很多时候在日常的项目中,有些数据是不允许重复的,例如用户信息中的登陆名,一旦存在同一个登陆名,必然不知道到底是哪个用户执行登陆操作,导致系统异常。
常常在防止数据重复的情况下,我们都采用唯一索引去解决,如下
- CREATE TABLE `login` (
- `id` bigint unsigned NOT NULL AUTO_INCREMENT,
- `name` varchar(255) DEFAULT NULL,
- `password` varchar(255) DEFAULT NULL,
- PRIMARY KEY (`id`),
- UNIQUE KEY `idx_name` (`name`) USING BTREE
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
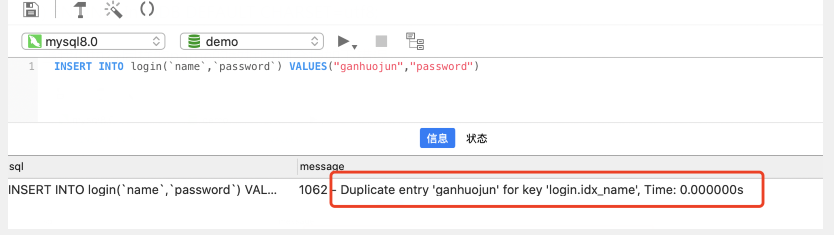
当我们执行同样的name的数据时则会报如下错误
除了这个方法,你还知道其他的吗?
下面我们介绍另外几种方法
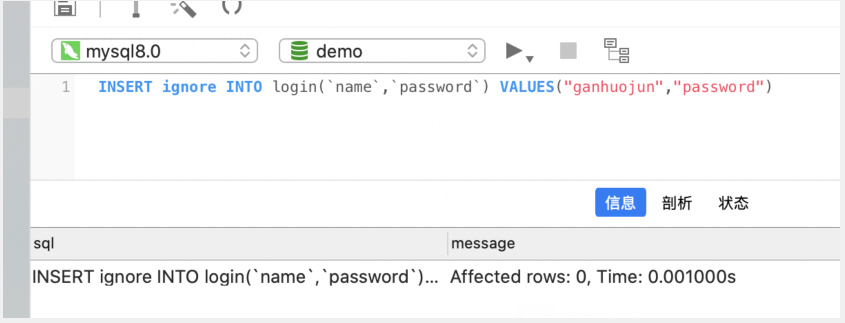
insert ignore into
插入数据时,如果数据存在,则忽略此次插入
INSERT ignore INTO login(`name`,`password`) VALUES("ganhuojun","password")
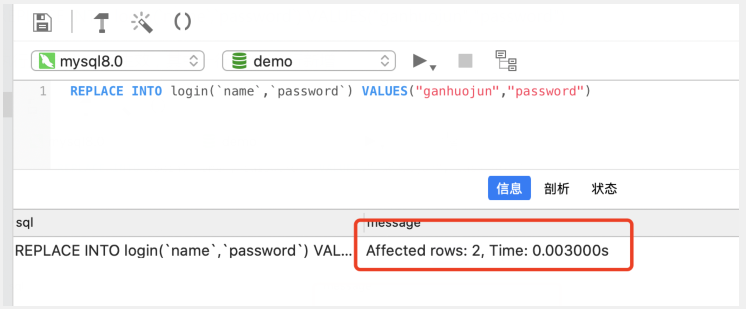
replace into
插入数据时,如果数据存在,则删除再插入
REPLACE INTO login(`name`,`password`) VALUES("ganhuojun","password")
执行后发现,2行生效,其中一行删除,1行新增
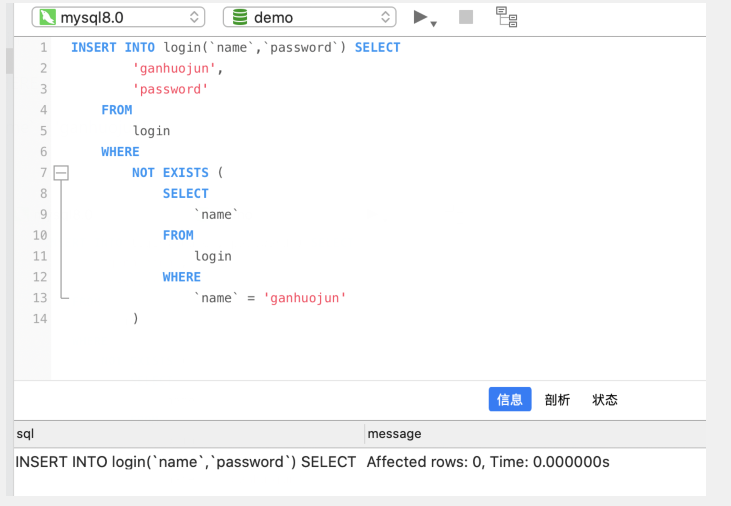
insert if not exists
sql的语法为insert into … select … where not exist ...,该语句先判断mysql数据库中是否存在这条数据,如果不存在,则正常插入,如果存在,则忽略
- INSERT INTO login ( `name`, `password` ) SELECT
- 'ganhuojun',
- 'password'
- FROM
- login
- WHERE
- NOT EXISTS (
- SELECT
- `name`
- FROM
- login
- WHERE
- `name` = 'ganhuojun'
- )
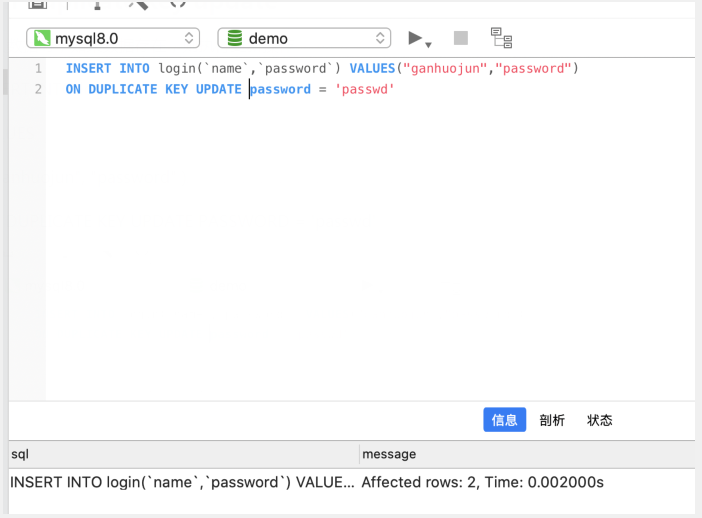
on duplicate key update
插入数据时,如果数据存在,则执行更新操作
- INSERT INTO login ( `name`, `password` )
- VALUES
- ( "ganhuojun", "password" )
- ON DUPLICATE KEY UPDATE PASSWORD = 'passwd'