












本文转载自公众号“读芯术”(ID:AI_Discovery)
从驾驶汽车到识别语音+翻译,机器学习通过软件预测变幻莫测的现实世界,正在人工智能领域掀起一场风暴。
所以,什么是机器学习?
机器学习是教计算机系统使用反馈的旧数据进行预测的过程,基本上是训练计算机根据过去的数据预测未来的数据。这些预测可以很简单,例如鉴定照片中的动物是猫还是狗,难度也可以递进至对语音准确识别来生成网站字幕或运行视频或音乐之类的事情。
机器学习种类
机器学习大致分为两大类:监督学习和无监督学习。
监督学习是用示例教学机器的方法。这些机器接受了大量数据的训练,从而学会识别图案,并可以根据训练数据来识别和区分数据。
而无监督学习是使用算法来识别数据集的模式,其中的数据点既未分类也未标记。算法从数据集中提取有用的信息或特征来分析其底层结构,并依此对数据进行分类。
来看看怎样使用监督学习来构建机器学习模型。
第一步:熟悉数据
任何机器学习项目的第一步都是熟悉数据。对此可以使用Pandas库。Pandas是数据科学家探索和处理数据的主要工具。
Pandas库中最重要的是DataFrame。DataFrame相当于保存数据的表,类似SQL数据库中的表。Pandas有处理DataFrame中数据的强大方法。拿加利福尼亚房价数据举例。(文件路径:../input/california-housing-prices/housing.csv)使用以下命令加载和浏览数据:
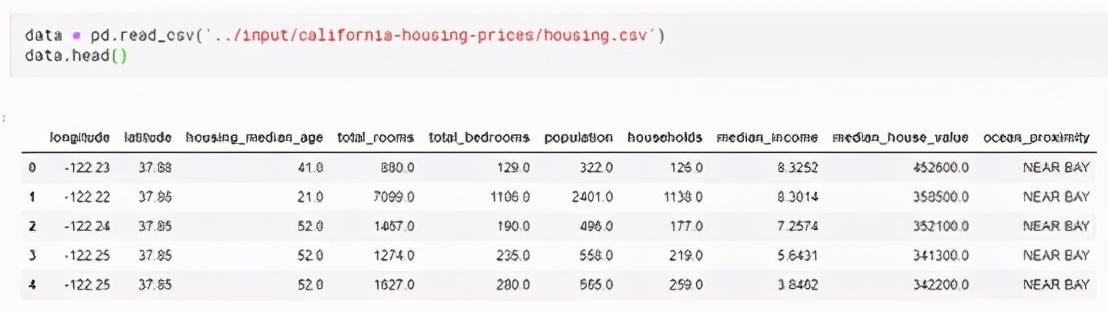
第二步:选择建模数据
研究DataFrame的数据后会发现它有10列,其中有9列是数字数据,“Ocean proximity”一列有字符串类型数据。我们只用数字数据就可以构建任何模型,因此可以直接删掉“Ocean proximity”列。
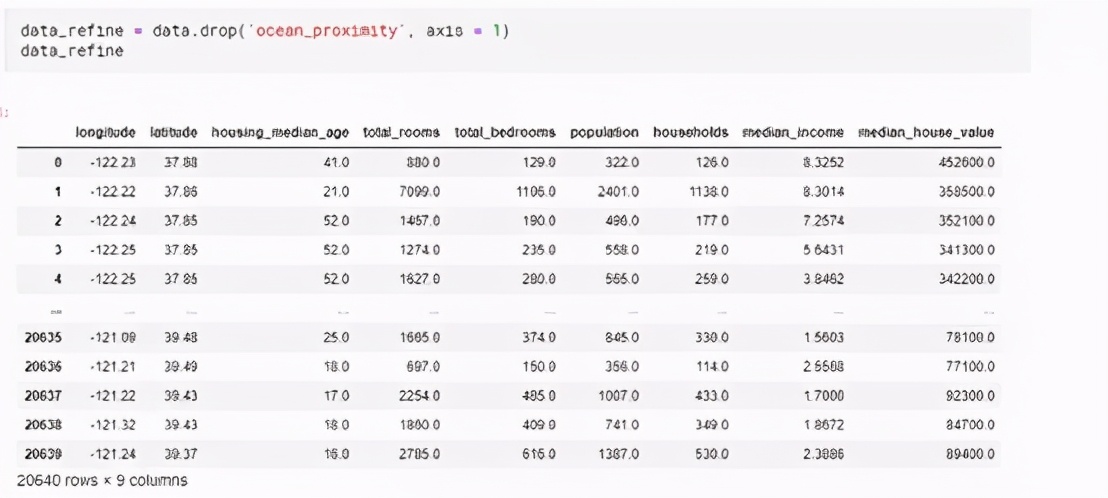
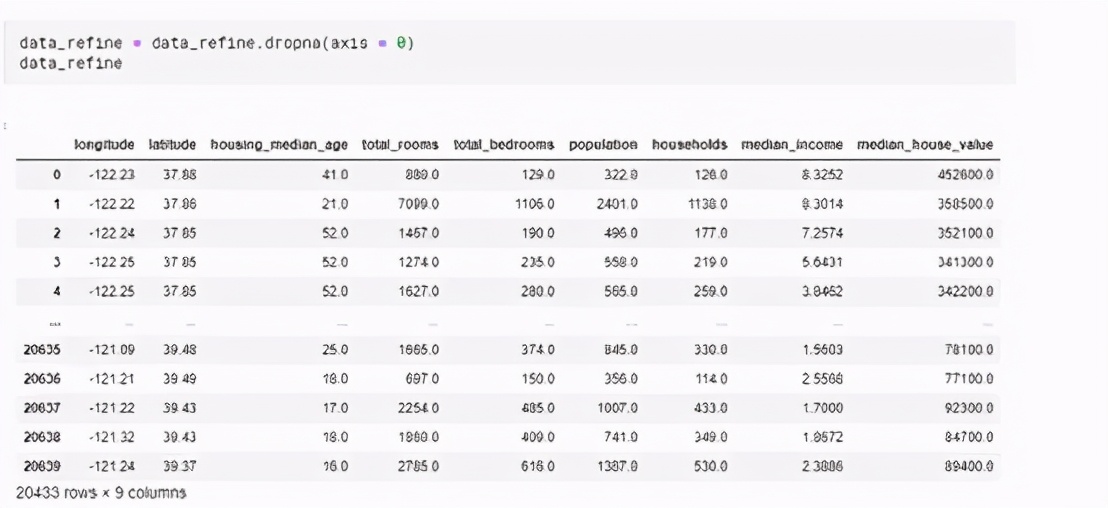
然后删掉空值的列,如下:
第三步:选择预测目标(Y)和特征(X)
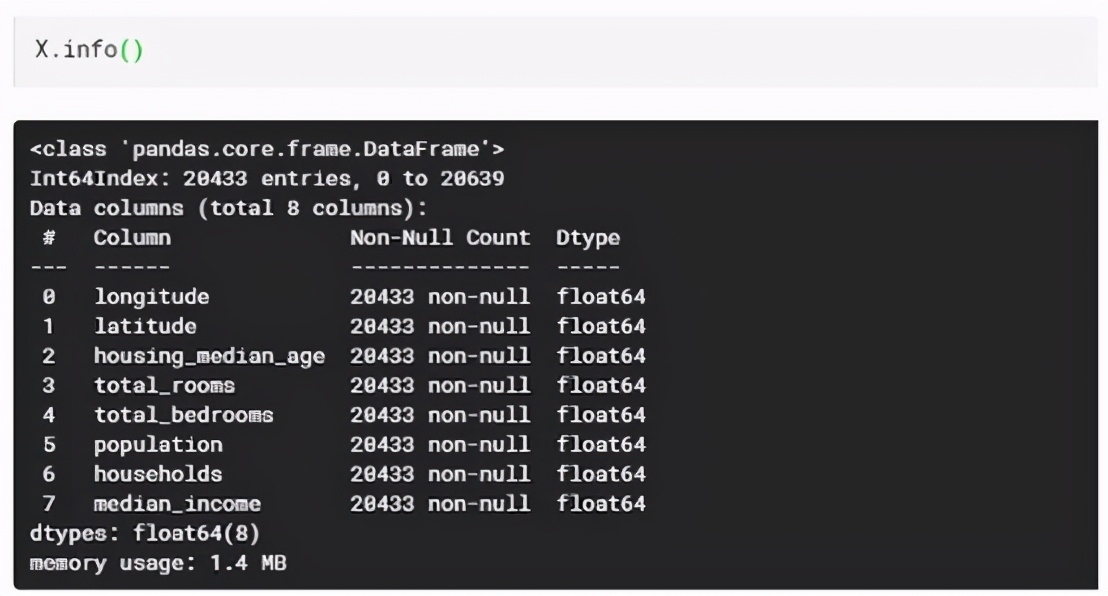
下一步是选择预测目标(Y),也就是“median_house_value”列。所以分配Y为“ median_house_value”。其余特征为X。从数据集中移除“ median_house_value”列,然后将余下的分配为X,如下所示:
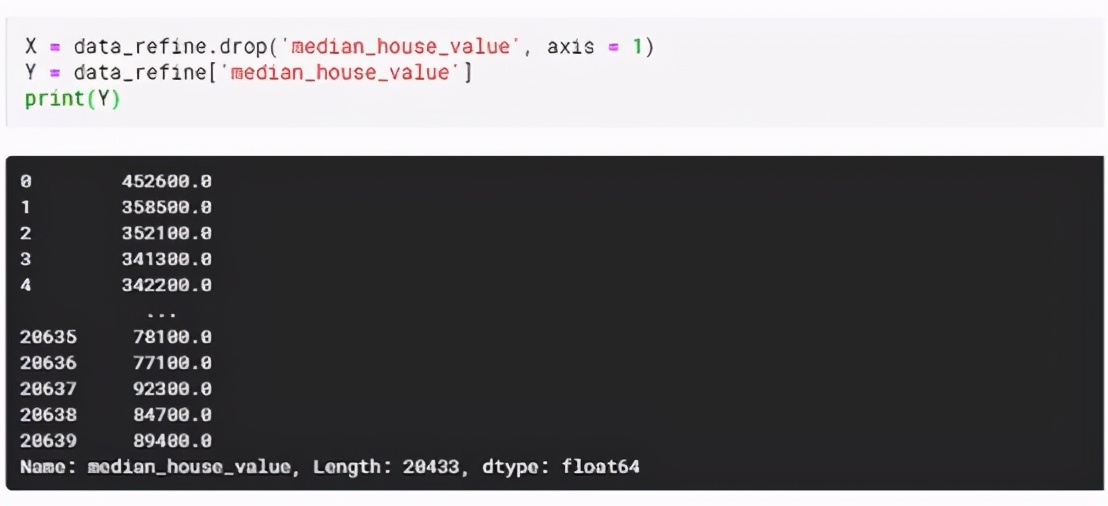
第四步:构建模型
使用scikit-learn库创建模型。该库在代码中以sklearn形式编写。当用存储在DataFrames中的数据类型进行建模时,最受欢迎的库就是Scikit-learn。建立和使用模型的步骤是:
- 定义:模型类型是什么?是线性回归还是其他类型?
- 拟合:从现有数据中获取模式(建模的核心)。
- 预测:预测目标
- 评估:确定模型预测的准确度。
现在,使用scikit-learn(sklearn)来定义线性回归模型,并将其与特征和目标变量进行拟合,并获得“ median_house_value”的预测值。导入以下库使用scikit-learn(sklearn)。

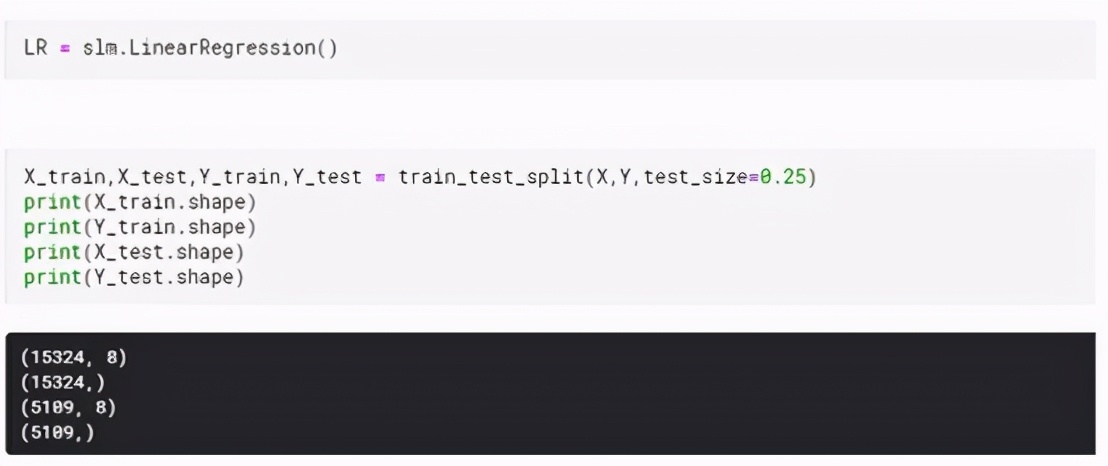
为线性回归模型创建一个变量。并且还使用train_test_split函数将数据分为训练和测试数据。在这里,我使用了25%的数据进行测试,而剩余的75%则用于训练模型。
第五步:拟合模型
用训练数据拟合线性回归模型。

完成后,预测功能通过使用X的测试值来预测房价。然后使用得分功能通过模型获得预测值的准确度,如下所示:
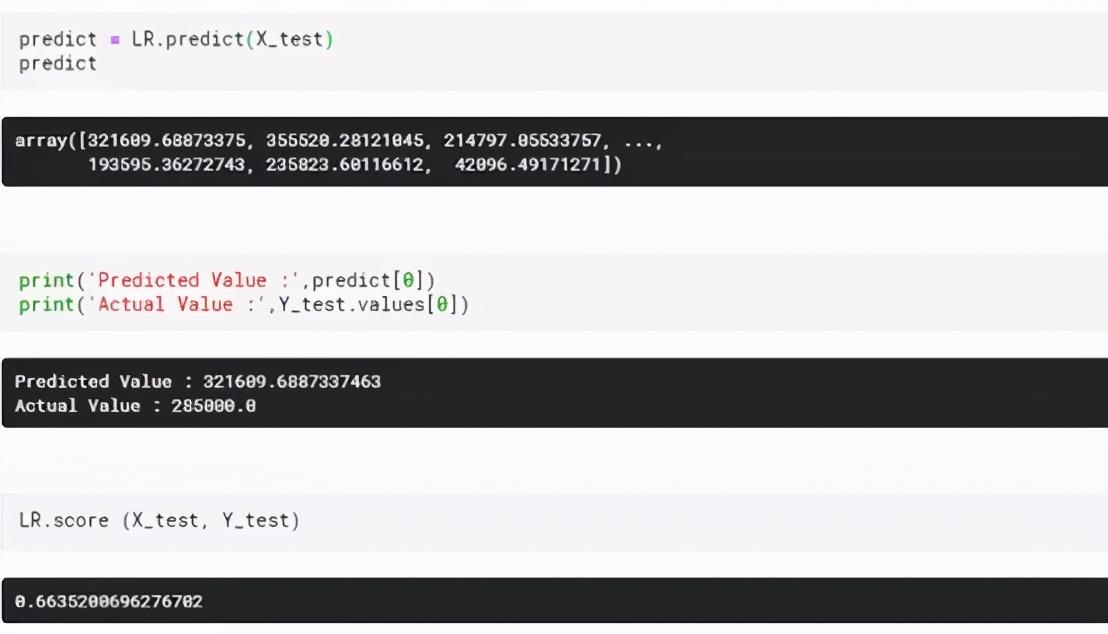
可以看到,模型预测正确率在66%左右。
第六步:画图
现在用X测试值和预测值(输出)画图,如下:
一个拟合的模型完成啦,我们可以用它预测。实际使用时,我们可以对即将上市的新房子做预测。
本例是关于如何在数据集上拟合线性回归模型并用来预测房价。我们还可以将相同的数据拟合到决策树上或用来支持向量机,并比较哪种模型预测得更好。
希望本文能帮到那些正在尝试建立第一个机器学习线性回归模型的人。

















