【51CTO.com快译】如今,在IoT(物联网)的边缘处,使用Apache Kafka来进行事件流传输,已不再是什么高深的技术了。作为一种通用的方法,Kafka在边缘处提供了与云端、以及数据中心,相同的开放、灵活且可扩展的架构。它是横跨IoT和非IoT(如:传统数据中心和云端基础架构)的流式神经系统的基本组件。实际上,Kafka可以被部署在零售商店、手机信号塔、火车、小型工厂、以及饭店等各种边缘位置。
本文将重点向您介绍Kafka客户和Kafka代理(brokers)在跨行业边缘处的用例与架构,其中包括边缘的处理、集成、去耦、低延迟、以及经济高效的数据处理。
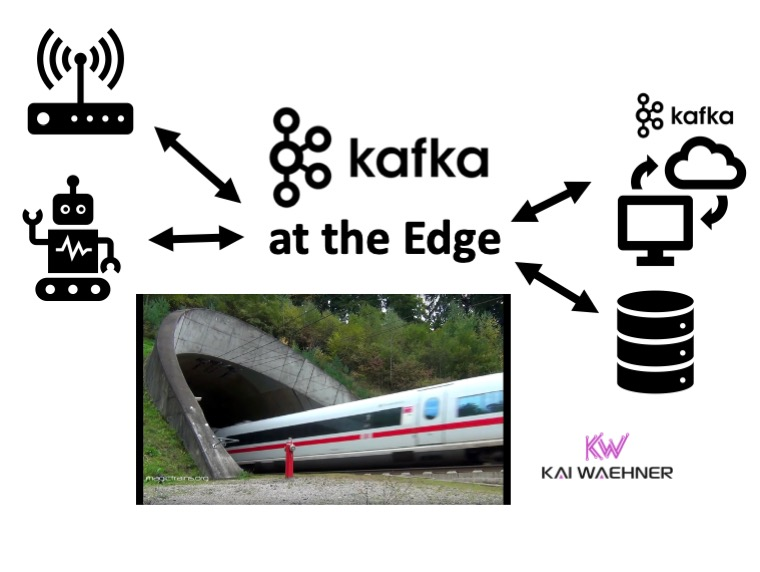
Kafka在边缘的类别和体系架构
大多数物联网项目的构建,都与在数据中心或云端的普通Kafka项目有着本质的区别。它们无法提供可靠的Kafka集群,以及在云端建立稳定的网络连接,而具有如下的边缘功能:
- 由于没有与中央数据中心、或云端的高可用性连接,因此不具备一些本地的预处理,低延迟的实时分析,低带宽的断续连接等,而离线式的业务连续就显得非常重要。
- 项目通常需要在零售店、火车、饭店、手机信号塔、小型工厂等数百个地点部署Kafka代理。因此,单个代理虽然不需要高可用性,但是要能够承受背压(backpressure),并提供本地的处理能力。
- Kafka代理(不仅是客户端)需要低空间占用率,少接触,以及尽量少的DevOps安装必需性(即:几乎没有IT人员到现场运维Kafka)。因此,使用经过认证的OEM硬件,是在边缘安装和操控Kafka的绝佳选择。
- 许多边缘用例都会涉及到传感器和遥测数据(telemetry data)。与不能丢失每条交易数据的电商系统不同,IoT应用场景允许在每秒处理数百万条消息的应用中,丢失少量消息,而且不会影响到最终的计算结果。
- 混合云或非云:消费物联网(Consumer IoT,CIoT)会涉及到智能家居、共享乘车、零售商店等环境,而工业物联网(Industrial IoT,IIoT)则会涉及到汽车、食品、能源等生产场景。
- 通常包含了传感器、主机、移动设备等成千上万个连接接口。
边缘处Kafka的用例
总的说来,Kafka在边缘处的体系架构和部署场景会包括:数据集成,预处理,云端复制,边缘大(小)数据的处理和分析,连接中断时的脱机方案,具有数百个点位的极低硬件空间占用率方案,以及非高可用性的方案等。下面,我们来看几个典型行业的应用:
- 公共服务部门:由政府行政机构牵头的公共交通管理,来自不同汽车制造商的各种车联网平台的集成,图像捕获和处理,物联网安全等智慧城市的项目。
- 运输/物流/铁路/航空:在列车上,Kafka可用于离线处理和本地存储,航旅信息的Track&Trace(包括延迟或取消等信息的跟踪),实时的用户忠诚度平台(包括舱位的升级,休息室的使用权)。
- 汽车/航天/半导体/化工/食品等制造业:物联网售后客户服务,机器和车辆的OEM,嵌入式标准软件(如:ERP或MES系统),设备/机器/生产线的数字孪生/流程,以及通过监控工厂的生产线,执行预测性的维护,质量控制,仪表板/车间/外围健康状况的跟踪等。
- 能源/公用事业/石油和天然气:智能家居/建筑/电表,远程设备的监控(如:钻探机、风车或采矿机),针对管道和炼油操作的预测性异常检测与故障诊断。
- 电信/媒体:OSS(运营支撑系统)的实时监控,指标报告,问题分析,根本原因分析,网络设备和基础设施(如:路由器、交换机、及其他网络设备)的响应,BSS(业务支撑系统)的客户体验,OTT服务(各种第三方移动应用的集成),以及5G边缘(如:街道上的传感器)设备的状态。
- 医疗保健:在医院中实施追踪,远程监控,设备传感器分析等。
- 零售/食品/餐厅/银行业务:客户沟通,交叉销售,忠诚度分析,零售付款,库存盘点,PoS机集成,远程CRM集成,以及EFTPOS(销售点的电子资金转帐)。
我们曾经为一个零售快餐连锁品牌--Chic-fil-A,部署了针对边缘计算的相关服务。我们在其2000家餐厅中都部署了Kubernetes集群(请参见--https://www.infoq.com/presentations/chick-fil-a-k8-clusters/),以便在没有互联网连接的情况下,仍然可以凭借着边缘计算实现实时的分析(请参见--https://medium.com/@cfatechblog/edge-computing-at-chick-fil-a-7d67242675e2)。下图是他们的硬件边缘设备,外观体积非常小,内部配置了Intel四核处理器、8 GB RAM和SSD。

边缘架构示例:运输和物流行业的Kafka
让我们通过一个铁路公司的特定案例,来具体讨论边缘处的Kafka混合方案。该方案利用离线式边缘处理,实现了客户通信,云端复制分析,以及与第三方合作伙伴的接口和API相集成。虽然这是一个铁路和运输行业的例子,但是我们可以轻松地将其映射到其他的行业中。
混合架构—从边缘到云端
设想,一列火车正在边缘处对产生的信息进行局部处理。如果有互联网连接和免费的网络资源,那么这列火车会将相关的数据实时复制到云端。而如果火车在行进中失去网络连接,那么Kafka将处理背压,并在网络连接恢复时将数据复制到云端。下图是在边缘和云端用到的Kafka混合架构:
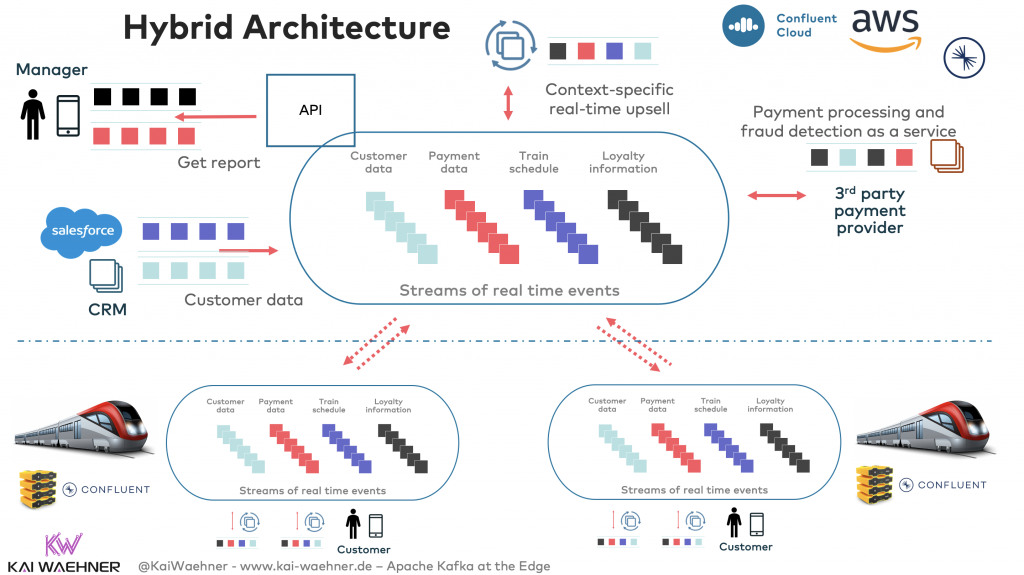
Kafka在边缘处的事件流
如下图所示,火车在边缘处使用Apache Kafka,实现对实时消息/事件流的传递和背压处理。
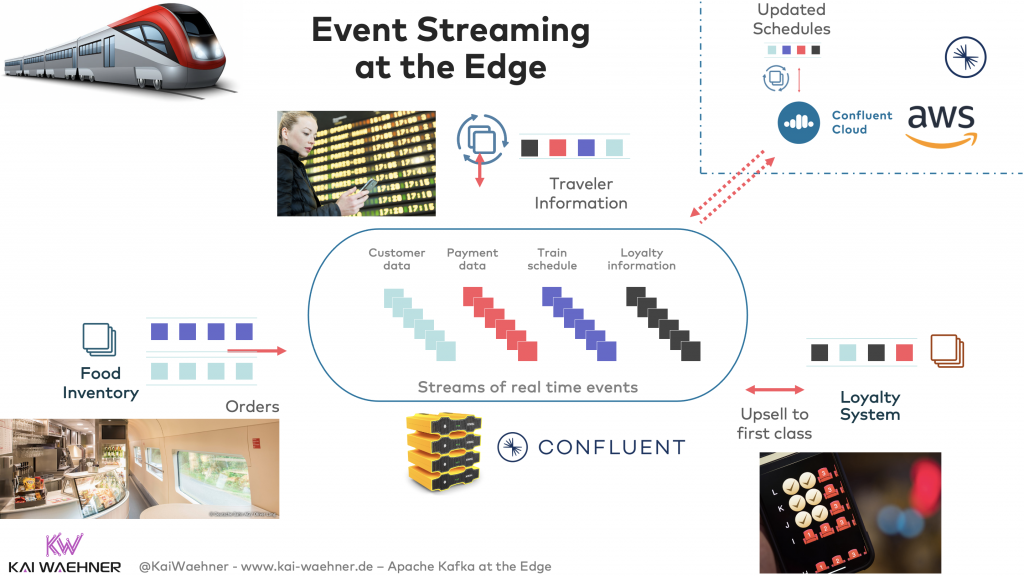
在掉线/离线场景中使用Kafka
火车在驶过隧道或到达没有网线连接的区域时,就会出现离线的情况。此时,我们需要火车上的边缘设备仍然可以进行本地处理。毕竟,业务连续性是改善客户体验和增加销售量的关键因素。即使火车处于离线,乘客仍然需要通过移动应用,来查看时刻表信息,在餐厅购买食物,或在火车的本地服务器上观看电影。同时,一旦火车重建互联网连接,乘客的购买交易将会被转移到云端的用户忠诚度系统中,需要查询的最新消息也会从云端被传递(consume)过来,并存储在火车的边缘--Kafka代理处。下图展示了Kafka在离线和断开连接的模式下,如何在边缘处进行数据处理。
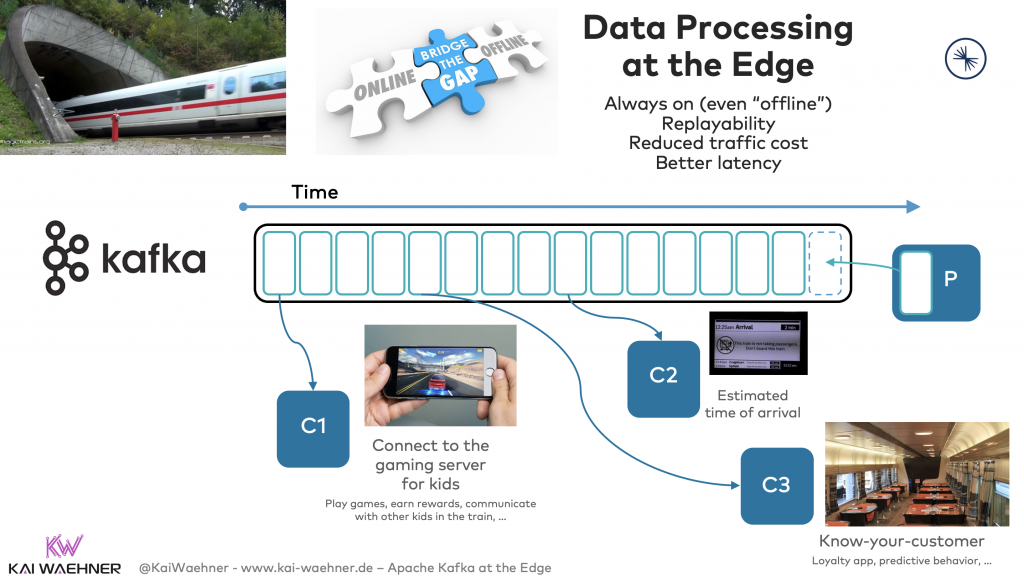
跨公司的Kafka和边缘整合
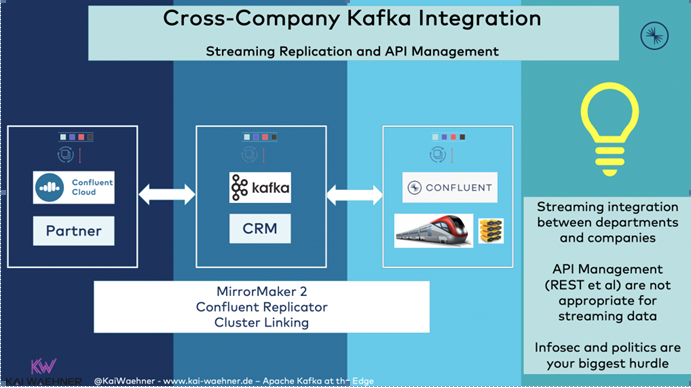
由于数据处理会在边缘(如:火车)和云端系统(如:CRM、忠诚度系统等)之间的整合系统中持续发生,因此不同的合作伙伴也要进行此类整合。与通过非扩展性的同步REST API调用/API管理,进行合作伙伴间的整合相比,使用Kafka原生的事件流复制机制,是一种更好、更具可扩展性的方法。下图展示了合作伙伴之间如何进行跨公司的Kafka复制与API管理。
在边缘部署Kafka的基础架构和硬件要求
下面我们来讨论如何在边缘处部署Kafka。注意,Kafka需要目标系统具有一定的计算能力。这取决于您正在使用的:硬件供应商、基础架构、特定的SLA、以及高可用性要求等诸多因素。值得庆幸的是,Kafka可以被部署在包括裸金属(bare metal)、虚拟机、容器、Kubernetes在内的许多基础架构中。而当前厂商能够生产的、可被用在边缘处的最小芯片通常具有4GB、8GB、甚至16GB的RAM。
在实际应用中,运行Kafka所需的最低硬件配置为:单核处理器 + 几个100MB的RAM。该配置已经能够让单个Kafka节点(复制因子 = 1)以超过100Mb/sec的吞吐量进行边缘处理了。当然,实际数值也会取决于分区的数量、消息的大小、网络的速度等各方面的因素。这与数据中心或云端的性能和可扩展性肯定是没法比的。
所以说,您可以将Kafka代理部署在树莓派(Raspberry Pi)上,但不能部署到小型嵌入式设备上,毕竟我们可以在设备上运行Kafka客户端。
在边缘处部署Kafka的“Confluent Way(融合方式)”
从技术角度来看,在边缘处部署Kafka与在数据中心或云端比较类似,只是环境和要求有所不同。而且一些附加的功能还会方便我们部署和操作Kafka。下面,让我们来了解一下Confluent部署方式的创新与差异化功能:
1. Confluent服务器包含了Kafka代理和各种增强型功能,其中包括:自平衡群集、分层存储、嵌入式REST API、服务器端模式验证等。它可以被部署为单个节点(非常轻便,但不具备高可用性)或群集模式(主要针对依赖于边缘处高可用性的关键任务负载)。
2. 虽然目前该方式仍需要ZooKeeper作为附加组件,以实现协同工作,但是预计2021年将不再需要。届时,它将是一个由Kafka支持的、独立且单流程化的边缘解决方案。
3. 群集链接(Cluster Linking,请参见--https://www.confluent.io/blog/kafka-cluster-linking-with-confluent-platform)允许所有小的Kafka边缘站点使用Kafka协议,连接到数据中心或云端更大的Kafka群集中,而无需使用诸如Confluent Replicator或MirrorMaker等其他工具与架构。据此,开发人员可以大幅减少在基础架构上的成本与工作量。
4. 使用Confluent的工具集,来进行监控和主动支持(Proactive Support,请参见--https://docs.confluent.io/5.4.0/proactive-support.html)。例如,一个控制中心可以监控几个不同的远程Kafka群集。受监控的目标不仅包括技术架构,还包括应用程序,以及端到端的集成。而Confluent Telemetry Reporter(请参见--https://docs.confluent.io/current/kafka/telemetry.html#what-data-is-sent-and-how-it-is-used)则会从边缘站点收集相关的数据。
5. 目前,Kubernetes(MicroK8s Kubernetes发行版,请参见--https://microk8s.io/)正在成为许多边缘部署的首选编排平台。Confluent Operator恰好能以CRD(自定义资源定义,https://kubernetes.io/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions/)的方式,提供了对边缘处单一代理、或群集部署的滚动升级、以及安全自动化等操作功能。前文提到的Chic-fil-A其在2000多家快餐店中运行着Kubernetes(请参见--https://medium.com/@cfatechblog/edge-computing-at-chick-fil-a-7d67242675e2),并提供各项低延迟的边缘服务,恰恰是Confluent Operator在Confluent Cloud和数据中心内Confluent Platform上进行大型实际部署的成功案例。当然,Kubernetes是按需选用的。有些边缘处在使用了Kubernetes后,反而增加了复杂性,以及对于有限资源的耗费。
6. 由于数据集成和数据处理是边缘计算的关键,Confluent提供了用于新旧系统的连接器,其中包括针对PLC、OPC-UA和IIoT集成的PLC4X(请参见--https://www.kai-waehner.de/blog/2019/09/02/apache-kafka-ksql-and-apache-plc4x-for-iiot-data-integration-and-processing/)、数据库CDC的连接器、MQ与MQTT的集成、云端连接器、以及用于高安全性或“肮环境”中的单向UDP网络的Data Diode连接器(请参见--https://docs.confluent.io/current/connect/kafka-connect-data-diode/index.html)。当然,Kafka Streams和ksqlDB则允许轻量级且功能强大的事件流处理。
7. 轻量级边缘客户端(如:嵌入式设备)可以利用Kafka和REST代理的C与C++客户端上的API(请参见--https://github.com/edenhill/librdkafka),通过HTTP(S)与任何编程语言进行通信。这对于许多计算能力有限的低功率边缘设备来说是非常重要的。毕竟,我们在这些设备中无法部署Java、或类似的“资源密集型(resource-hungry)技术”。
8. 您也可以选择将已认证的、预配置的OEM硬件放置在边缘处,将其连接到LAN或WiFi上,然后使用由硬件商提供的远程软件,对基础架构进行管理和监控。“在Hivecell上进行可行性处理”的视频(请参见--https://medium.com/hivecell/feasible-video-processing-on-hivecell-a28f9a059ccf)展示了如何通过Kafka集群、Kafka Streams应用、以及用于图像识别的嵌入式机器学习模型,进行边缘分析。
小结
作为绝佳的边缘解决方案,Kafka使您能够在边缘处、数据中心和云端,部署同样开放、可靠、且可扩展的技术。希望上述介绍的有关边缘处Kafka的用例与架构,能够帮助您更好地了解如何在各个行业中,利用事件流和工具来构建从边缘到云端的物联网架构。
原文标题:Kafka at the Edge — Use Cases and Architectures,作者:Kai Wähner
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】