













引言:近段时间,一个让梦娜丽莎图像动起来的项目火遍了朋友圈。而今天我们就将实现让图片中的人物随着视频人物一起产生动作。
其中通过在静止图像中动画对象产生视频有无数的应用跨越的领域兴趣,包括电影制作、摄影和电子商务。更准确地说,是图像动画指将提取的视频外观结合起来自动合成视频的任务一种源图像与运动模式派生的视频。
近年来,深度生成模型作为一种有效的图像动画技术出现了视频重定向。特别是,可生成的对抗网络(GANS)和变分自动编码器(VAES)已被用于在视频中人类受试者之间转换面部表情或运动模式。

根据论文FirstOrder Motion Model for Image Animation可知,在姿态迁移的大任务当中,Monkey-Net首先尝试了通过自监督范式预测关键点来表征姿态信息,测试阶段估计驱动视频的姿态关键点完成迁移工作。在此基础上,FOMM使用了相邻关键点的局部仿射变换来模拟物体运动,还额外考虑了遮挡的部分,遮挡的部分可以使用image inpainting生成。
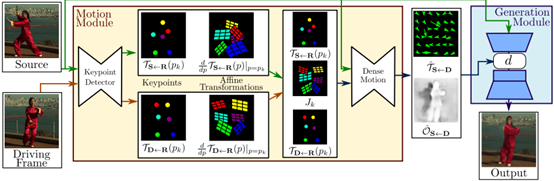
而今天我们就将借助论文所分享的源代码,构建模型创建自己需要的人物运动。具体流程如下。
实验前的准备
首先我们使用的python版本是3.6.5所用到的模块如下:
- imageio模块用来控制图像的输入输出等。
- Matplotlib模块用来绘图。
- numpy模块用来处理矩阵运算。
- Pillow库用来加载数据处理。
- pytorch模块用来创建模型和模型训练等。
- 完整模块需求参见requirements.txt文件。
模型的加载和调用
通过定义命令行参数来达到加载模型,图片等目的。
(1)首先是训练模型的读取,包括模型加载方式:
- def load_checkpoints(config_path, checkpoint_path, cpu=False):
- with open(config_path) as f:
- config = yaml.load(f)
- generator = OcclusionAwareGenerator(**config[ model_params ][ generator_params ],
- **config[ model_params ][ common_params ])
- if not cpu:
- generator.cuda()
- kp_detector = KPDetector(**config[ model_params ][ kp_detector_params ],
- **config[ model_params ][ common_params ])
- if not cpu:
- kp_detector.cuda()
- if cpu:
- checkpoint = torch.load(checkpoint_path, map_location=torch.device( cpu ))
- else:
- checkpoint = torch.load(checkpoint_path)
- generator.load_state_dict(checkpoint[ generator ])
- kp_detector.load_state_dict(checkpoint[ kp_detector ])
- if not cpu:
- generator = DataParallelWithCallback(generator)
- kp_detector = DataParallelWithCallback(kp_detector)
- generator.eval()
- kp_detector.eval()
- return generator, kp_detector
(2)然后是利用模型创建产生的虚拟图像,找到最佳的脸部特征:
- def make_animation(source_image, driving_video, generator, kp_detector, relative=True, adapt_movement_scale=True, cpu=False):
- with torch.no_grad():
- predictions = []
- source = torch.tensor(source_image[np.newaxis].astype(np.float32)).permute(0, 3, 1, 2)
- if not cpu:
- sourcesource = source.cuda()
- driving = torch.tensor(np.array(driving_video)[np.newaxis].astype(np.float32)).permute(0, 4, 1, 2, 3)
- kp_source = kp_detector(source)
- kp_driving_initial = kp_detector(driving[:, :, 0])
- for frame_idx in tqdm(range(driving.shape[2])):
- drivingdriving_frame = driving[:, :, frame_idx]
- if not cpu:
- driving_framedriving_frame = driving_frame.cuda()
- kp_driving = kp_detector(driving_frame)
- kp_norm = normalize_kp(kp_sourcekp_source=kp_source, kp_drivingkp_driving=kp_driving,
- kp_driving_initialkp_driving_initial=kp_driving_initial, use_relative_movement=relative,
- use_relative_jacobian=relative, adapt_movement_scaleadapt_movement_scale=adapt_movement_scale)
- out = generator(source, kp_sourcekp_source=kp_source, kp_driving=kp_norm) predictions.append(np.transpose(out[ prediction ].data.cpu().numpy(), [0, 2, 3, 1])[0])
- return predictions
- def find_best_frame(source, driving, cpu=False):
- import face_alignment
- def normalize_kp(kp):
- kpkp = kp - kp.mean(axis=0, keepdims=True)
- area = ConvexHull(kp[:, :2]).volume
- area = np.sqrt(area)
- kp[:, :2] = kp[:, :2] / area
- return kp
- fa = face_alignment.FaceAlignment(face_alignment.LandmarksType._2D, flip_input=True,
- device= cpu if cpu else cuda )
- kp_source = fa.get_landmarks(255 * source)[0]
- kp_source = normalize_kp(kp_source)
- norm = float( inf )
- frame_num = 0
- for i, image in tqdm(enumerate(driving)):
- kp_driving = fa.get_landmarks(255 * image)[0]
- kp_driving = normalize_kp(kp_driving)
- new_norm = (np.abs(kp_source - kp_driving) ** 2).sum()
- if new_norm < norm:
- norm = new_norm
- frame_num = i
- return frame_num
(3) 接着定义命令行调用参数加载图片、视频等方式:
- parser = ArgumentParser()
- parser.add_argument("--config", required=True, help="path to config")
- parser.add_argument("--checkpoint", default= vox-cpk.pth.tar , help="path to checkpoint to restore")
- parser.add_argument("--source_image", default= sup-mat/source.png , help="path to source image")
- parser.add_argument("--driving_video", default= sup-mat/source.png , help="path to driving video")
- parser.add_argument("--result_video", default= result.mp4 , help="path to output")
- parser.add_argument("--relative", dest="relative", action="store_true", help="use relative or absolute keypoint coordinates")
- parser.add_argument("--adapt_scale", dest="adapt_scale", action="store_true", help="adapt movement scale based on convex hull of keypoints")
- parser.add_argument("--find_best_frame", dest="find_best_frame", action="store_true",
- help="Generate from the frame that is the most alligned with source. (Only for faces, requires face_aligment lib)")
- parser.add_argument("--best_frame", dest="best_frame", type=int, default=None,
- help="Set frame to start from.")
- parser.add_argument("--cpu", dest="cpu", action="store_true", help="cpu mode.")
- parser.set_defaults(relative=False)
- parser.set_defaults(adapt_scale=False)
- opt = parser.parse_args()
- source_image = imageio.imread(opt.source_image)
- reader = imageio.get_reader(opt.driving_video)
- fps = reader.get_meta_data()[ fps ]
- driving_video = []
- try:
- for im in reader:
- driving_video.append(im)
- except RuntimeError:
- pass
- reader.close()
- source_image = resize(source_image, (256, 256))[..., :3]
- driving_video = [resize(frame, (256, 256))[..., :3] for frame in driving_video]
- generator, kp_detector = load_checkpoints(config_path=opt.config, checkpoint_path=opt.checkpoint, cpu=opt.cpu)
- if opt.find_best_frame or opt.best_frame is not None:
- i = opt.best_frame if opt.best_frame is not None else find_best_frame(source_image, driving_video, cpu=opt.cpu)
- print ("Best frame: " + str(i))
- driving_forward = driving_video[i:]
- driving_backward = driving_video[:(i+1)][::-1]
- predictions_forward = make_animation(source_image, driving_forward, generator, kp_detector, relative=opt.relative, adapt_movement_scale=opt.adapt_scale, cpu=opt.cpu)
- predictions_backward = make_animation(source_image, driving_backward, generator, kp_detector, relative=opt.relative, adapt_movement_scale=opt.adapt_scale, cpu=opt.cpu)
- predictions = predictions_backward[::-1] + predictions_forward[1:]
- else:
- predictions = make_animation(source_image, driving_video, generator, kp_detector, relative=opt.relative, adapt_movement_scale=opt.adapt_scale, cpu=opt.cpu)
- imageio.mimsave(opt.result_video, [img_as_ubyte(frame) for frame in predictions], fpsfps=fps)
模型的搭建
整个模型训练过程是图像重建的过程,输入是源图像和驱动图像,输出是保留源图像物体信息的含有驱动图像姿态的新图像,其中输入的两张图像来源于同一个视频,即同一个物体信息,那么整个训练过程就是驱动图像的重建过程。大体上来说分成两个模块,一个是motion estimation module,另一个是imagegeneration module。
(1)其中通过定义VGG19模型建立网络层作为perceptual损失。
其中手动输入数据进行预测需要设置更多的GUI按钮,其中代码如下:
- class Vgg19(torch.nn.Module):
- """
- Vgg19 network for perceptual loss. See Sec 3.3.
- """
- def __init__(self, requires_grad=False):
- super(Vgg19, self).__init__()
- vgg_pretrained_features = models.vgg19(pretrained=True).features
- self.slice1 = torch.nn.Sequential()
- self.slice2 = torch.nn.Sequential()
- self.slice3 = torch.nn.Sequential()
- self.slice4 = torch.nn.Sequential()
- self.slice5 = torch.nn.Sequential()
- for x in range(2):
- self.slice1.add_module(str(x), vgg_pretrained_features[x])
- for x in range(2, 7):
- self.slice2.add_module(str(x), vgg_pretrained_features[x])
- for x in range(7, 12):
- self.slice3.add_module(str(x), vgg_pretrained_features[x])
- for x in range(12, 21):
- self.slice4.add_module(str(x), vgg_pretrained_features[x])
- for x in range(21, 30):
- self.slice5.add_module(str(x), vgg_pretrained_features[x])
- self.mean = torch.nn.Parameter(data=torch.Tensor(np.array([0.485, 0.456, 0.406]).reshape((1, 3, 1, 1))),
- requires_grad=False)
- self.std = torch.nn.Parameter(data=torch.Tensor(np.array([0.229, 0.224, 0.225]).reshape((1, 3, 1, 1))),
- requires_grad=False)
- if not requires_grad:
- for param in self.parameters():
- param.requires_grad = False
- def forward(self, X):
- X = (X - self.mean) / self.std
- h_relu1 = self.slice1(X)
- h_relu2 = self.slice2(h_relu1)
- h_relu3 = self.slice3(h_relu2)
- h_relu4 = self.slice4(h_relu3)
- h_relu5 = self.slice5(h_relu4)
- out = [h_relu1, h_relu2, h_relu3, h_relu4, h_relu5]
- return out
(2)创建图像金字塔计算金字塔感知损失:
- class ImagePyramide(torch.nn.Module):
- """
- Create image pyramide for computing pyramide perceptual loss. See Sec 3.3
- """
- def __init__(self, scales, num_channels):
- super(ImagePyramide, self).__init__()
- downs = {}
- for scale in scales:
- downs[str(scale).replace( . , - )] = AntiAliasInterpolation2d(num_channels, scale)
- self.downs = nn.ModuleDict(downs)
- def forward(self, x):
- out_dict = {}
- for scale, down_module in self.downs.items():
- out_dict[ prediction_ + str(scale).replace( - , . )] = down_module(x)
- return out_dict
(3)等方差约束的随机tps变换
- class Transform:
- """
- Random tps transformation for equivariance constraints. See Sec 3.3
- """
- def __init__(self, bs, **kwargs):
- noise = torch.normal(mean=0, std=kwargs[ sigma_affine ] * torch.ones([bs, 2, 3]))
- self.theta = noise + torch.eye(2, 3).view(1, 2, 3)
- self.bs = bs
- if ( sigma_tps in kwargs) and ( points_tps in kwargs):
- self.tps = True
- self.control_points = make_coordinate_grid((kwargs[ points_tps ], kwargs[ points_tps ]), type=noise.type())
- selfself.control_points = self.control_points.unsqueeze(0)
- self.control_params = torch.normal(mean=0,
- std=kwargs[ sigma_tps ] * torch.ones([bs, 1, kwargs[ points_tps ] ** 2]))
- else:
- self.tps = False
- def transform_frame(self, frame):
- grid = make_coordinate_grid(frame.shape[2:], type=frame.type()).unsqueeze(0)
- gridgrid = grid.view(1, frame.shape[2] * frame.shape[3], 2)
- grid = self.warp_coordinates(grid).view(self.bs, frame.shape[2], frame.shape[3], 2)
- return F.grid_sample(frame, grid, padding_mode="reflection")
- def warp_coordinates(self, coordinates):
- theta = self.theta.type(coordinates.type())
- thetatheta = theta.unsqueeze(1)
- transformed = torch.matmul(theta[:, :, :, :2], coordinates.unsqueeze(-1)) + theta[:, :, :, 2:]
- transformedtransformed = transformed.squeeze(-1)
- if self.tps:
- control_points = self.control_points.type(coordinates.type())
- control_params = self.control_params.type(coordinates.type())
- distances = coordinates.view(coordinates.shape[0], -1, 1, 2) - control_points.view(1, 1, -1, 2)
- distances = torch.abs(distances).sum(-1)
- result = distances ** 2
- resultresult = result * torch.log(distances + 1e-6)
- resultresult = result * control_params
- resultresult = result.sum(dim=2).view(self.bs, coordinates.shape[1], 1)
- transformedtransformed = transformed + result
- return transformed
- def jacobian(self, coordinates):
- new_coordinates = self.warp_coordinates(coordinates)
- gradgrad_x = grad(new_coordinates[..., 0].sum(), coordinates, create_graph=True)
- gradgrad_y = grad(new_coordinates[..., 1].sum(), coordinates, create_graph=True)
- jacobian = torch.cat([grad_x[0].unsqueeze(-2), grad_y[0].unsqueeze(-2)], dim=-2)
- return jacobian

(4)生成器的定义:生成器,给定的源图像和和关键点尝试转换图像根据运动轨迹引起要点。部分代码如下:
- class OcclusionAwareGenerator(nn.Module):
- def __init__(self, num_channels, num_kp, block_expansion, max_features, num_down_blocks,
- num_bottleneck_blocks, estimate_occlusion_map=False, dense_motion_params=None, estimate_jacobian=False):
- super(OcclusionAwareGenerator, self).__init__()
- if dense_motion_params is not None:
- self.dense_motion_network = DenseMotionNetwork(num_kpnum_kp=num_kp, num_channelsnum_channels=num_channels,
- estimate_occlusion_mapestimate_occlusion_map=estimate_occlusion_map,
- **dense_motion_params)
- else:
- self.dense_motion_network = None
- self.first = SameBlock2d(num_channels, block_expansion, kernel_size=(7, 7), padding=(3, 3))
- down_blocks = []
- for i in range(num_down_blocks):
- in_features = min(max_features, block_expansion * (2 ** i))
- out_features = min(max_features, block_expansion * (2 ** (i + 1)))
- down_blocks.append(DownBlock2d(in_features, out_features, kernel_size=(3, 3), padding=(1, 1)))
- self.down_blocks = nn.ModuleList(down_blocks)
- up_blocks = []
- for i in range(num_down_blocks):
- in_features = min(max_features, block_expansion * (2 ** (num_down_blocks - i)))
- out_features = min(max_features, block_expansion * (2 ** (num_down_blocks - i - 1)))
- up_blocks.append(UpBlock2d(in_features, out_features, kernel_size=(3, 3), padding=(1, 1)))
- self.up_blocks = nn.ModuleList(up_blocks)
- self.bottleneck = torch.nn.Sequential()
- in_features = min(max_features, block_expansion * (2 ** num_down_blocks))
- for i in range(num_bottleneck_blocks):
- self.bottleneck.add_module( r + str(i), ResBlock2d(in_features, kernel_size=(3, 3), padding=(1, 1)))
- self.final = nn.Conv2d(block_expansion, num_channels, kernel_size=(7, 7), padding=(3, 3))
- self.estimate_occlusion_map = estimate_occlusion_map
- self.num_channels = num_channels
(5)判别器类似于Pix2PixGenerator。
- def __init__(self, num_channels=3, block_expansion=64, num_blocks=4, max_features=512,
- sn=False, use_kp=False, num_kp=10, kp_variance=0.01, **kwargs):
- super(Discriminator, self).__init__()
- down_blocks = []
- for i in range(num_blocks):
- down_blocks.append(
- DownBlock2d(num_channels + num_kp * use_kp if i == 0 else min(max_features, block_expansion * (2 ** i)),
- min(max_features, block_expansion * (2 ** (i + 1))),
- norm=(i != 0), kernel_size=4, pool=(i != num_blocks - 1), snsn=sn))
- self.down_blocks = nn.ModuleList(down_blocks)
- self.conv = nn.Conv2d(self.down_blocks[-1].conv.out_channels, out_channels=1, kernel_size=1)
- if sn:
- self.conv = nn.utils.spectral_norm(self.conv)
- self.use_kp = use_kp
- self.kp_variance = kp_variance
- def forward(self, x, kp=None):
- feature_maps = []
- out = x
- if self.use_kp:
- heatmap = kp2gaussian(kp, x.shape[2:], self.kp_variance)
- out = torch.cat([out, heatmap], dim=1)
- for down_block in self.down_blocks:
- feature_maps.append(down_block(out))
- out = feature_maps[-1]
- prediction_map = self.conv(out)
- return feature_maps, prediction_map
最终通过以下代码调用模型训练“python demo.py--config config/vox-adv-256.yaml --driving_video path/to/driving/1.mp4--source_image path/to/source/7.jpg --checkpointpath/to/checkpoint/vox-adv-cpk.pth.tar --relative --adapt_scale”
效果如下:
















