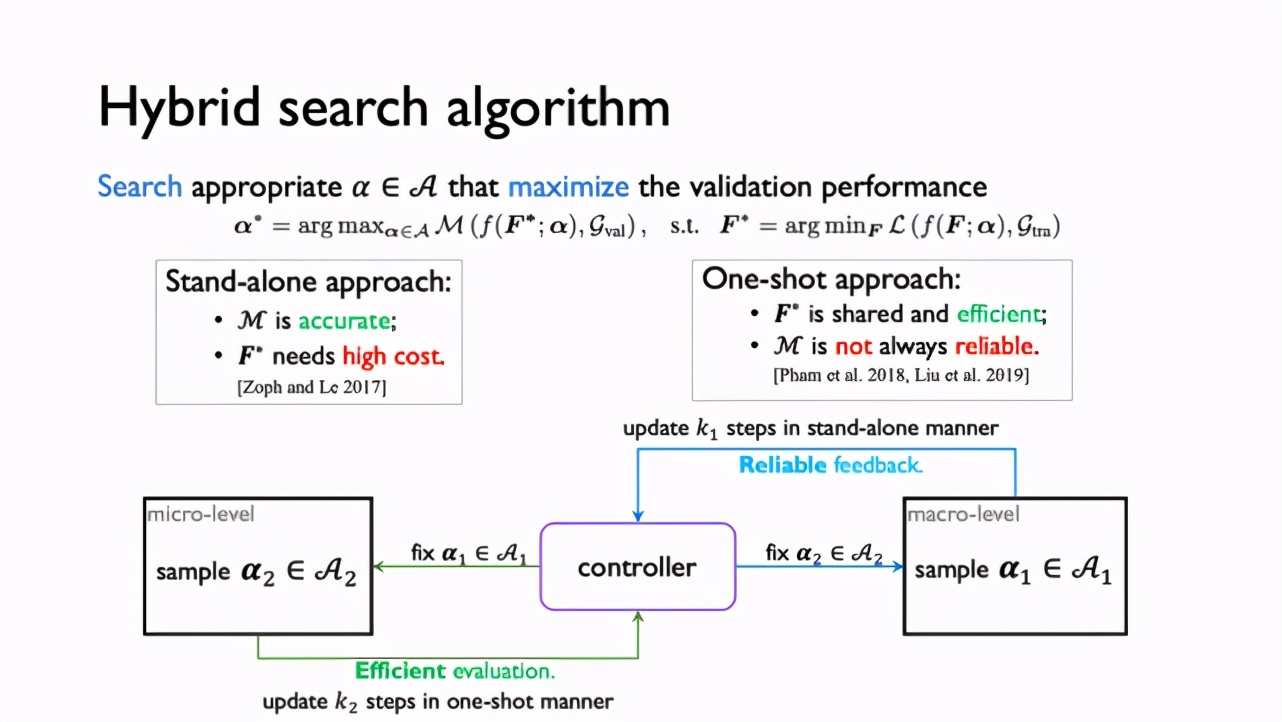
前不久,来自第四范式的资深研究员姚权铭博士和大家分享了其参与并被 NeurIPS 2020 接收的论文《Interstellar: Searching Recurrent Architecture for Knowledge Graph Embedding》。
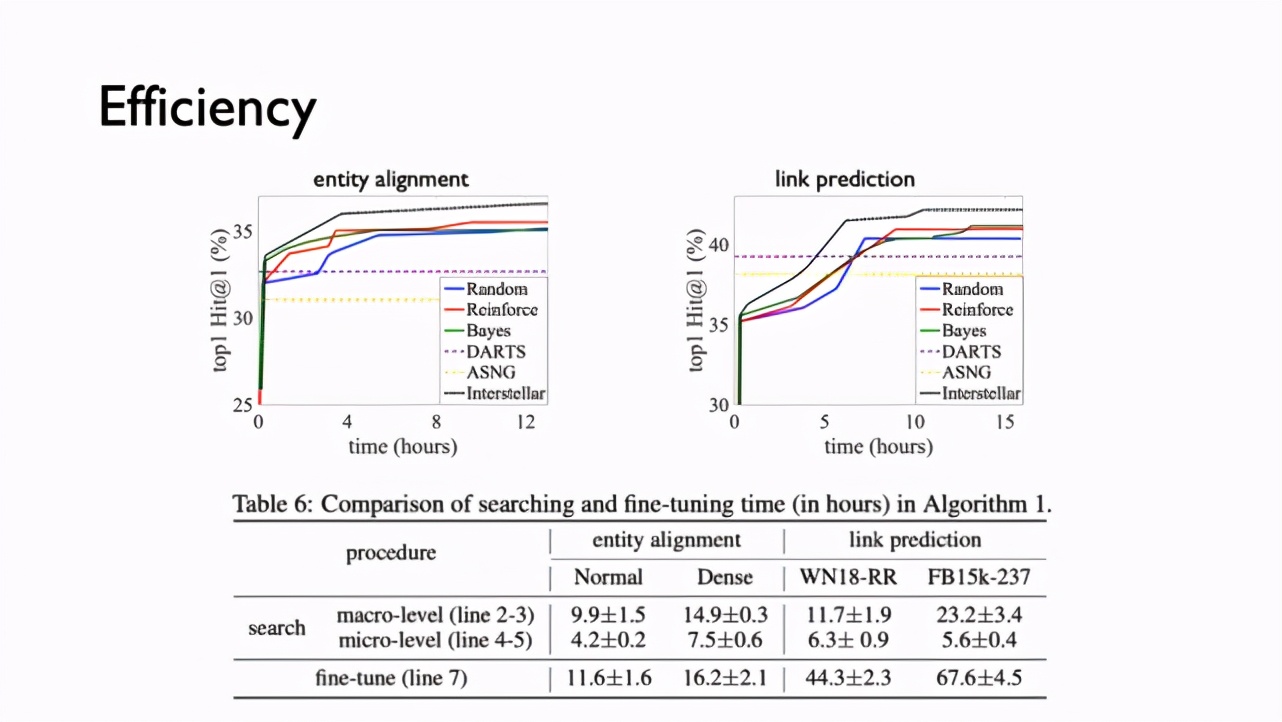
这项研究受神经架构搜索(NAS)的启发,提出将 Interstellar 作为一种处理关系路径中信息的循环架构。此外,该研究中的新型混合搜索算法突破了 stand-alone 和 one-shot 搜索方法的局限,并且有希望应用于其他具有复杂搜索空间的领域。 视频链接:https://v.qq.com/x/page/n3207ugke4j.html?start=6 知识图谱嵌入(Knowledge Graph Embedding)目前在学习知识图谱(KG)中的知识表达上具有很强的能力。在以往的研究中,很多工作主要针对单个三元组(triplet)建模,然而对 KG 而言,三元组间的长链依赖信息在一些任务上也很重要。 在第四范式、香港科技大学这篇被 NeurIPS 2020 会议接收的论文中,研究者基于由三元组组成的关系路径(relational path)提出 Interstellar 模型,通过搜索一种递归神经网络,来处理关系路径中的短链、长链信息。 论文链接:https://arxiv.org/pdf/1911.07132.pdf 代码链接:https://github.com/AutoML-4Paradigm/Interstellar 首先,该研究通过一组模拟实验分析了用单一模型对不同任务中关系路径建模的难度,并由此提出通过搜索的方式对不同任务针对性地建模。为了提高搜索效率,该研究提出了一种混合搜索算法(hybrid-search algorithm),在链接预测(link prediction)和结点匹配(entity alignment)任务上,能高效地搜索到具有更好效果的模型。 背景介绍 知识图谱嵌入(KG Embedding)旨在把图谱中的结点(entities)和关系(relations)映射到一个低维空间,同时保留图中的重要性质。在目前学术领域,一些工作基于单个三元组(s,r,o)建模,如 TransE、RESCAL、DistMult、RotatE、ConvE、SimplE 等,它们在链接预测任务(即给定头结点 s 和关系 r ,预测尾结点 o )上表现良好,而在结点匹配任务(即给定两个 KG,预测哪些结点有相同含义)上性能一般。另一类基于关系路径的工作,如 IPTransE、Chains、RSN 等则在结点匹配任务上表现更好。 研究人员观察到,关系路径包含多种重要信息,如单个三元组的短链信息、多个关系的复合、多个三元组之间的长链信息等等。基于此,该研究提出 Interstellar 模型,通过搜索的方式来根据不同任务,有针对性地对关系路径进行建模。 动机 为了验证不同模型对不同任务的拟合能力不同,研究人员设计了一组模拟实验。Countries 数据集有 S1-S3 三个不同任务,预测难度逐一增大,需要模拟的预测路径逐渐变长。为此研究者基于先验知识(prior knowledge)设计了 4 类模式 P1-P4,分别用于建模单个三元组、连续的两个三元组、多重关系的复合,以及全递归连接。直观上看,P4 的建模能力更强,但在有限的样本上,样本复杂度同样重要,选择更能拟合数据规律的模型能够获得更好的效果。 如下表所示,在 S1 这个简单任务上,基于单个或两个三元组的模型 P1 和 P2 表现更好,在 S2 上 P1-P3 均优于 P4,而在 S3 上,递归模型 P4 由于能模拟更长路径而胜出。由此我们可以得出,关系路径上的建模应该是模型相关的,如果我们能够通过搜索的方式把专家的先验知识融入到建模能力中,那么针对不同任务,模型就可以自动地找到更优解。 问题定义与搜索空间 首先,研究者将 Interstellar 定义为一个递归式地处理关系路径的模型,在每一个递归步中,模型关注到一个三元组,信息在三元组之内、之间以不同方式穿梭。与传统 RNN 不同,这里的每一步有两个输入,同时由于需要考虑知识图谱相关的领域知识,单纯地使用 RNN 对其建模是不合适的。为了利用好知识图谱领域的先验知识,同时使模型可以适用于不同任务,受神经网络搜索技术(Neural Architecture Search)的启发,该研究把建模问题定义为搜索问题,来自适应地对不同任务建模。 通过对知识图谱嵌入领域相关模型的总结,该研究提出上图的搜索空间,利用运算单元 O_s 来处理结点嵌入 s_t ,用 O_r 来处理关系嵌入 r_t ,用 O_v 来输出向量 v_t 从而预测下一个结点 s_t+1 。具体而言,该研究在 macro-level 搜索不同单元间的连接方式(connections)和复合方式(combinators),在 micro-level 搜索激活函数(activation)与权重矩阵(weight matrix)。 搜索算法 该研究的目标是更快地在搜索空间中找到能在验证集上达到更好性能的模型,这可以通过 bi-level 优化方式来定义。为了求解这个优化问题,学术界目前有两类方法。一类是 stand-alone 算法,对每个模型单独训练参数 F 至收敛,这样可以得到准确的性能评估 Μ ,但训练代价较高;另一类是 one-shot 算法,建立一个包含所有网络的超网络(supernet),不同模型在超网络中采样,同时可以参数共享,这样的评估方式更高效,但不总能保证可靠性。研究人员观察到在 Interstellar 的建模上,one-shot 方式并不可靠。 为了解决这些问题,该研究提出 Hybrid 搜索算法,在 macro-level 采用 stand-alone 方式,给定 α_2 ,从 Α_1 中采样不同的 α_1 ,训练模型参数至收敛,拿到对 α_1 的可靠评估;在 micro-level 采用 one-shot 方式,给定 α_1 ,从 Α_2 中采样不同的 α_2 ,同时让不同 α_2 对应的模型在超网络中共享参数,加速训练评估的过程。二者结合,即保证了搜索准确性,又保证了搜索效率。 实验结果 在搜索效果上,该方法在结点匹配和链接预测任务中,都能针对不同数据任务搜索到更好的模型,这得益于 Interstellar 上合理的搜索空间和高效的搜索算法。 在搜索效率上,Hybrid 算法能够比随机搜索(Random)、强化学习(Reinforce)、贝叶斯优化(Bayes)算法更快地得到更好的模型,同时下图中的两条虚线(表示单独的 one-shot 算法)表明其在这个问题上性能并不好。在搜索时间上,Hybrid 算法和调参(如 learning rate、batch size 等参数)时间是相当的,说明这个搜索方法代价并不高。在新的问题中,先搜索模型再进行调参是一个不错的选择。