本文转载自微信公众号「三太子敖丙」,可以通过以下二维码关注。转载本文请联系三太子敖丙公众号。
这个问题是我当初在面天猫的时候,2面的面试官问我的,我之前已经写过mvcc的文章了,但是在看到我笔记的里的这个问题的时候我准备单独理一遍,所以就有了这个文章。
现在,主流关系型数据库产品基本都实现了MVCC的特性,快照在MVCC中起着重要的作用,代表某一时刻数据的版本,它是实现一致性读的基础。在更新操作没提交前,数据的前镜像存储在Undo中,利用Undo可以实现一致性读,事务回滚以及异常恢复等操作,下面就聊聊MySQL事务,MVCC,快照及一致读的原理与实现。
MySQL中的事务
事务在RDBMS系统中概念基本都是一样的,是由一组DML语句构的工作单元,要么全部成功,要么全部失败。
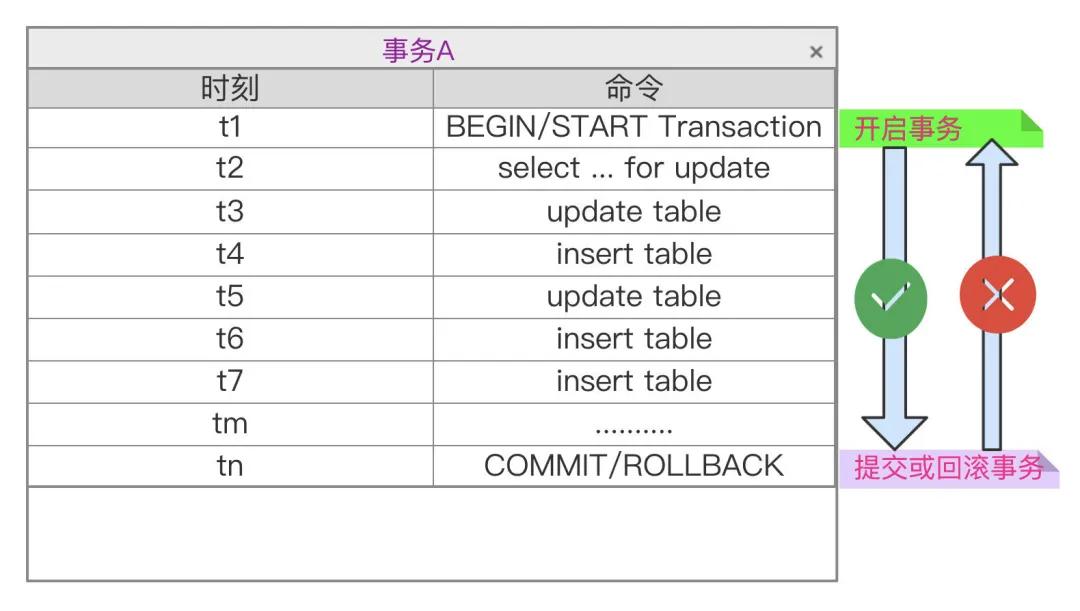
开发过程中,比较关心长事务,即包含DML语句多的工作单元,事务太长会导致一些错误,例如可能由于事务数据包大小超过参数max_allowed_packet设置会导致程序报错,也可能有事务中某个SQL对应接口报错,导致整个服务调用失败,在程序设计时,应该考虑避免长事务带来的业务影响。
事务的ACID
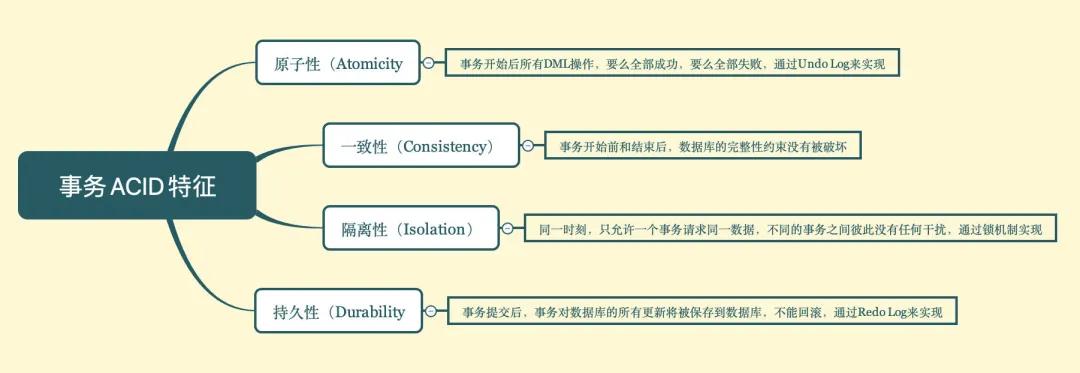
image-20201114221841801
原子性是事务隔离的基础,隔离性和持久性是手段,最终目的是为了保持数据的一致性。
事务的并发问题
- 脏读:事务A读取了事务B未提交的数据。
- 不可重复度:事务A多次读取同一份数据,事务B在此过程中对数据修改并提交,导致事务A多次读取同一份数据的结果不一致。
- 幻读:事务A修改数据的同时,事务B插入了一条数据,当事务A提交后发现还有数据没被修改,产生了幻觉。
不可重复读侧重于update操作,幻读侧重于insert或delete。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表。
事务隔离级别
事务隔离是数据库处理的基础之一,隔离级别在多个事务同时进行更改和执行查询时,对性能与结果的可靠性、一致性和可再现性之间的平衡进行调整,InnoDB利用不同的锁策略支持不同隔离级别。MySQL中有四种隔离级别,分别是读未提交(READ UNCOMMITTED),读已提交(READ COMMITTED),可重复读(REPEATABLE READ)以及串行化(SERIALIZABLE)。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ UNCOMMITTED | Yes | Yes | Yes |
| READ COMMITTED | No | Yes | Yes |
| REPEATABLE READ | No | No | Yes |
| SERIALIZABLE | No | No | No |
InnoDB并发控制
MVCC特性
InnonDB是一个支持行锁的存储引擎,为了提供更好支持的并发,使用了非锁定读,不需要等待访问数据上的锁释放,而是读取行的一个快照,该方法是通过InnonDB MVCC特性实现的。
MVCC是Multi-Version Concurrency Control的简称,即多版本并发控制,作用是让事务在并行发生时,在一定隔离级别前提下,可以保证在某个事务中能实现一致性读,也就是该事务启动时根据某个条件读取到的数据,直到事务结束时,再次执行相同条件,还是读到同一份数据,不会发生变化。
MVCC的好处
读不加锁,读写不冲突。在读多写少的OLTP应用中,读写不冲突是非常重要的,可以增加系统的并发性能。
在MVCC中,有两种读操作:快照度和当前读。
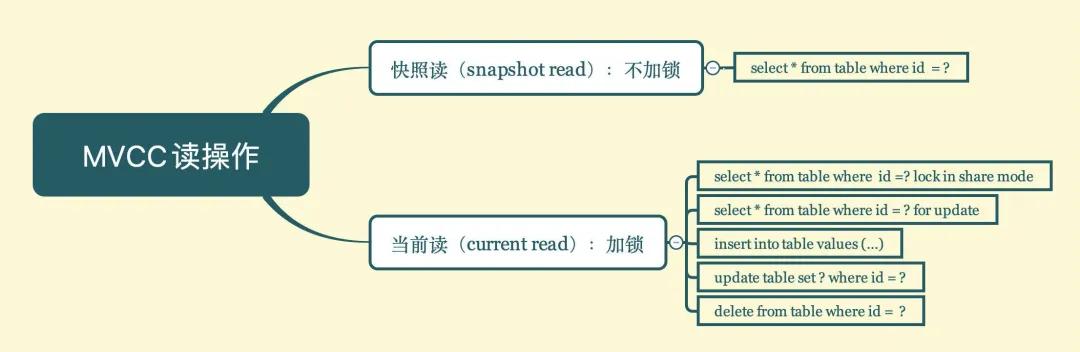
MVCC快照
MVCC内部使用的一致性读快照称为Read View,在不同的隔离级别下,事务启动时或者SQL语句开始时,看到的数据快照版本可能也不同,在RR、RC隔离级别下会用到 Read view。
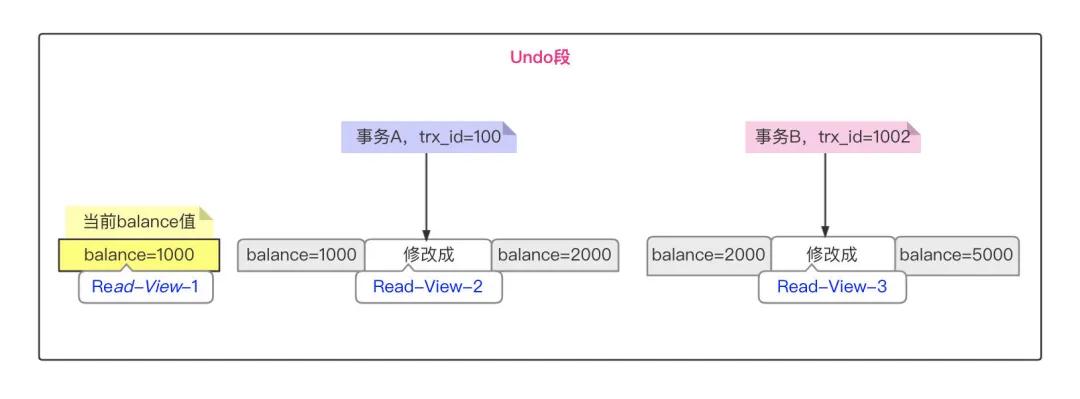
InnoDB 里面每个事务有一个唯一的事务ID,称为Transaction ID,它是在事务开始的时候向InnoDB的事务系统申请的,是按申请顺序严格递增的。而每行数据都有多个版本。每次事务更新数据的时候,都会生成一个新的数据版本Read View,并且把Transaction ID赋值给这个数据版本的事务 ID,标记为 row_trx_id。同时旧的数据版本要保留,并且在新的数据版本中,能够有信息可以直接拿到它,数据表中的一行记录,其实可能有多个数据版本 ,每个版本有自己的 row_trx_id。
InnoDB行格式
目前InnoDB默认的行格式Dynamic,是Compat格式的增强版,记录头结构信息占用5个字节,事务ID和回滚指针分别占用6和7个字节,行格式如下:

记录头结构
| 项目 | 大小(bit) | 描述 |
|---|---|---|
| () | 1 | Unknown |
| () | 1 | Unknown |
| deleted_flag | 1 | 数据行删除标记 |
| min_rec_flag | 1 | =1如果该记录被预先被定义为最小的记录 |
| n_owned | 4 | 拥有的记录数 |
| heap_no | 13 | 索引堆中该条记录的排序位置 |
| record_type | 3 | 记录类型;000:普通,001:B+树叶子节点,010:伪列Infinum,011:Supernum,1xx:保留 |
| next_record | 16 | page中下一条记录的相对位置 |
| Transaction ID | 48 | 记录中的事务ID,固定6个字节 |
| Rollback Pointer | 56 | 回滚指针,固定7个字节 |
数据行存储
#创建表
mysql> create table store_users (id int not null auto_increment primary key comment '主键id',name varchar(20) not null default '' comment '姓名');
# 查看表状态信息
mysql> show table status like 'store_users'\G
Row_format: Dynamic #默认行格式为Dynamic
Rows: 0 #行数
Avg_row_length: 0 #平均行长度
Data_length: 16384 #初始化段大小16K
#开启事务,插入数据
mysql> begin;
mysql> insert into store_users values(null, 'aaaaa'),(null, 'bbbbb');
#查看InnoDB分配的事务ID
mysql> select trx_id from information_schema.innodb_trx\G
trx_id: 8407246 #事务ID
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
分析表的行头信息以及隐藏的事务ID和回滚指针。
# 用Linux下的工具hexdump进行分析
$ hexdump -C -v /usr/local/var/mysql/test/store_users.ibd > store_users.txt
$ vi store_users.txt
00010060 02 00 1b 69 6e 66 69 6d 75 6d 00 03 00 0b 00 00 |...infimum......|
00010070 73 75 70 72 65 6d 75 6d 05 00 00 10 00 1c 80 00 |supremum........|
00010080 00 01 00 00 00 80 48 ce 83 00 00 01 d8 01 10 61 |......H........a| #Record Header信息
00010090 61 61 61 61 05 00 00 18 ff d6 80 00 00 02 00 00 |aaaa............|
000100a0 00 80 48 ce 83 00 00 01 d8 01 1d 62 62 62 62 62 |..H........bbbbb|
000100b0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10表示变长字段长度,只有一个varchar(20)没有超过256字节,且没有NULL值。
- 00代表NULL标志位,第一行没有为NULL数据。
- 字符a的十六进制是61,即61 61 61 61 61代表的是字段值aaaaa
- 00 00 00 80 48 ce 6个字节就是Transaction ID,转换成十进制8407246,正是上面information_schema.innodb_trx.trx_id列的值,trx_id: 8407246 。
- 83 00 00 01 d8 01 10 7个字节是Rollback Pointer。
- 1c 80 00 00 01 是5个字节,代表Record Header信息。
隔离级别与快照
REPEATABLE READ
默认的隔离级别,一致读快照(Read View)是在第一次SELECT发起时建立,之后不会再发生变化。如果在同一个事务中发出多个非 锁定SELECT语句,那么这些SELECT语句在事务提交前返回的结果是一致的。

在RR下快照Read View不是事务发起时创建,而是在第一个SELECT发起后创建。

READ COMMITTED
在READ COMMITTED读已提交下,一致读快照(Read View)是在每次SELECT后都会生成最新的Read View,即每次SELECT都能读取到已COMMIT的数据,就会存在不可重复读、幻读 现象。

Undo回滚段
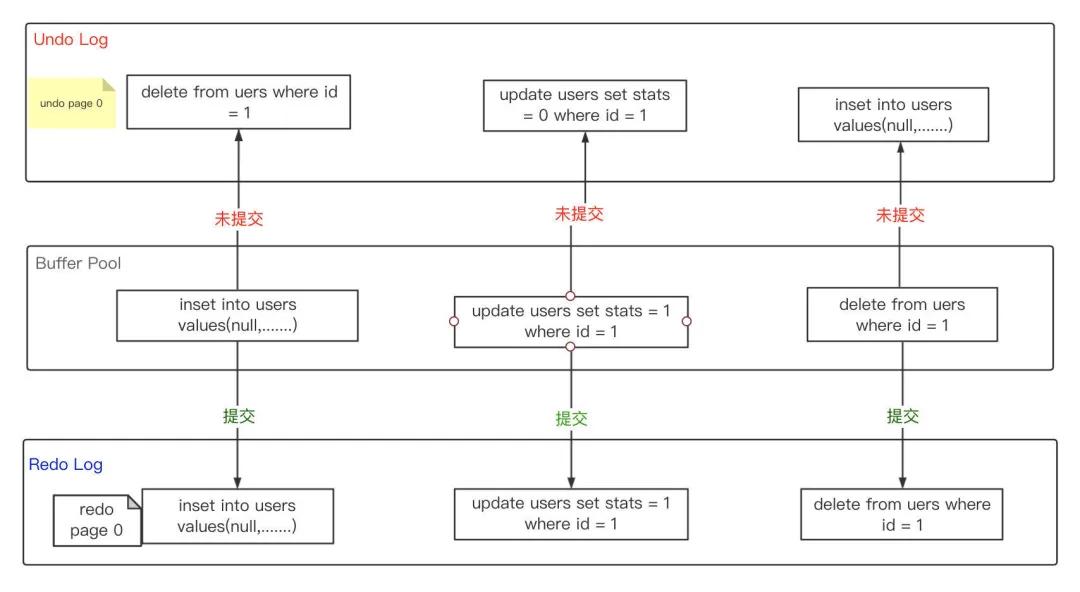
当开启事务执行更新语句(insert/update/deeldte),会经过Server层的处理生成执行计划,然后调用存储引擎层接口去读写数据,用户没有触发COMMIT或ROLLBACK之前,这些Uncommitted Data的数据称为前镜像(Post Image),数据存储在Undo Log,以便用户回滚或者MySQL Server Crash的恢复,同时Undo Log是循环覆盖使用。
#开启事务,更新账户余额,不提交事务。
mysql> start transaction;
mysql> update account set balance = 100000 where account_no = 10001;
Rows matched: 1 Changed: 1 Warnings: 0
- 1.
- 2.
- 3.
- 4.
上面在RR隔离级别下,开启一个事务,做update更新操作,不提交事务,通过show engine innodb status\G查看undo情况。
Trx id counter 8407258
Purge done for trx's n:o < 8407257 undo n:o < 0 state: running but idle
History list length 33
......
---TRANSACTION 8407257, ACTIVE 154 sec
2 lock struct(s), heap size 1136, 4 row lock(s), undo log entries 1
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
Trx id counter 8407258当前的事务ID,undo log entries 1使用了的undo entries,ACTIVE 154 sec事务持续时间,事务commit后,会调用Purge Thread把undo中的老数据清理掉。
回滚记录
insert:反向操作是delete,undo里记录的是delete相关信息,存储主键id即可。
udpate:反向操作是update,undo里记录的是update前的相关数据。
delete:反向操作是insert,undo里记录的是insert values(…..)相关的记录。
从这里可以知道,更新操作占用Undo空间的大小排序如下:
delete > update > insert
所以不建议物理delete删除数据,会产生大量的Undo Log,Undo快被写满就会发生切换,在次期间会有大量的IO操作,导致业务的DML都会变得很慢。
一致性读
MySQL官方文档对一致读的描述:

读操作基于某个时间点得到一份那时的数据快照,而不管同时其他事务对数据的修改。查询过程中,若其他事务修改了数据,那么就需要从 undo log中获取旧版本的数据。这么做可以有效避免因为需要加锁(来阻止其他事务同时对这些数据的修改)而导致事务并行度下降的问题。
在可重复读(REPEATABLE READ,简称RR)隔离级别下,数据快照版本是在第一个读请求发起时创建的。在读已提交(READ COMMITTED,简称RC)隔离级别下,则是在每次读请求时都会重新创建一份快照。
一致性读是InnoDB在RR和RC下处理SELECT请求的默认模式。由于一致性读不会在它请求的表上加锁,其他事务可以同时修改数据不受影响。

一行数据有多个版本,每个数据版本有自己的trx_id,每个事务或者查询通过trx_id生成自己的一致性视图。普通select语句是一致性读,一致性读会根据row trx_id和一致性视图确定数据版本的可见性,图中UR1,UR2就是undo,存储在Undo Log中,每次查询时根据当前data page和 Undo page构造出一致性数据页(Consistent Read Page),通过读取CR Page将数据返回给用户。
总结
介绍了MySQL事务,快照,MVCC以及Undo,虽然这些东西比较抽象,但是搞清楚这些东西是一件很有意义的事,能够帮助我们更好的理解和使用MySQL,也可以把这种设计思想用在自己业务系统中。其中Undo在MySQL中的作用很重要,它是MVCC能够快速创建快照基础,支撑系统的高并发。
好啦,以上就是本期的全部内容了,我是敖丙,你知道的越多,你不知道的越多,我们下期见。