













前言
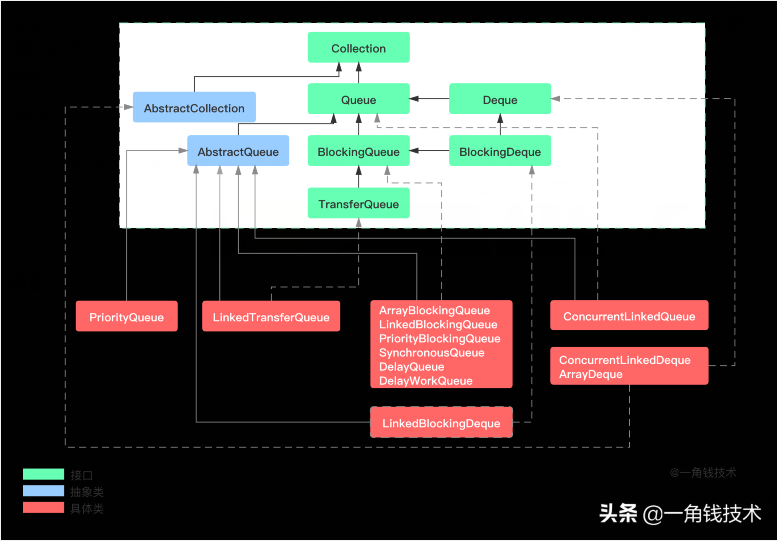
LinkedBlockingQueue 由链接节点支持的可选有界队列,是一个基于链表的无界队列(理论上有界),队列按照先进先出的顺序进行排序。LinkedBlockingQueue不同于ArrayBlockingQueue,它如果不指定容量,默认为 Integer.MAX_VALUE,也就是无界队列。所以为了避免队列过大造成机器负载或者内存爆满的情况出现,我们在使用的时候建议手动传一个队列的大小。
队列创建
- BlockingQueue blockingQueue = new LinkedBlockingQueue<>();
上面这段代码中,blockingQueue 的容量将设置为 Integer.MAX_VALUE 。
应用场景
多用于任务队列,单线程发布任务,任务满了就停止等待阻塞,当任务被完成消费少了又开始负责发布任务。
我们来看一个例子:
- package com.niuh.queue.linked;
- import org.apache.commons.lang.RandomStringUtils;
- import java.util.concurrent.CountDownLatch;
- import java.util.concurrent.ExecutorService;
- import java.util.concurrent.Executors;
- import java.util.concurrent.LinkedBlockingQueue;
- import java.util.concurrent.TimeUnit;
- import java.util.concurrent.atomic.AtomicLong;
- public class TestLinkedBlockingQueue {
- private static LinkedBlockingQueue<String> queue = new LinkedBlockingQueue<String>();
- // 线程控制开关
- private final CountDownLatch latch = new CountDownLatch(1);
- // 线程池
- private final ExecutorService pool;
- // AtomicLong 计数 生产数量
- private final AtomicLong output = new AtomicLong(0);
- // AtomicLong 计数 销售数量
- private final AtomicLong sales = new AtomicLong(0);
- // 是否停止线程
- private final boolean clear;
- public TestLinkedBlockingQueue(boolean clear) {
- this.pool = Executors.newCachedThreadPool();
- this.clear = clear;
- }
- public void service() throws InterruptedException {
- Consumer a = new Consumer(queue, sales, latch, clear);
- pool.submit(a);
- Producer w = new Producer(queue, output, latch);
- pool.submit(w);
- latch.countDown();
- }
- public static void main(String[] args) {
- TestLinkedBlockingQueue t = new TestLinkedBlockingQueue(false);
- try {
- t.service();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- /**
- * 消费者(销售产品)
- */
- class Consumer implements Runnable {
- private final LinkedBlockingQueue<String> queue;
- private final AtomicLong sales;
- private final CountDownLatch latch;
- private final boolean clear;
- public Consumer(LinkedBlockingQueue<String> queue, AtomicLong sales, CountDownLatch latch, boolean clear) {
- this.queue = queue;
- this.sales = sales;
- this.latch = latch;
- this.clear = clear;
- }
- public void run() {
- try {
- latch.await(); // 放闸之前老实的等待着
- for (; ; ) {
- sale();
- Thread.sleep(500);
- }
- } catch (InterruptedException e) {
- if (clear) { // 响应中断请求后,如果有要求则销售完队列的产品后再终止线程
- cleanWarehouse();
- } else {
- System.out.println("Seller Thread will be interrupted...");
- }
- }
- }
- public void sale() {
- System.out.println("==取take=");
- try {
- String item = queue.poll(50, TimeUnit.MILLISECONDS);
- System.out.println(item);
- if (item != null) {
- sales.incrementAndGet(); // 可以声明long型的参数获得返回值,作为日志的参数
- }
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- /**
- * 销售完队列剩余的产品
- */
- private void cleanWarehouse() {
- try {
- while (queue.size() > 0) {
- sale();
- }
- } catch (Exception ex) {
- System.out.println("Seller Thread will be interrupted...");
- }
- }
- }
- /**
- * 生产者(生产产品)
- *
- */
- class Producer implements Runnable {
- private LinkedBlockingQueue<String> queue;
- private CountDownLatch latch;
- private AtomicLong output;
- public Producer() {
- }
- public Producer(LinkedBlockingQueue<String> queue, AtomicLong output, CountDownLatch latch) {
- this.queue = queue;
- this.latch = latch;
- this.output = output;
- }
- public void run() {
- try {
- latch.await(); // 线程等待
- for (; ; ) {
- work();
- Thread.sleep(100);
- }
- } catch (InterruptedException e) {
- System.out.println("Producer thread will be interrupted...");
- }
- }
- /**
- * 工作
- */
- public void work() {
- try {
- String product = RandomStringUtils.randomAscii(3);
- boolean success = queue.offer(product, 100, TimeUnit.MILLISECONDS);
- if (success) {
- output.incrementAndGet();// 可以声明long型的参数获得返回值,作为日志的参数
- }
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
工作原理
LinkedBlockingQueue内部由单链表实现,只能从head取元素,从tail添加元素。添加元素和获取元素都有独立的锁,也就是说LinkedBlockingQueue是读写分离的,读写操作可以并行执行。LinkedBlockingQueue采用可重入锁(ReentrantLock)来保证在并发情况下的线程安全。
向无限队列添加元素的所有操作都将永远不会阻塞,[注意这里不是说不会加锁保证线程安全],因此它可以增长到非常大的容量。
使用无限 BlockingQueue 设计生产者 - 消费者模型时最重要的是 消费者应该能够像生产者向队列添加消息一样快地消费消息。否则,内存可能会填满,然后就会得到一个 OutOfMemory 异常。
源码分析
定义
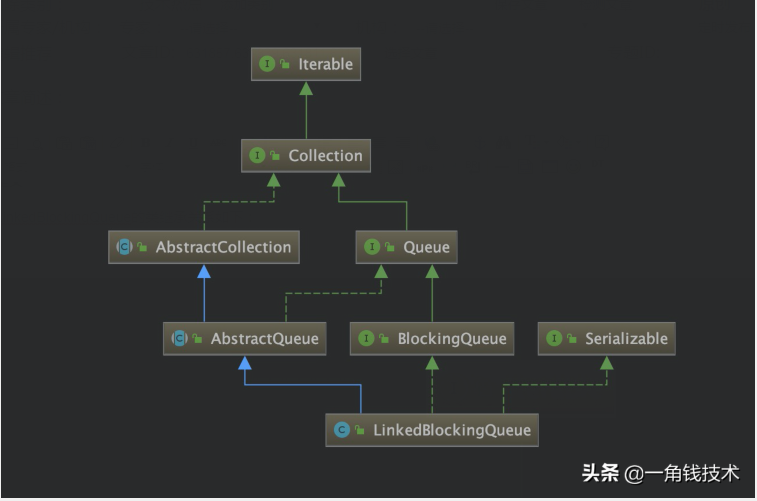
LinkedBlockingQueue的类继承关系如下:
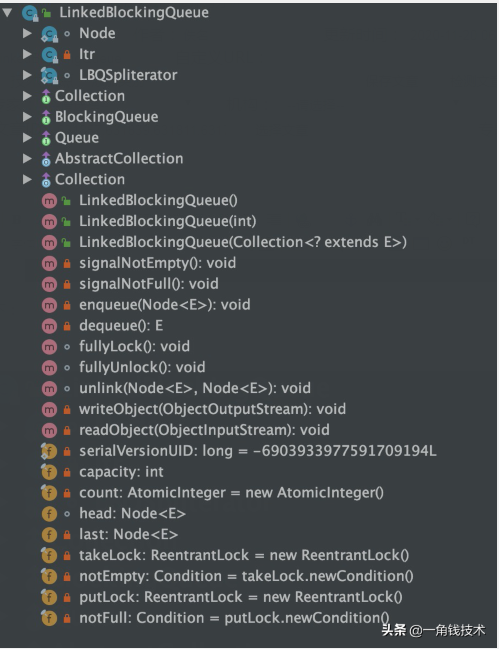
其包含的方法定义如下:
成员属性
- /**
- * 节点类,用于存储数据
- */
- static class Node<E> {
- E item;
- Node<E> next;
- Node(E x) { item = x; }
- }
- /** 阻塞队列的大小, 默认为Integer.MAX_VALUE */
- private final int capacity;
- /** 当前阻塞队列中的元素个数 */
- private final AtomicInteger count = new AtomicInteger();
- /**
- * 阻塞队列的头节点
- */
- transient Node<E> head;
- /**
- * 阻塞队列的尾节点
- */
- private transient Node<E> last;
- /** 获取并移除元素时使用的锁,如take,poll,etc */
- private final ReentrantLock takeLock = new ReentrantLock();
- /** notEmpty 条件对象,当队列没有数据时用于挂起执行删除的线程 */
- private final Condition notEmpty = takeLock.newCondition();
- /** 添加元素时使用的锁,如 put,offer,etc */
- private final ReentrantLock putLock = new ReentrantLock();
- /** notFull 条件对象,每当队列数据已满时用于挂起执行添加的线程 */
- private final Condition notFull = putLock.newCondition();
从上面的属性我们知道,每个添加到LinkedBlockingQueue队列中的数据都将被封装成Node节点,添加的链表队列中,其中head和last分别指向队列的头结点和尾结点。与ArrayBlockingQueue不同的是,LinkedBlockingQueue内部分别使用了takeLock 和 putLock 对并发进行控制,也就是说,添加和删除操作并不是互斥操作,可以同时进行,这样也就可以大大提高吞吐量。
这里如果不指定队列的容量大小,也就是使用默认的Integer.MAX_VALUE,如果存在添加速度大于删除速度时候,有可能会内存溢出,这点在使用前希望慎重考虑。
另外,LinkedBlockingQueue对每一个lock锁都提供了一个Condition用来挂起和唤醒其他线程。
构造函数
默认的构造函数和最后一个构造函数创建的队列大小都为 Integer.MAX_VALUE,只有第二个构造函数用户可以指定队列的大小。第二个构造函数最后初始化了last和head节点,让它们都指向了一个元素为null的节点。
最后一个构造函数使用了putLock来进行加锁,但是这里并不是为了多线程的竞争而加锁,只是为了放入的元素能立即对其他线程可见。
- public LinkedBlockingQueue() {
- // 默认大小为Integer.MAX_VALUE
- this(Integer.MAX_VALUE);
- }
- public LinkedBlockingQueue(int capacity) {
- if (capacity <= 0) throw new IllegalArgumentException();
- this.capacity = capacity;
- last = head = new Node<E>(null);
- }
- public LinkedBlockingQueue(Collection<? extends E> c) {
- this(Integer.MAX_VALUE);
- final ReentrantLock putLock = this.putLock;
- putLock.lock(); // Never contended, but necessary for visibility
- try {
- int n = 0;
- for (E e : c) {
- if (e == null)
- throw new NullPointerException();
- if (n == capacity)
- throw new IllegalStateException("Queue full");
- enqueue(new Node<E>(e));
- ++n;
- }
- count.set(n);
- } finally {
- putLock.unlock();
- }
- }
入队方法
LinkedBlockingQueue提供了多种入队操作的实现来满足不同情况下的需求,入队操作有如下几种:
- void put(E e);
- boolean offer(E e);
- boolean offer(E e, long timeout, TimeUnit unit)。
其中:
- offer方法有两个重载版本,只有一个参数的版本,如果队列满了就返回false,否则加入到队列中,返回true,add方法就是调用此版本的offer方法;另一个带时间参数的版本,如果队列满了则等待,可指定等待的时间,如果这期间中断了则抛出异常,如果等待超时了则返回false,否则加入到队列中返回true;
- put方法跟带时间参数的offer方法逻辑一样,不过没有等待的时间限制,会一直等待直到队列有空余位置了,再插入到队列中,返回true。
put(E e)
- public void put(E e) throws InterruptedException {
- if (e == null) throw new NullPointerException();
- int c = -1;
- Node<E> node = new Node<E>(e);
- final ReentrantLock putLock = this.putLock;
- final AtomicInteger count = this.count;
- // 获取锁中断
- putLock.lockInterruptibly();
- try {
- //判断队列是否已满,如果已满阻塞等待
- while (count.get() == capacity) {
- notFull.await();
- }
- // 把node放入队列中
- enqueue(node);
- c = count.getAndIncrement();
- // 再次判断队列是否有可用空间,如果有唤醒下一个线程进行添加操作
- if (c + 1 < capacity)
- notFull.signal();
- } finally {
- putLock.unlock();
- }
- // 如果队列中有一条数据,唤醒消费线程进行消费
- if (c == 0)
- signalNotEmpty();
- }
小结put方法来看,它总共做了以下情况的考虑:
- 队列已满,阻塞等待。
- 队列未满,创建一个node节点放入队列中,如果放完以后队列还有剩余空间,继续唤醒下一个添加线程进行添加。如果放之前队列中没有元素,放完以后要唤醒消费线程进行消费。
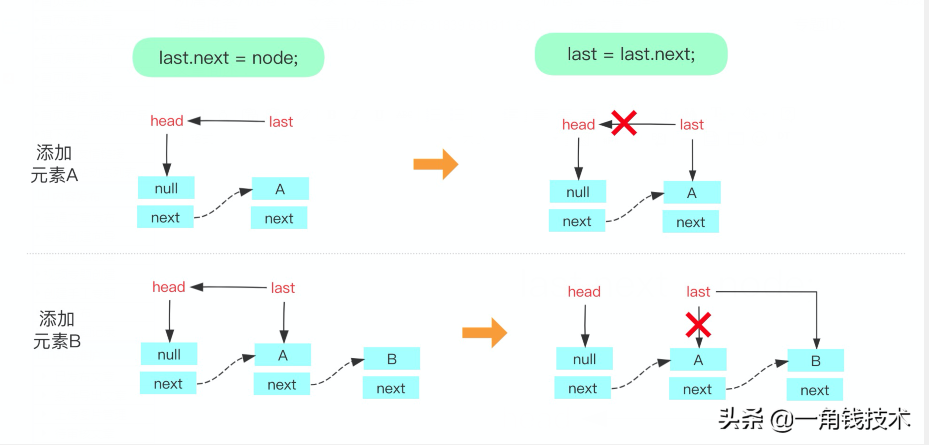
我们再看看put方法中用到的几个其他方法,先来看看 enqueue(Node node) 方法:
- private void enqueue(Node<E> node) {
- last = last.next = node;
- }
用一张图来看看往队列里依次放入元素A和元素B,如下:
接下来我们看看signalNotEmpty,顺带着看signalNotFull方法。
- private void signalNotEmpty() {
- final ReentrantLock takeLock = this.takeLock;
- takeLock.lock();
- try {
- notEmpty.signal();
- } finally {
- takeLock.unlock();
- }
- }
- private void signalNotFull() {
- final ReentrantLock putLock = this.putLock;
- putLock.lock();
- try {
- notFull.signal();
- } finally {
- putLock.unlock();
- }
- }
为什么要这么写?因为signal的时候要获取到该signal对应的Condition对象的锁才行。
offer(E e)
- public boolean offer(E e) {
- if (e == null) throw new NullPointerException();
- final AtomicInteger count = this.count;
- if (count.get() == capacity)
- return false;
- int c = -1;
- Node<E> node = new Node<E>(e);
- final ReentrantLock putLock = this.putLock;
- putLock.lock();
- try {
- // 队列有可用空间,放入node节点,判断放入元素后是否还有可用空间,
- // 如果有,唤醒下一个添加线程进行添加操作。
- if (count.get() < capacity) {
- enqueue(node);
- c = count.getAndIncrement();
- if (c + 1 < capacity)
- notFull.signal();
- }
- } finally {
- putLock.unlock();
- }
- if (c == 0)
- signalNotEmpty();
- return c >= 0;
- }
可以看到offer仅仅对put方法改动了一点点,当队列没有可用元素的时候,不同于put方法的阻塞等待,offer方法直接方法false。
offer(E e, long timeout, TimeUnit unit)
- public boolean offer(E e, long timeout, TimeUnit unit)
- throws InterruptedException {
- if (e == null) throw new NullPointerException();
- long nanos = unit.toNanos(timeout);
- int c = -1;
- final ReentrantLock putLock = this.putLock;
- final AtomicInteger count = this.count;
- putLock.lockInterruptibly();
- try {
- // 等待超时时间nanos,超时时间到了返回false
- while (count.get() == capacity) {
- if (nanos <= 0)
- return false;
- nanos = notFull.awaitNanos(nanos);
- }
- enqueue(new Node<E>(e));
- c = count.getAndIncrement();
- if (c + 1 < capacity)
- notFull.signal();
- } finally {
- putLock.unlock();
- }
- if (c == 0)
- signalNotEmpty();
- return true;
- }
该方法只是对offer方法进行了阻塞超时处理,使用了Condition的awaitNanos来进行超时等待,这里为什么要用while循环?因为awaitNanos方法是可中断的,为了防止在等待过程中线程被中断,这里使用while循环进行等待过程中中断的处理,继续等待剩下需等待的时间。
出队方法
入队列的方法说完后,我们来说说出队列的方法。LinkedBlockingQueue提供了多种出队操作的实现来满足不同情况下的需求,如下:
- E take();
- E poll();
- E poll(long timeout, TimeUnit unit);
take()
- public E take() throws InterruptedException {
- E x;
- int c = -1;
- final AtomicInteger count = this.count;
- final ReentrantLock takeLock = this.takeLock;
- takeLock.lockInterruptibly();
- try {
- // 队列为空,阻塞等待
- while (count.get() == 0) {
- notEmpty.await();
- }
- x = dequeue();
- c = count.getAndDecrement();
- // 队列中还有元素,唤醒下一个消费线程进行消费
- if (c > 1)
- notEmpty.signal();
- } finally {
- takeLock.unlock();
- }
- // 移除元素之前队列是满的,唤醒生产线程进行添加元素
- if (c == capacity)
- signalNotFull();
- return x;
- }
take方法看起来就是put方法的逆向操作,它总共做了以下情况的考虑:
- 队列为空,阻塞等待
- 队列不为空,从对首获取并移除一个元素,如果消费后还有元素在队列中,继续唤醒下一个消费线程进行元素移除。如果放之前队列是满元素的情况,移除完后需要唤醒生产线程进行添加元素。
我们来看看dequeue方法
- private E dequeue() {
- // 获取到head节点
- Node<E> h = head;
- // 获取到head节点指向的下一个节点
- Node<E> first = h.next;
- // head节点原来指向的节点的next指向自己,等待下次gc回收
- h.next = h; // help GC
- // head节点指向新的节点
- head = first;
- // 获取到新的head节点的item值
- E x = first.item;
- // 新head节点的item值设置为null
- first.item = null;
- return x;
- }
我们结合注释和图来看一下链表算法:
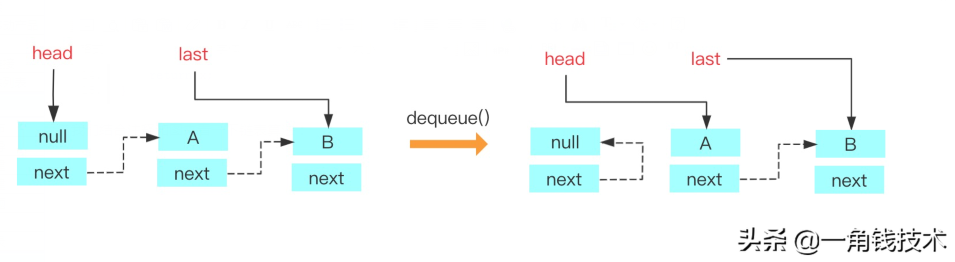
其实这个写法看起来很绕,我们其实也可以这么写:
- private E dequeue() {
- // 获取到head节点
- Node<E> h = head;
- // 获取到head节点指向的下一个节点,也就是节点A
- Node<E> first = h.next;
- // 获取到下下个节点,也就是节点B
- Node<E> next = first.next;
- // head的next指向下下个节点,也就是图中的B节点
- h.next = next;
- // 得到节点A的值
- E x = first.item;
- first.item = null; // help GC
- first.next = first; // help GC
- return x;
- }
poll()
- public E poll() {
- final AtomicInteger count = this.count;
- if (count.get() == 0)
- return null;
- E x = null;
- int c = -1;
- final ReentrantLock takeLock = this.takeLock;
- takeLock.lock();
- try {
- if (count.get() > 0) {
- x = dequeue();
- c = count.getAndDecrement();
- if (c > 1)
- notEmpty.signal();
- }
- } finally {
- takeLock.unlock();
- }
- if (c == capacity)
- signalNotFull();
- return x;
- }
poll方法去除了take方法中元素为空后阻塞等待这一步骤,这里也就不详细说了。同理,poll(long timeout, TimeUnit unit)也和offer(E e, long timeout, TimeUnit unit)一样,利用了Condition的awaitNanos方法来进行阻塞等待直至超时。这里就不列出来说了。
获取元素方法
- public E peek() {
- if (count.get() == 0)
- return null;
- final ReentrantLock takeLock = this.takeLock;
- takeLock.lock();
- try {
- Node<E> first = head.next;
- if (first == null)
- return null;
- else
- return first.item;
- } finally {
- takeLock.unlock();
- }
- }
加锁后,获取到head节点的next节点,如果为空返回null,如果不为空,返回next节点的item值。
删除元素方法
- public boolean remove(Object o) {
- if (o == null) return false;
- // 两个lock全部上锁
- fullyLock();
- try {
- // 从head开始遍历元素,直到最后一个元素
- for (Node<E> trail = head, p = trail.next;
- p != null;
- trail = p, p = p.next) {
- // 如果找到相等的元素,调用unlink方法删除元素
- if (o.equals(p.item)) {
- unlink(p, trail);
- return true;
- }
- }
- return false;
- } finally {
- // 两个lock全部解锁
- fullyUnlock();
- }
- }
- void fullyLock() {
- putLock.lock();
- takeLock.lock();
- }
- void fullyUnlock() {
- takeLock.unlock();
- putLock.unlock();
- }
因为remove方法使用两个锁全部上锁,所以其他操作都需要等待它完成,而该方法需要从head节点遍历到尾节点,所以时间复杂度为O(n)。我们来看看unlink方法。
- void unlink(Node<E> p, Node<E> trail) {
- // p的元素置为null
- p.item = null;
- // p的前一个节点的next指向p的next,也就是把p从链表中去除了
- trail.next = p.next;
- // 如果last指向p,删除p后让last指向trail
- if (last == p)
- last = trail;
- // 如果删除之前元素是满的,删除之后就有空间了,唤醒生产线程放入元素
- if (count.getAndDecrement() == capacity)
- notFull.signal();
- }
总结
LinkedBlockingQueue是一个阻塞队列,内部由两个ReentrantLock来实现出入队列的线程安全,由各自的Condition对象的await和signal来实现等待和唤醒功能。它和ArrayBlockingQueue的不同点在于:
- 队列大小有所不同,ArrayBlockingQueue是有界的初始化必须指定大小,而LinkedBlockingQueue可以是有界的也可以是无界的(Integer.MAX_VALUE),对于后者而言,当添加速度大于移除速度时,在无界的情况下,可能会造成内存溢出等问题。
- 数据存储容器不同,ArrayBlockingQueue采用的是数组作为数据存储容器,而LinkedBlockingQueue采用的则是以Node节点作为连接对象的链表。
- 由于ArrayBlockingQueue采用的是数组的存储容器,因此在插入或删除元素时不会产生或销毁任何额外的对象实例,而LinkedBlockingQueue则会生成一个额外的Node对象。这可能在长时间内需要高效并发地处理大批量数据的时,对于GC可能存在较大影响。
- 两者的实现队列添加或移除的锁不一样,ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReenterLock锁,而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能大大提高队列的吞吐量,也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
PS:以上代码提交在 Github :
https://github.com/Niuh-Study/niuh-juc-final.git
文章持续更新,可以公众号搜一搜「 一角钱技术 」第一时间阅读, 本文 GitHub org_hejianhui/JavaStudy 已经收录,欢迎 Star。























