













在自动化系统中,深度学习和计算机视觉已经疯狂地流行起来,无处不在。计算机视觉领域在过去十年中发展迅速,尤其是是障碍物检测方面。
障碍物检测算法,如YOLO或RetinaNet,提供2D的标注框,该标注框指明了障碍物在图像中的位置。
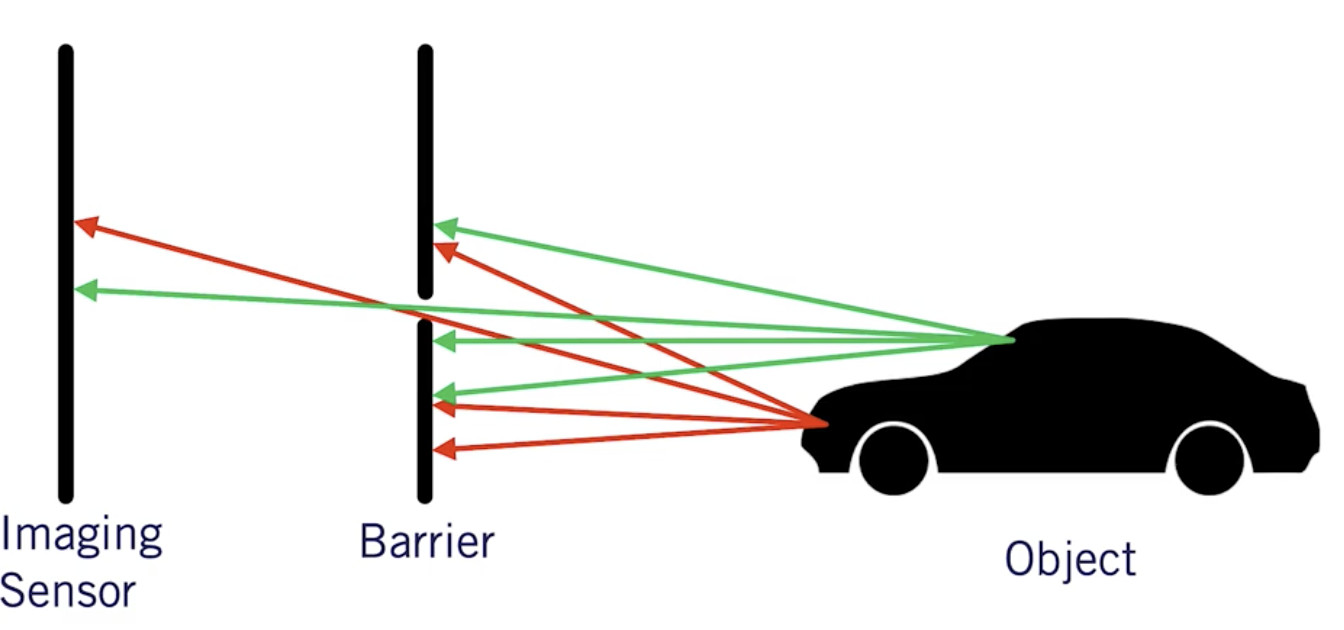
为了获取每个障碍物的距离,工程师将相机与激光雷达(光探测和测距)传感器融合,使用激光返回深度信息。利用传感器融合技术将计算机视觉和激光雷达的输出融合在一起。
使用激光雷达这种方式存在价格昂贵的问题。而对此,工程师使用的一个有用的技巧是:对齐两个像机,并使用几何原理来计算每个障碍物的距离。我们称这种新设置为 伪激光雷达。

单目视觉和立体视觉
伪激光雷达利用几何原理构造深度图,并将其与物体探测相结合,以获得三维的距离。
如何利用立体视觉实现距离估计?
以下5步伪代码用于获取距离:
- 校准2台照相机(内部和外部校准)
- 创建极线方案
- 先建立视差图,再建立深度图
然后,深度图将与障碍检测算法结合在一起,我们将估算边界框像素的深度。本文结尾处有更多内容。
开始吧!
1.内部和外部校准
每个摄像机都需要校准。校准意味着将具有[X,Y,Z]坐标的3D点(世界上)转换为具有[X,Y]坐标的2D像素。
相机型号
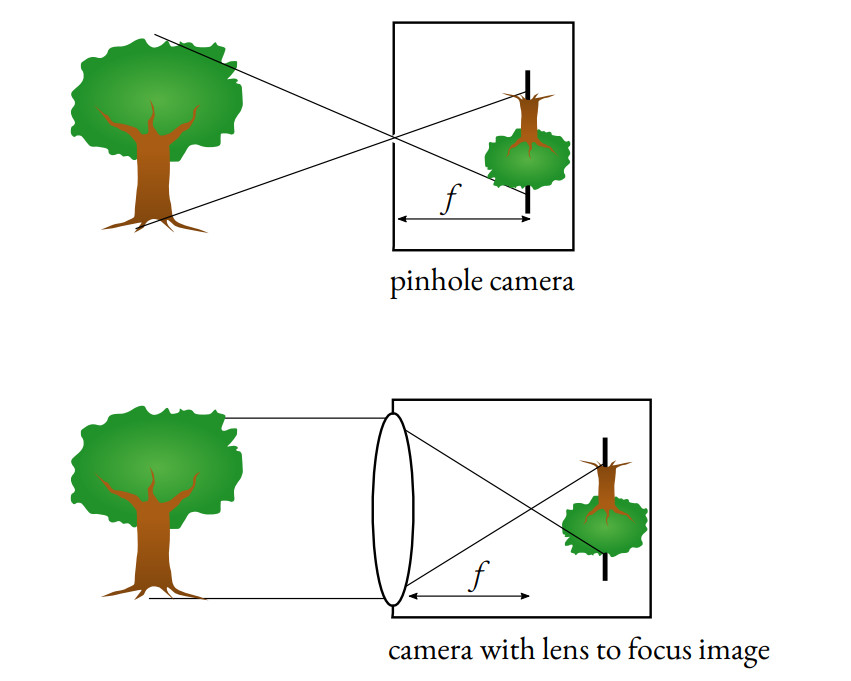
当今的相机使用针孔相机模型。
这个想法是使用针孔让少量光线穿过相机,从而获得清晰的图像。
如果图像中间没有障碍物,那么每条光线都会通过,图像会变得模糊。它还使我们能够确定用于变焦和更好清晰度的焦距f。
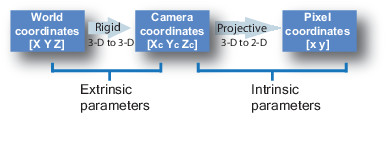
要校准相机,我们需要将世界坐标转换为通过相机坐标的像素坐标。
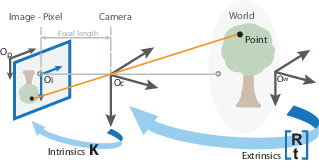
相机校准过程
从世界坐标到摄像机坐标的转换称为外部校准。外在参数称为R(旋转矩阵)和T(平移矩阵)。
从相机坐标到像素坐标的转换称为固有校准。它需要相机的内部值,例如焦距,光学中心等。
固有参数是我们称为K的矩阵。
校准
过相机校准可以找到K矩阵。
通常,我们使用棋盘格和自动算法来执行它。 当我们这样做时,我们告诉算法棋盘上的一个点(例如:0,0,0)对应于图像中的一个像素(例如:545、343)。

校准示例
为此,我们必须使用相机拍摄棋盘格的图像,并且在经过一些图像和某些点之后,校准算法将通过最小化最小二乘方损失来确定相机的校准矩阵。
通常,必须进行校准才能消除图像失真。 针孔摄像头模型包括变形,即“ GoPro效果”。 为了获得校正的图像,必须进行校准。 变形可以是径向的或切向的。 校准有助于使图像不失真。

图像校准
以下是相机校准返回的矩阵:
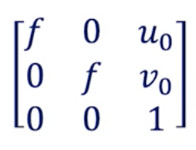
f是焦距-(u₀,v₀)是光学中心:这些是固有参数。
每一个计算机视觉工程师都必须了解和掌握摄像机的标定。这是最基本、最重要的要求。我们习惯于在线处理图像,从不接触硬件,这是个错误。
-尝试运行OpenCV进行摄像机校准。
同类坐标
在相机校准过程中,我们有两个公式可以将世界上的点O设为像素空间:
world到相机的转换
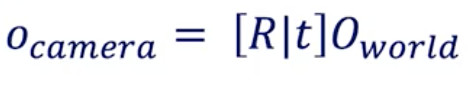
外在校准公式
相机到图像的转换
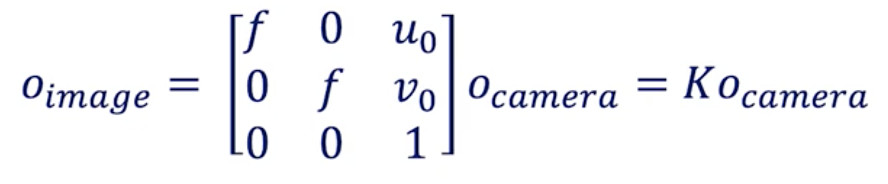
内部校准公式
当您进行数学运算时,您将得出以下等式:
world到图像的转换

如果您查看矩阵尺寸,则不匹配。
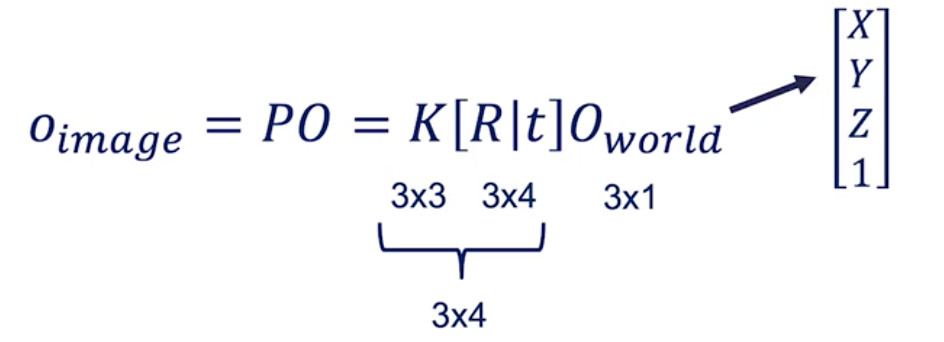
因此,我们需要将O_world从[X Y Z]修改为[X Y Z 1]。
该“ 1”称为齐次坐标。
2.极线几何--立体视觉
立体视觉是基于两张图像来寻找深度。
我们的眼睛就像两个相机。因为它们从不同的角度看同一幅图像,它们可以比对两种视角之间的差异,并计算出距离估计。
下面是立体相机设置的示例。你会在大多数自动驾驶汽车上发现类似的东西。

立体相机如何估算深度
假设你有两个相机,一左一右。这两个相机在相同的Y轴和Z轴上对齐。基本上,唯一的区别就是它们X值不一样。
现在,看看下面的描述。
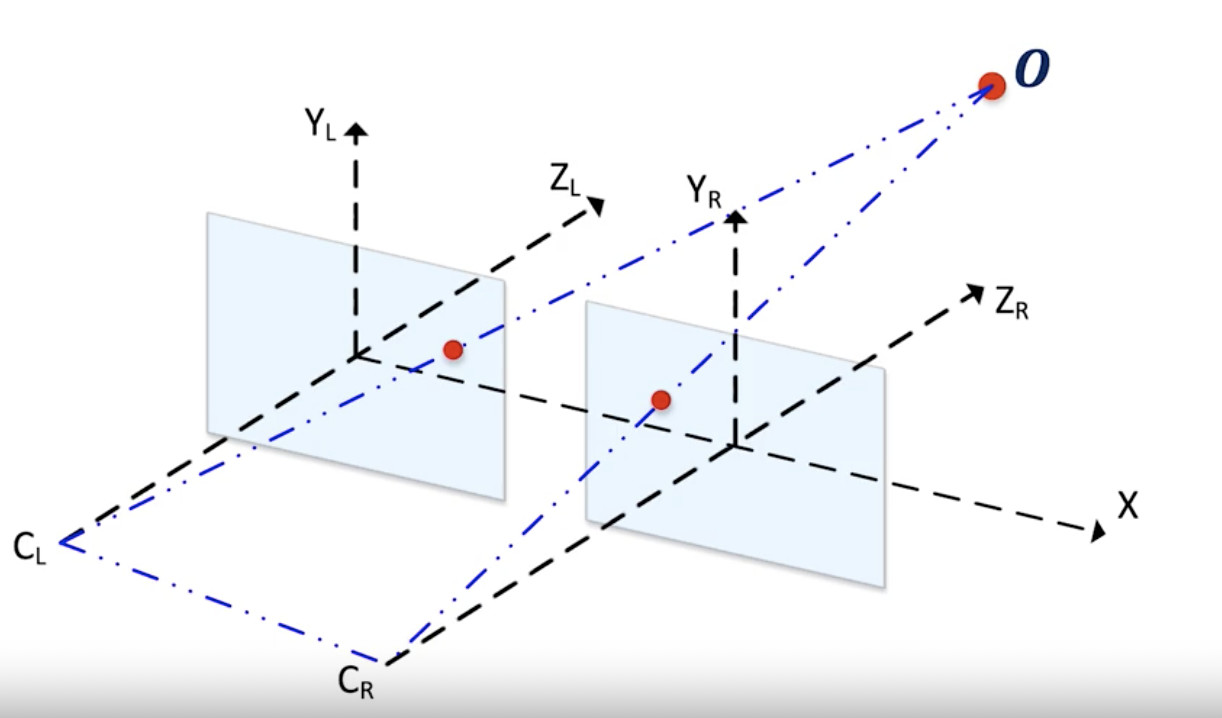
立体相机简图
我们的目标是估算出O点(代表图像中的任何像素)的Z值,即深度距离。
- X 为对齐轴;
- Y 为高度;
- Z 为深度;
两个蓝色平面对应于来自两个相机的图像。
现在从鸟瞰的角度来考虑这个问题。
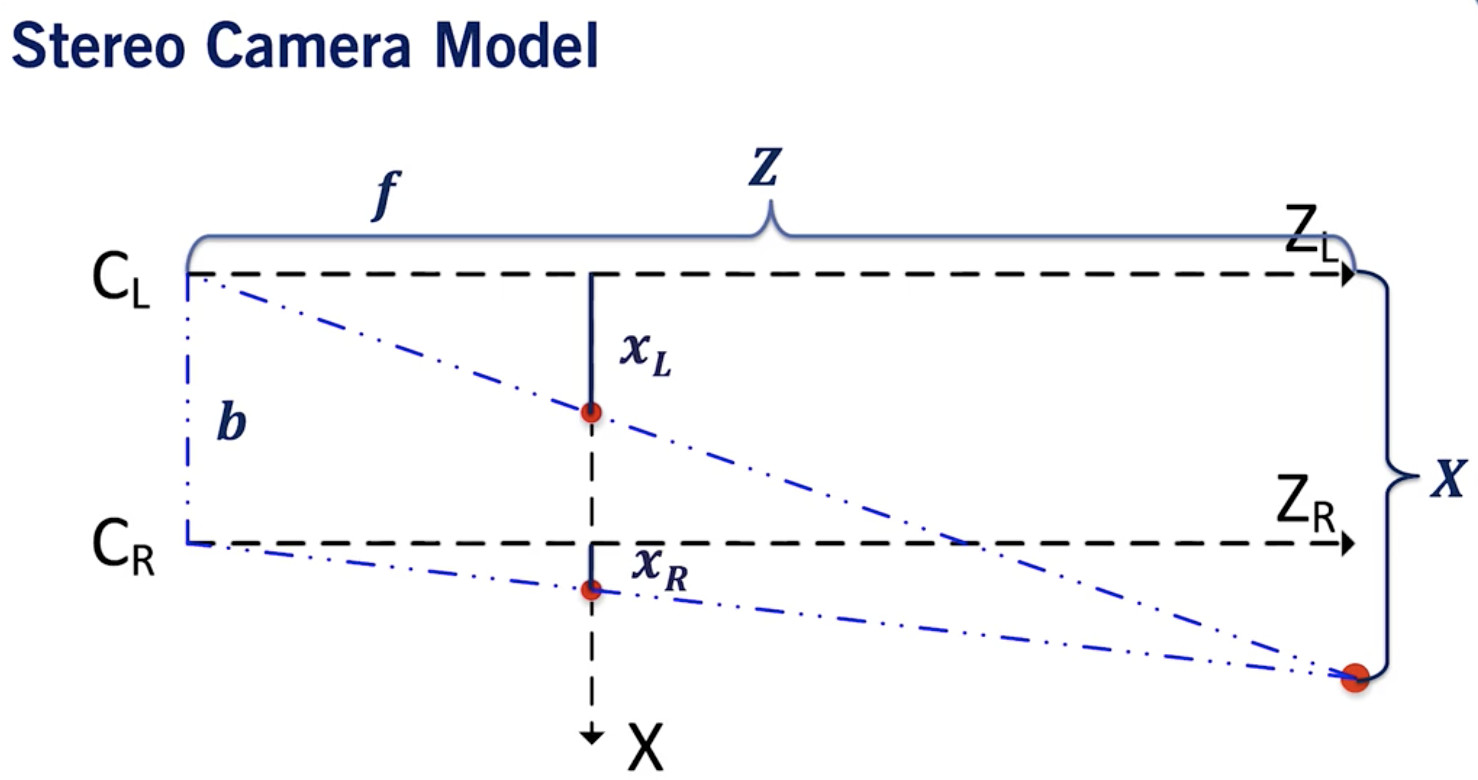
立体相机鸟瞰图说明:
- xL 对应于左相机中的光心,xR对应于右相机中的光心。
- b 是基线,它是两个相机之间的距离。
如果你运用泰勒斯定理,你会发现我们可以得到两个方程
对于左边相机:
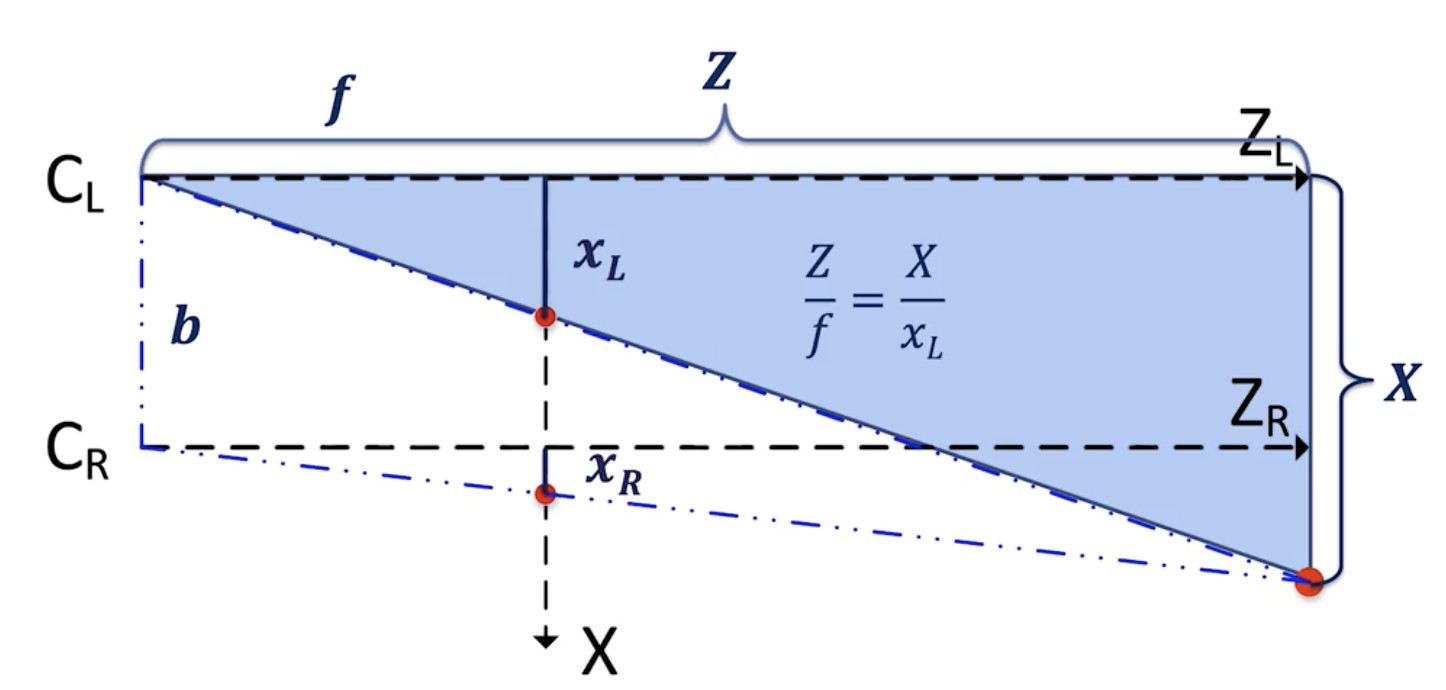
左相机方程
? 我们得到 Z = X*f / xL.
- 对于右边相机:
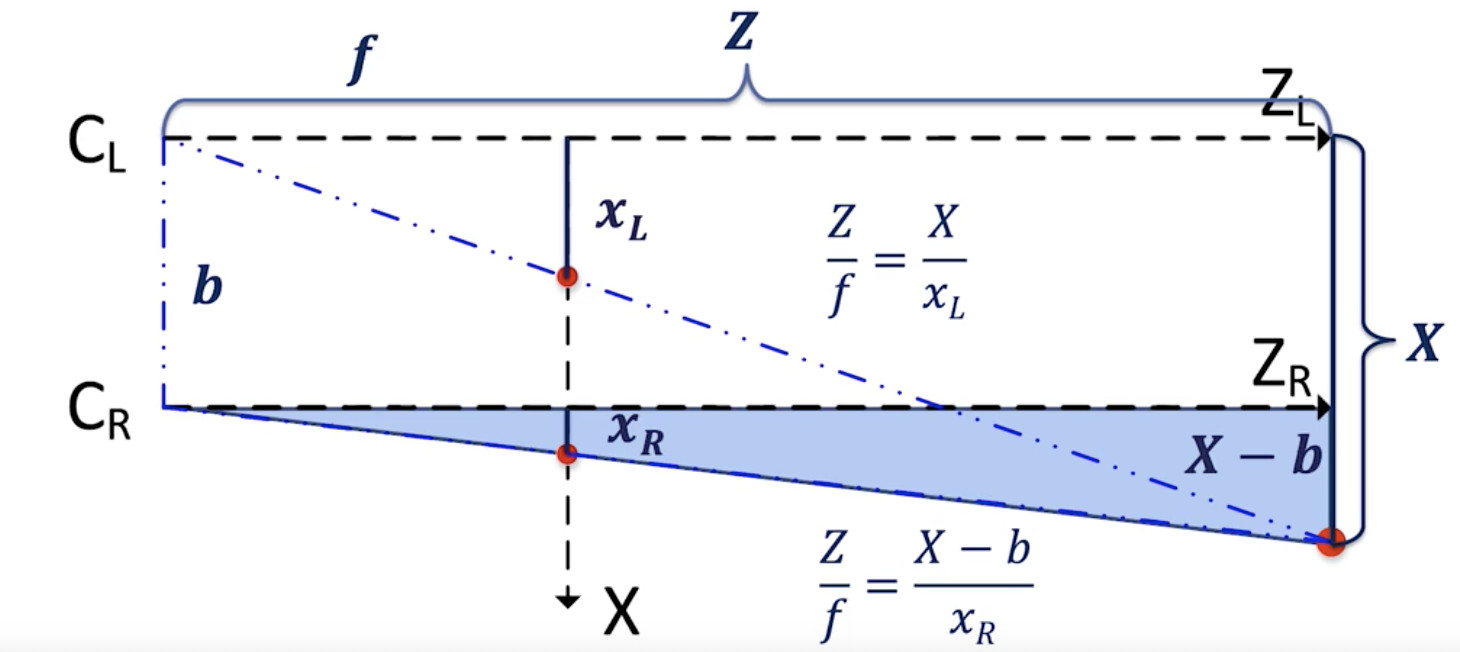
右相机方程:
- ? 我们获得 Z = (X — b)*f/xR.
放在一起,我们可以找到正确的视差 d =xL -- xR和目标正确的 XYZ 坐标。
3. 视差与深度图
视差是什么?视差是一个三维点从两个不同的相机角度在图像中位置的差异。
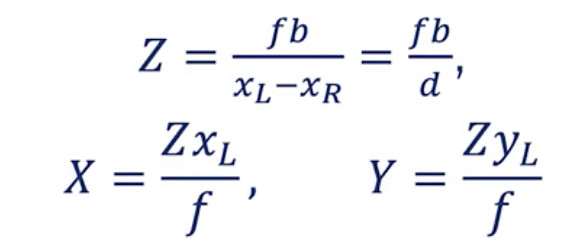
立体视觉公式
? 由立体视觉我们可以估计任何物体的深度。假设我们做了正确的矩阵校准。它甚至能够计算一个深度映射或者视差映射。

视差图
为什么是“基线几何”?
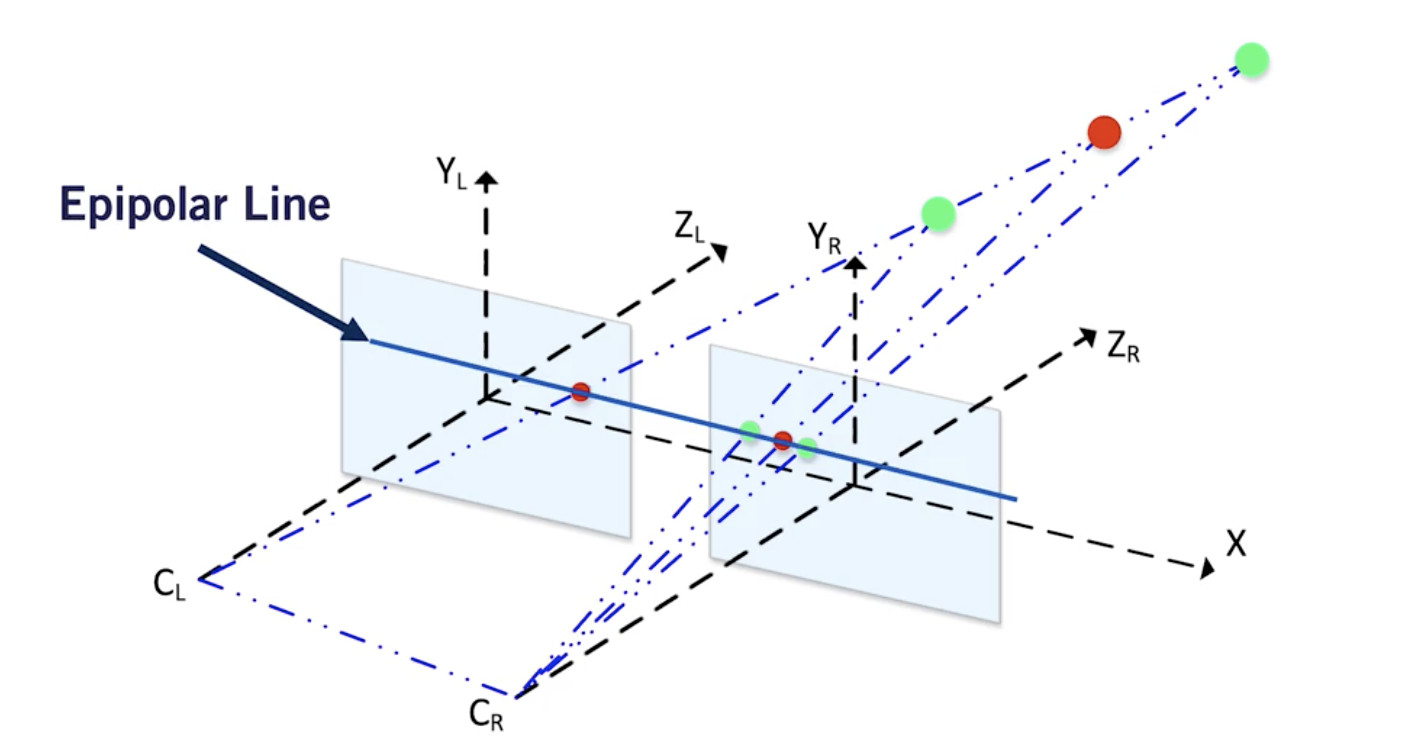
要计算视差,我们必须从左图像中找到每个像素,并将其与右图像中的每个像素进行匹配。 这称为立体对应问题。
为了解决这个问题--
- 现在在左边的图像中取一个像素
- 要在右边的图像中找到这个像素,只需在基线上搜索它。没有必要进行2D搜索,点应该位于这条线上,搜索范围缩小到 1D。
基线
这是因为两个相机是沿着同一轴对齐的。
以下是基线搜索的工作原理:

应用:建立伪激光雷达
现在,是时候将这些应用到真实世界的场景中,看看我们如何用立体视觉来估计物体的深度。
考虑两张图片--
立体视觉
每一幅图像都有外部参数 R 和 t,事先通过校准确定(步骤1)。
视差
对于每一幅图像,我们可以计算相对于另一幅图像的视差图。我们将做如下操作:
- 确定两幅图像之间的视差。
- 投影矩阵分解成相机的内在矩阵 K和外在矩阵 R,t。
- 利用我们在前面两个步骤中收集到的数据估算深度。
我们将获得左右图像的视差图。
为了帮助您更好地理解差异的含义,我在 Stack Overflow 上找到了一个很棒的解释。
视差图是指一对立体图像之间的明显像素差或运动。
要体验这一点,试着闭上你的一只眼睛,迅速闭上,同时睁开另一只。离你很近的物体看起来会跳跃一段很长的距离,而离你很远的物体几乎不会移动。这个运动就是视差。在一对来自立体摄像机的图像中,你可以测量每个点的视运动像素,并根据测量结果制作出一个强度图像。

从视差到深度图
? 我们有两个视差图,这基本上告诉我们,两幅图像之间的像素位移是多少。
对于每个摄像机,都有一个投影矩阵 P_left 和 P_right。为了估计深度,我们需要估计K, R 和 t。

世界坐标系到相机坐标系的转换一个名为
cv2.decomposeProjectionMatrix()的OpenCV函数可以做到这一点,并从 P 中得到 K、R 和 t;对于每个相机,现在是时候生成深度图了。深度图将使用其他图像和视差图告诉我们图像中每个像素的距离。
这个过程如下:
- 从矩阵 K 获得焦距 f;
- 使用转换向量 t 中的相应值来计算基线 ?;
- 使用之前的公式和视差图 d 计算图像的深度图;

立体视觉公式
我们对每个像素进行计算。
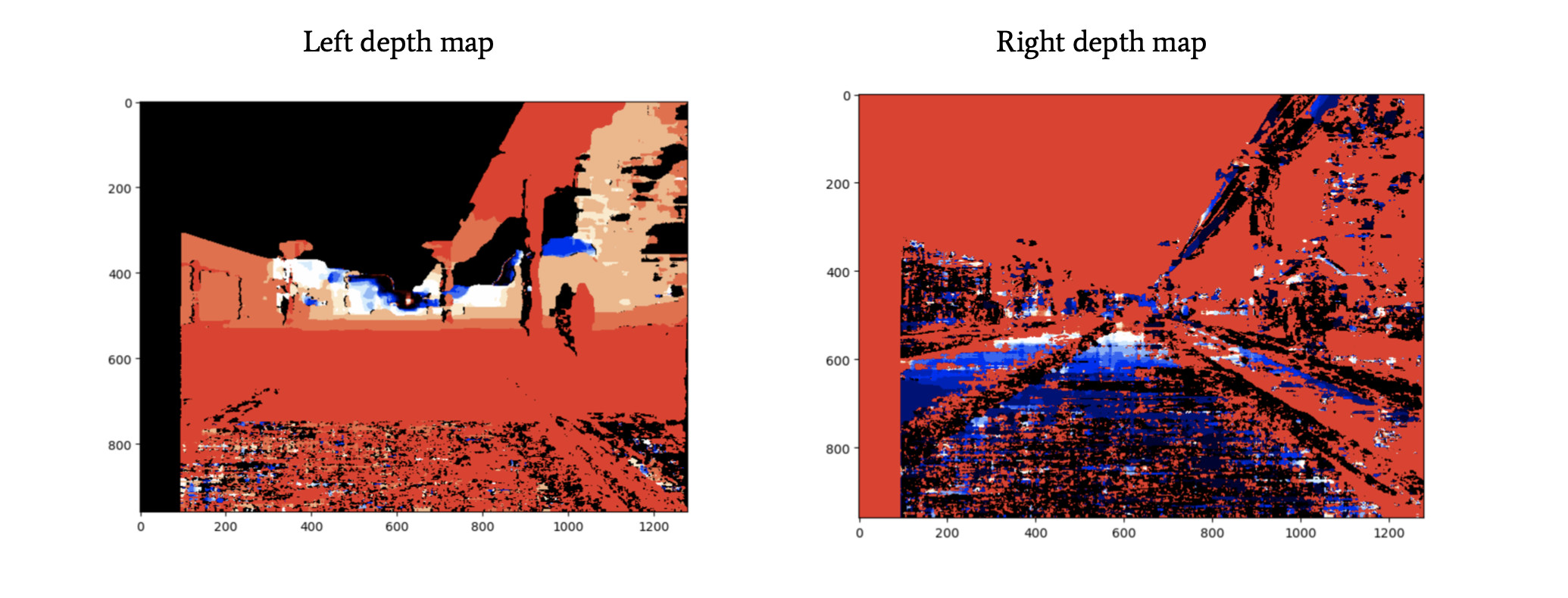
估计障碍物的深度
针对每个相机,我们都有一个深度图! 现在,假设我们将其与障碍检测算法(例如YOLO)结合在一起。 对于每个障碍,这种算法都会返回带有4个数字的边界框:[x1; y1; x2; y2]。 这些数字表示框的左上角和右下角的坐标。
例如,我们可以在左边的图像上运行这个算法,然后使用左边的深度图。
现在,在这个边界框中,我们可以取最近的点。我们知道它,因为我们知道图像中每个点的距离。边界框中的第一个点是我们到障碍物的距离。

真不可思议!我们刚刚构建了伪激光雷达!
借助立体视觉,我们不仅知道图像中的障碍物,而且知道它们与我们的距离! 这个障碍距离我们28.927米!
立体视觉是一种使用简单的几何图形和一个额外的摄像机将2D障碍物检测转换为3D障碍物检测的技术。如今,大多数新兴的edge平台都考虑了立体视觉,比如新的OpenCV AI Kit或对Raspberry和Nvidia Jetson卡的集成。
在成本方面,与使用LiDAR相比,它保持相对便宜,并且仍具有出色的性能。我们称它为伪激光雷达,因为它可以取代激光雷达的功能。检测障碍物,对障碍物进行分类,并在3D中进行定位。
本文转自雷锋网,如需转载请至雷锋网官网申请授权。













