大家好,今天和大家聊一个算法工程师的职场日常——模型翻车。
我们都知道算法工程师的工作重点就是模型训练,很多人每天的工作就是做特征、调参数然后训练模型。所以对于算法工程师而言,最经常遇到的问题就是模型翻车了,好容易训练出来的模型结果效果还很差。很多刚入门的小白遇上这种情况都会一筹莫展,不知道究竟是哪里出了问题。
所以今天就和大家简单分享一下,我个人总结出来的一点简单经验,遇到这种情况的时候,我们应该怎么处理。
检查样本
整个模型训练结果不好的排查过程可以遵守一个由大到小,由浅入深的顺序。也就是说我们先从整体上、宏观上进行排查,再去检查一些细节的内容。
很多小白可能会有点愣头青,上来就去检查特征的细节,而忽略了整体的检查。导致后来花费了很多时间,才发现原来是样本的比例不对或者是样本的数量不对这种很容易发现的问题。不仅会浪费时间,而且给老板以及其他人的观感不好。
所以我们先从整体入手,先检查一下正负样本的比例,检查一下训练样本的数量。和往常的实验相比有没有什么变化,这种检查往往比较简单,可能几分钟就能有一个结果。如果发现了问题最好,没发现问题也不亏,至少也算是排除了一部分原因。
检查完了样本的比例以及数量之后,我们接下来可以检查一下特征的分布,看看是不是新做的特征有一些问题。这里面可能出现的问题就很多了,比如如果大部分特征是空的,那有两种情况。一种是做特征的代码有问题,可能藏着bug。还有一种是这个特征本身就很稀疏,只有少部分样本才有值。根据我的经验,如果特征过于稀疏,其实效果也是很差的,甚至可能会起反效果,加了还不如不加。
另外一种可能出现的问题就是特征的值域分布很不均匀,比如80%的特征小于10,剩下的20%最多可以到100w。这样分布极度不平衡的特征也会拉垮模型的效果,比较好的方式对它进行分段,做成分桶特征。一般情况下特征的问题很容易通过查看分布的方法调查出来。
查看训练曲线
很多新手评判模型的标准就是最后的一个结果,比如AUC或者是准确率,而忽略了模型在整个训练过程当中的变化。这其实也不是一个很好的习惯,会丢失很多信息,也会忽略很多情况。
比较推荐的就是要习惯使用tensorboard来查看模型训练的过程,tensorboard基本上现在主流的深度学习框架都有。通过它我们可以看到一些关键指标在训练过程当中的变化,它最主要的功能就是帮助我们发现过拟合或者是欠拟合的情况。
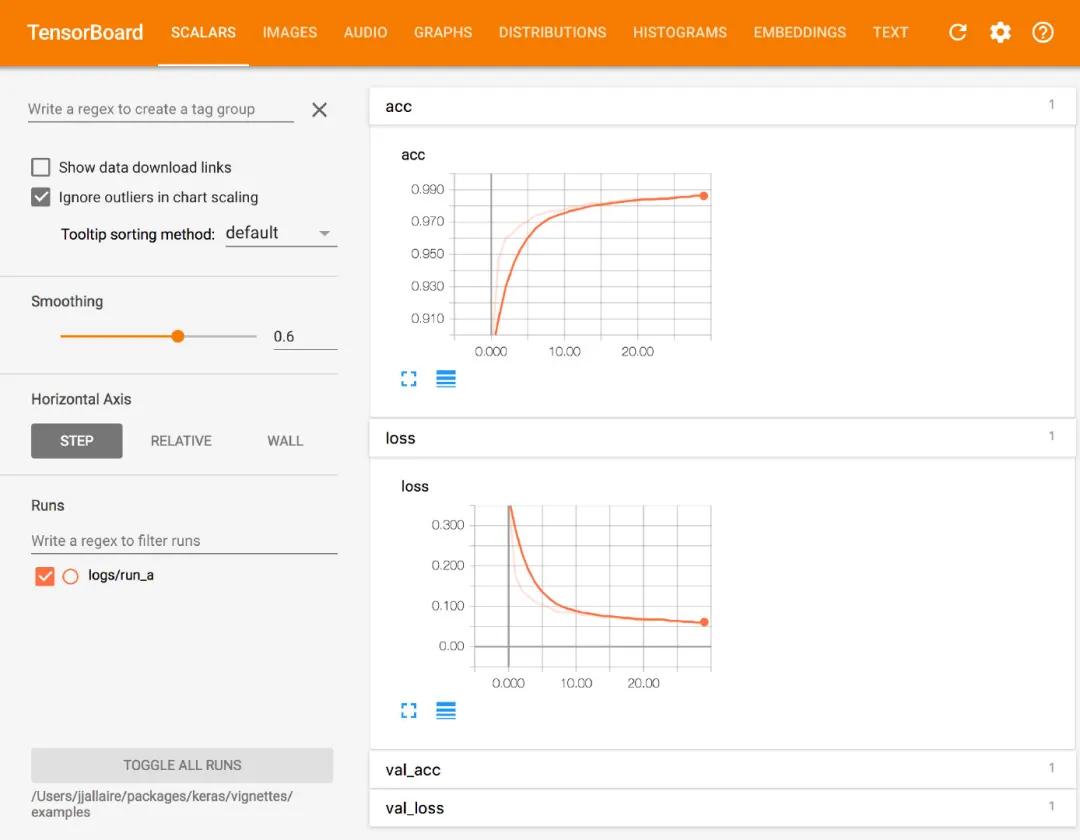
我们经常遇到的一种情况就是在原本的特征集当中,模型没有任何问题,但是我们一旦加入了一些新的特征之后,效果就开始拉垮。我们查看日志发现模型训练结束之前的这一段时间里AUC或者是其他指标还是在上涨的,就误以为没有问题。其实很有可能模型在中途陷入过过拟合当中,只是由于训练时间比较长,所以被忽视了。
很多人经常吃这个亏,尤其是新手。浪费了很多时间没有发现问题,其实打开tensorboard一看就知道,模型中途过拟合或者是欠拟合了,那么我们针对性地就可以采取一些措施进行补救。
参数检查
除了上面两者之外,还有一个排查的点就是参数。
这里的参数并不只局限于模型的训练参数,比如学习率、迭代次数、batch_size等等。也包含一些模型本身的参数,像是embedding初始化的方差,embedding的size等等。
举个简单的例子,很多人实现的embedding的初始化用的是默认初始化,默认的方式方差是1。这个方差对于很多场景来说其实是有些偏大了,尤其是一些深度比较大的神经网络,很容易出现梯度爆炸,很多时候我们把它调到0.001之后,效果往往都会有所提升。
虽然说模型的结构才是主体,参数只是辅助的,但这并不表示参数不会影响模型的效果。相反,有的时候影响还不小,我们不能忽视。当然要做到这一点,我们不仅需要知道每一个参数对应的意义,也需要了解模型的结构,以及模型运行的原理,这样才能对参数起到的效果和意义有所推测。不然的话,只是生搬硬套显然也是不行的。
场景思考
上面提到的三点都还算是比较明显的,接下来和大家聊聊一点隐藏得比较深的,这也是最考验一个算法工程师功底的。
很多时候在某一个场景上效果很好的模型,换了一个场景效果就不好了,或者是一些很管用的特征突然就不管用了。这也许并不是因为有隐藏的bug,可能只是单纯地模型水土不服,对于当前的场景不太适合。
拿推荐场景举个例子,比如在首页的推荐当中,由于我们没有任何额外输入的信息,只能根据用户历史的行为偏好来进行推荐。这个时候我们就会额外地关注用户历史行为和当前商品的信息的交叉和重叠的部分,着重把这些信息做成特征。但如果同样的特征迁移到商品详情页下方的猜你喜欢当中去,可能就不是非常合适。
原因也很简单,详情页下方的猜你喜欢召回的商品基本上都是同一类别甚至是同款商品,这就意味着这些商品本身的信息当中有大部分都是一样或者是高度相似的。既然这些信息是高度相似的,模型很难从这些差异化很小的特征当中学到关键信息,那么自然也就很难获得同样的效果。这并非是特征或者是模型出了什么问题,可能就是单纯地场景不合适。
对于场景与特征以及模型之间的理解和思考才是最考验一个算法工程师能力和经验的部分,新人的注意力往往关注不到这个方面,更多地还是局限在特征和模型本身。有的时候,我们的思维不能顺着一条线毫无阻碍地往下走,也需要经常停下来反思一下,我这么思考有没有忽略什么问题。
本文转载自微信公众号「TechFlow」,可以通过以下二维码关注。转载本文请联系TechFlow公众号。