前言
- 并发编程从操作系统底层工作的整体认识开始
- 深入理解Java内存模型(JMM)及volatile关键字
- 深入理解CPU缓存一致性协议(MESI)
- 并发编程之synchronized深入理解
Java并发编程核心在于 java.concurrent.util 包,而 juc 当中的大多数同步器实现都是围绕着共同的基础行为,比如等待队列、条件队列、独占获取、共享获取等,而这个行为的抽象就是基于 AbstractQueuedSynchronizer(简称为AQS),AQS 定义了一套多线程访问共享资源的同步器框架,是一个依赖状态(state)的同步器。Java中的大部分同步类(Lock、Semaphore、ReentrantLock等)都是基于 AQS 实现的。AQS是一种提供了原子式管理同步状态、阻塞和唤醒线程功能以及队列模型的简单框架。
ReentrantLock
ReentrantLock特性概览
ReentrantLock 是一种基于 AQS 框架的应用实现,是JDK中一种线程并发访问的同步手段,它的功能类似于 synchronized 是一种互斥锁,可以保证线程安全。而且它具有比 synchronized 更多的特性,比如它支持手动加锁与解锁,支持加锁的公平性。为了更好的理解 ReentrantLock 的特性,我们先讲 ReentrantLock 和 Synchronized 进行比较,其特性如下:
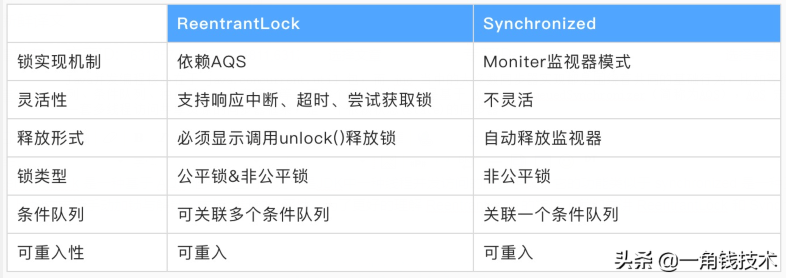
下面通过伪代码,进行更加直观的比较:
- // **************************Synchronized的使用方式**************************
- // 1.用于代码块
- synchronized (this) {}
- // 2.用于对象
- synchronized (object) {}
- // 3.用于方法
- public synchronized void test () {}
- // 4.可重入
- for (int i = 0; i < 100; i++) {
- synchronized (this) {}
- }
- // **************************ReentrantLock的使用方式**************************
- public void test () throw Exception {
- // 1.初始化选择公平锁、非公平锁
- ReentrantLock lock = new ReentrantLock(true);
- // 2.可用于代码块
- lock.lock();
- try {
- try {
- // 3.支持多种加锁方式,比较灵活; 具有可重入特性
- if(lock.tryLock(100, TimeUnit.MILLISECONDS)){ }
- } finally {
- // 4.手动释放锁
- lock.unlock()
- }
- } finally {
- lock.unlock();
- }
- }
ReentrantLock与AQS的关联
通过上面我们了解到,ReentrantLock 支持公平锁和非公平锁(关于公平锁与非公平锁的原理分析,可以参考《关于Java中锁的理解》),并且 ReentrantLock 的底层就是由 AQS 来实现的。那么 ReentrantLock 是如何实现 Synchronized 不具备的公平与非公平性的?
在 ReentrantLock 内部定义了一个Sync的内部类,该类继承AbstractQueuedSynchronized,对该抽象类的部分方法做了实现,并且还定义了两个子类:
- FairSync 公平锁的实现
- NonfairSync 非公平锁的实现
这两个类都继承自Sync,也就是间接继承了AbstractQueuedSynchronized,所以这一个 ReentrantLock同时具备公平与非公平特性。
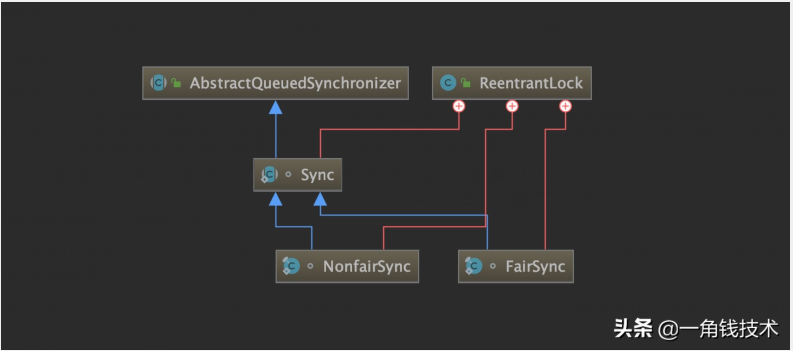
上面主要涉及的设计模式:模板模式-子类根据需要做具体业务实现,可以查看《模版方法模式》
我们再分析 ReentrantLock 是如何通过公平锁和非公平锁与AQS关联起来的?我们着重从这两者的加锁过程来理解一些它们与AQS之间的关系。
非公平锁源码中的加锁流程如下:
- // java.util.concurrent.locks.ReentrantLock#NonfairSync
- // 非公平锁
- static final class NonfairSync extends Sync {
- ...
- final void lock() {
- if (compareAndSetState(0, 1))
- setExclusiveOwnerThread(Thread.currentThread());
- else
- acquire(1);
- }
- ...
- }
这块代码的含义为:
- 若通过 CAS 设置变量 State (同步状态) 成功,也就是获取锁成功,则将当线程设置为独占锁。
- 若通过 CAS 设置变量 State (同步状态) 失败,也就是获取锁失败,则进入 Acquire 方法进行后续处理。
第一步很好理解,但第二步获取锁失败后,后续的处理策略是怎么样的呢?这块可能会有以下思考:某个线程获取锁失败的后续流程是什么呢?有以下两种可能:
- 将当前线程获锁结果设置为失败,获取锁流程结束。这种设计会极大降低系统的并发度,并不满足我们实际的需求,所以就需要下面这种流程,也就是AQS框架的处理流程。
- 存在某种排队等候机制,线程继续等待,仍然保留获取锁的可能,获取锁流程仍在继续。
对于第二种情况,我们依然有很多问题:
- 对于排队等候机制,那么就一定会有某种队列形成,这样的队列是什么数据结构呢?
- 处于排队等候机制种的线程,什么时候可以有机会获取锁呢?
- 如果处于排队等候机制种的线程一直无法获取锁,还是需要一直等待吗,还是有别的策略来解决这一问题?
带着非公平锁的这些问题,再看下公平锁源码种获取锁的方式:
- // java.util.concurrent.locks.ReentrantLock#FairSync
- // 公平锁
- static final class FairSync extends Sync {
- ...
- final void lock() {
- acquire(1);
- }
- ...
- }
看到这块代码,我们可能个会存在这种疑问:Lock 函数通过 acquire 方法进行加锁,但是具体是如何加锁的呢?
结果公平锁和非公平锁的加锁流程,虽然流程上有一定的不同,但是都调用来 acquire 方法,而 acquire 方法是 FairSync 和 UnfairSync 的父类 AQS 种的核心方法。
对于上面提到的问题,其实在 ReentrantLock 类源码中都无法解答,而这些问题的答案,都是位于 Acquire 方法所在的类 AbstractQueuedSynchronizer 中。
AQS
AQS具备特性
- 阻塞等待队列
- 共享/独占
- 公平/非公平
- 可重入
- 允许中断
除了 Lock 外,java.concurrent.util 当中同步器的实现如 Latch、Barrier、BlockingQueue 等,都是基于 AQS 框架实现
- 一般通过定义内部类 Sync 继承 AQS
- 将同步器所有调用都映射到 Sync 对应的方法
AQS框架
首先,我们通过下面的架构图来整体了解以下AQS框架:
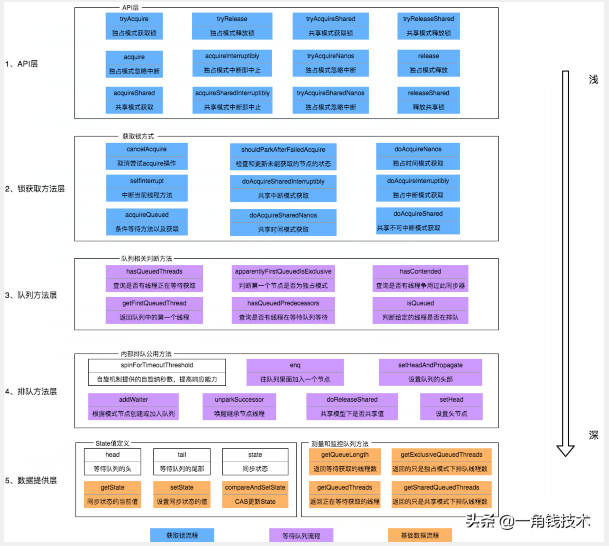
- 上图中有颜色的为Method,无颜色的为Attribution。
- 总的来说,AQS框架共分为五层,自上而下由浅入深,从AQS对外暴露的API到底层基础数据。
- 当有自定义同步器接入时,只需重写第一层所需要的部分方法即可,不需要关注底层具体的实现流程。当自定义同步器进行加锁或者解锁操作时,先经过第一层的API进入AQS内部方法,然后经过第二层进行锁的获取,接着对于获取锁失败的流程,进入第三层和第四层的等待队列处理,而这些处理方式均依赖于第五层的基础数据提供层。
下面我们会从整体到细节,从流程到方法逐一剖析AQS框架,主要分析过程如下:

AQS原理概览
AQS核心思想是,如果被请求的共享资源空闲,那么就将当前请求资源的线程设置为有效的工作线程,将共享资源设置为锁定状态;如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用 CLH队列 的变体实现的,将暂时获取不到锁的线程加入到队列中。
AQS当中的同步等待队列也称 CLH队列,CLH队列是 Craig、Landin、Hagersten 三人发明的一种基于双向链表数据结构的队列,是FIFO先入先出线程等待队列,Java 中的 CLH队列 是原CLH队列的一个变种,线程由原自旋机制改为阻塞机制。AQS 是通过将每条请求共享资源的线程封装成一个节点来实现锁的分配。主要原理如下图:
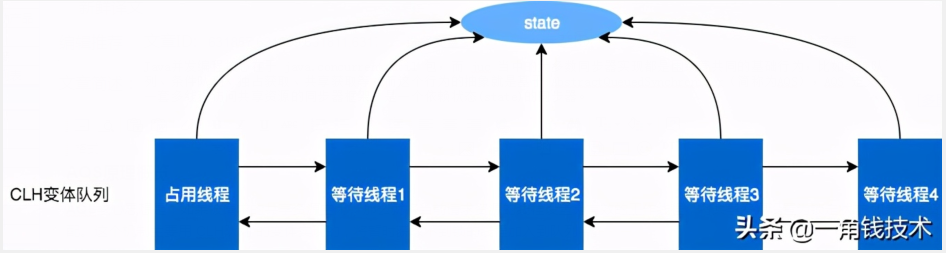
AQS内部维护属性 volatile int state (32位) 的成员变量来表示同步状态,通过内置的 FIFO队列 来完成资源获取的排队工作,通过CAS完成对State值的改变。
AQS数据结构
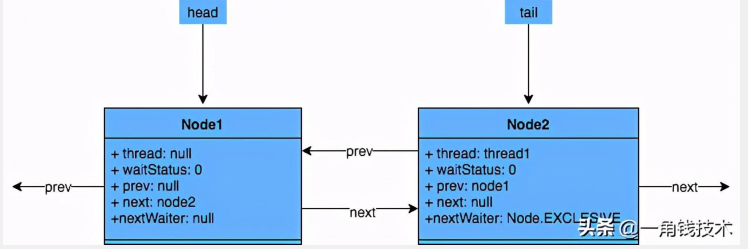
先来看一下AQS中最基本的数据结构——Node,Node即为上面CLH变体队列中的节点。

解释以下几个方法和属性值的含义:
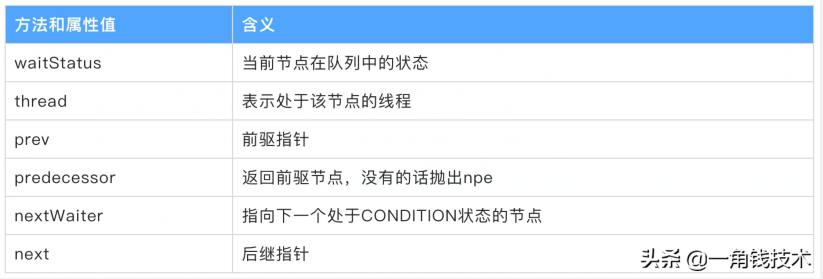
线程两种锁的模式:

waitStatus 有以下几个枚举值:

同步状态State
在了解数据结构后,接下来了解一下AQS的同步状态——State。AQS中维护了一个名为state的字段,意为同步状态,是由volatile修饰的,用于展示当前临界资源的获锁情况。
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- private volatile int state;
下面是State的三种访问方式:
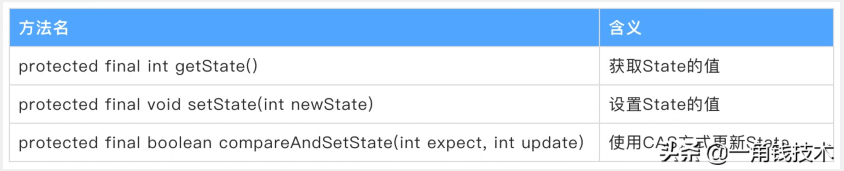
这几个方法都是 final 修饰的,说明子类中无法重写它们。我们可以通过修改State字段表示的同步状态来实现多线程的独占模式和共享模式(加锁过程)。
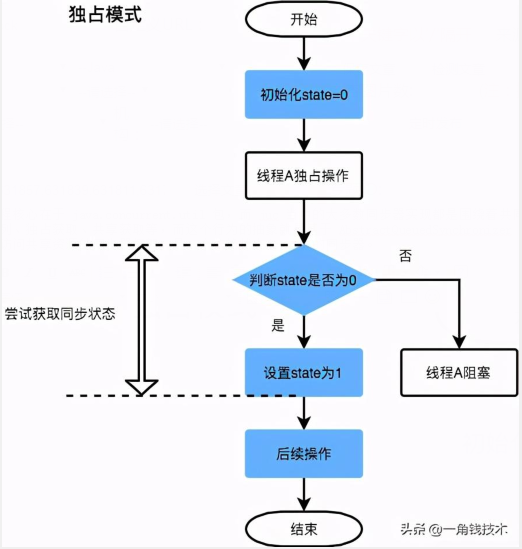
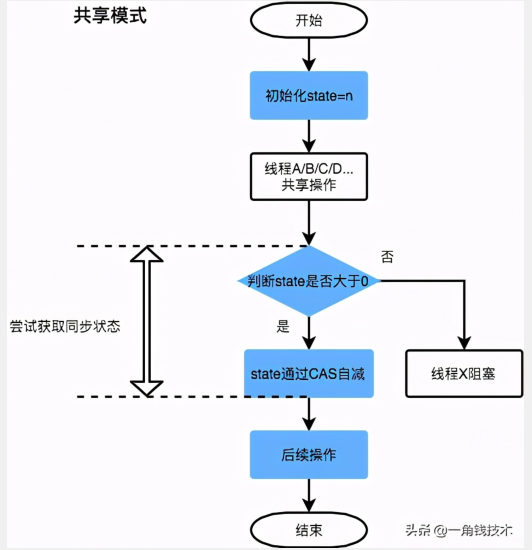
对于我们自定义的同步工具,需要自定义获取同步状态和释放状态的方式,也就是AQS架构图中的第一层:API层。
AQS重要方法与ReentrantLock的关联
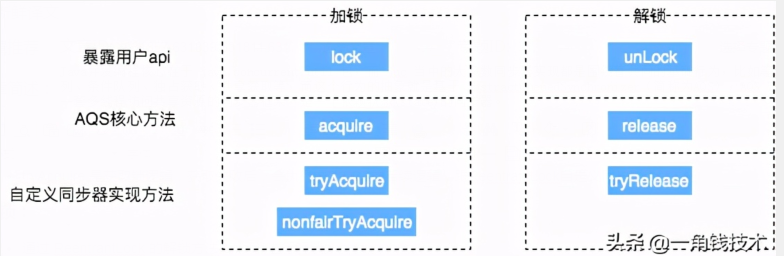
从架构图中可以得知,AQS提供来大量用于自定义同步器实现的 protected 方法。自定义同步器实现的相关方法也只是为了通过修改 state字段 来实现多线程的独占模式或者共享模式。自定义同步器需要实现以下方法(ReentrantLock需要实现的方法如下,并不是全部):

一般来说,自定义同步器要么是独占模式,要么是共享模式,它们只是需要实现 tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared 中的一种即可。AQS 也支持自定义同步器同时实现独占和共享两种方式,如 ReentrantReadWriteLock。ReentrantLock 是独占锁,所以实现了tryAcquire-tryRelease。
以非公平锁为例,这里主要阐述以下非公平锁与AQS之间方法的关联之处,具体每一处核心方法的作用会在文章后面详细进行阐述。
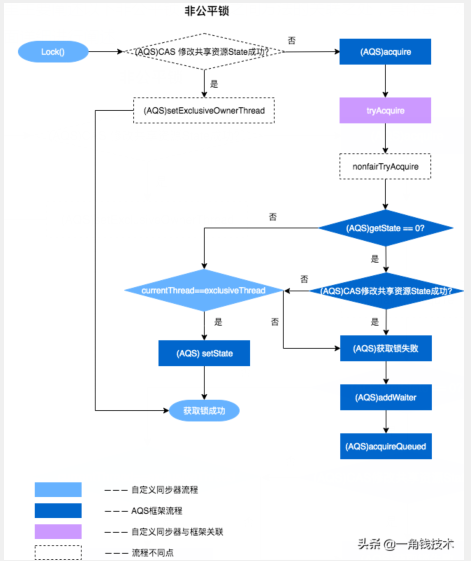
为了帮助大家理解 ReentrantLock 和 AQS 之间方法的交互过程,以非公平锁为例,我们将加锁和解锁的交互流程单独拿出来说明一下,以便与对后续内容的理解。
加锁:
- 通过 ReentrantLock 的加锁方法 lock 进行加锁操作。
- 会调用到内部类 Sync 的 lock 方法,由于 Sync#lock 是抽象方法,根据ReentrantLock初始化选择的公平锁和非公平锁,执行相关内部类的lock方法,本质上都会执行AQS的 acquire 方法。
- AQS 的acquire方法会执行 tryAcquire 方法,但是由于 tryAcquire 需要自定义同步器实现,因此执行了 ReentrantLock 中的 tryAcquire 方法,由于 ReentrantLock 是通过公平锁和非公平锁内部实现的 tryAcquire 方法,因此会根据锁类型不同,执行不同的 tryAcquire。
- tryAcquire 是获取锁逻辑,获取失败后,会执行框架AQS的后续逻辑,跟ReentrantLock自定义同步器无关。
解锁:
- 通过 ReentrantLock 的解锁方法 unlock 进行解锁。
- unlock 会调用内部类 Sync 的 release 方法,该方法继承于 AQS。
- release 中会调用 tryRelease 方法,tryRelease 需要自定义同步器实现,tryRelease 只在 ReentrantLock 中的 Sync 实现,因此可以看出,释放锁的过程,并不区分是否公平锁。
- 释放成功后,所有处理由AQS框架完成,与自定义同步器无关。
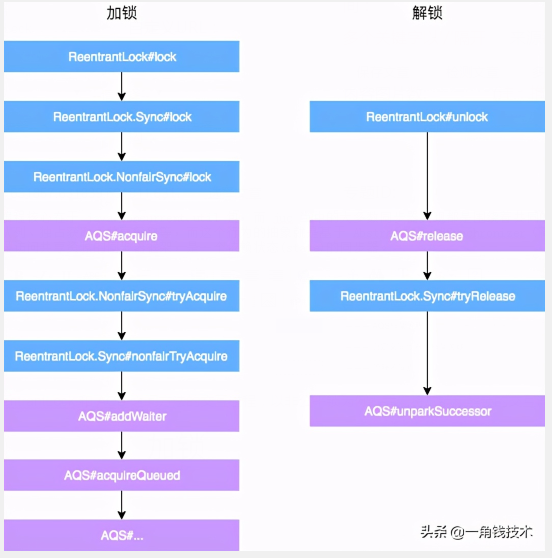
通过上面的描述,大概可以总结出 ReentrantLock 加锁解锁时API层面核心方法的映射关系。
通过ReentrantLock理解AQS
ReentrantLock 中公平锁和非公平锁在底层是相同的,这里以非公平锁为例进行分析。
在非公平锁中,有这样一段代码:
- // java.util.concurrent.locks.ReentrantLock
- // 非公平锁
- static final class NonfairSync extends Sync {
- ...
- final void lock() {
- if (compareAndSetState(0, 1))
- setExclusiveOwnerThread(Thread.currentThread());
- else
- acquire(1);
- }
- ...
- }
看一下这个 acquire 方法是怎么写的:
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- public final void acquire(int arg) {
- if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
- selfInterrupt();
- }
再看一下tryAcquire方法:
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- protected boolean tryAcquire(int arg) {
- throw new UnsupportedOperationException();
- }
可以看出,这里只是AQS的简单实现,具体获取锁的实现方法是由各自的公平锁和非公平锁单独实现的(以ReentrantLock为例)。如果该方法返回了 true,则说明当前线程获取锁成功,就不用往后执行了;如果获取失败,就需要加入到等待队列中。下面会相信解释线程是何时以及怎样被加入进等待队列中的。
线程加入等待队列
加入队列的时机
当执行 arcqure(1)时,会通过 tryAcquire 获取锁。在这种情况下,如果获取锁失败,就会调用 addWaiter 加入到等待队列中去。
如何加入队列
获取锁失败后,会执行 addWaiter(Node.EXCLUSIVE) 加入等待队列,具体实现方法如下:
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- private Node addWaiter(Node mode) {
- Node node = new Node(Thread.currentThread(), mode);
- // Try the fast path of enq; backup to full enq on failure
- Node pred = tail;
- if (pred != null) {
- node.prev = pred;
- if (compareAndSetTail(pred, node)) {
- pred.next = node;
- return node;
- }
- }
- enq(node);
- return node;
- }
- private final boolean compareAndSetTail(Node expect, Node update) {
- return unsafe.compareAndSwapObject(this, tailOffset, expect, update);
- }
主要的流程如下:
- 通过当前的线程和锁模式新建一个节点。
- pred指针执行尾节点tail。
- 将new中Node的prev指针指向pred。
- 通过 compareAndSetTail 方法,完成尾节点的设置。这个方法主要是对 tailOffset 和 expect 进行比较,如果 tailOffset 的 Node 和 expect 的Node地址是相同的,那么设置tail的值为update的值。
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- static {
- try {
- stateOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField("state"));
- headOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField("head"));
- tailOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField("tail"));
- waitStatusOffset = unsafe.objectFieldOffset(Node.class.getDeclaredField("waitStatus"));
- nextOffset = unsafe.objectFieldOffset(Node.class.getDeclaredField("next"));
- } catch (Exception ex) {
- throw new Error(ex);
- }
- }
从AQS的静态代码块可以看出,都是获取一个对象的属性相对于该对象在内存当中的偏移量,这样我们就可以根据这个偏移量在对象内存当中找到这个属性。tailOffset指的是tail对象的偏移量,所以这个时候会将new出来的Node置为当前队列的尾节点。同时,由于是双向链表,也需要将前一个节点指向尾节点。
- 如果pred指针是null(说明等待队列中没有元素),或者当前 pred指针和tail指向的位置不同(说明被别的线程已经修改),就需要看一下 enq 的方法。
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- private Node enq(final Node node) {
- for (;;) {
- Node t = tail;
- if (t == null) { // Must initialize
- if (compareAndSetHead(new Node()))
- tail = head;
- } else {
- node.prev = t;
- if (compareAndSetTail(t, node)) {
- t.next = node;
- return t;
- }
- }
- }
- }
如果没有被初始化,需要进行初始化一个头节点出来。但请注意,初始化的头节点并不是当前线程节点,而是调用了无参构造函数的节点。如果经历了初始化或者并发导致队列中有元素,则与之前的方法相同。其实,addWaiter就是一个在双端链表添加尾节点的操作,需要注意的是,双端链表的头节点是一个无参构造函数的头节点。
总结一下,线程获取锁的时候,过程大体如下:
- 当没有线程获取到锁时,线程1获取锁成功
- 线程2申请锁,但是锁被线程1占用。
- 如果再有线程要获取锁,依次在队列中往后排队即可。
回到上面的代码,hasQueuedPredecessors 是公平锁加锁时判断等待队列中释放存在有效节点的方法,如果返回 false,说明当前线程可以争取共享资源;如果返回 true,说明队列中存在有效节点,当前线程必须加入到等待队列中。
- // java.util.concurrent.locks.ReentrantLock
- public final boolean hasQueuedPredecessors() {
- // The correctness of this depends on head being initialized
- // before tail and on head.next being accurate if the current
- // thread is first in queue.
- Node t = tail; // Read fields in reverse initialization order
- Node h = head;
- Node s;
- return h != t && ((s = h.next) == null || s.thread != Thread.currentThread());
- }
看到这里,我们理解一下 h != t && ((s = h.next) == null || s.thread != Thread.currentThread()); 为什么要判断头节点的下一个节点?第一个节点存储的数据是什么?
双向链表中,第一个节点为虚节点,其实并不存储任何信息,只是占位。真正的第一个有数据的节点,是在第二个节点开始的。当 h != t 时:如果 (s = h.next) == null,等待队列正在有线程进行初始化,但只是进行到了tail指向head,没有将head指向tail,此时队列中有元素,需要返回true(这块具体见下边代码分析)。如果 (s = h.next) != null,说明此时队列中至少有一个有效节点。如果此时 s.thread == Thread.currentThread(),说明等待队列的第一个有效节点中的线程与当前线程相同,那么当前线程是可以获取资源的;如果 s.thread != Thread.cuuentThread(),说明等待队列的第一个有效节点线程与当前线程不同,当前线程必须加入进等待队列。
- // java.util.concurrent.locks.AbstractQueuedSynchronizer#enq
- if (t == null) { // Must initialize
- if (compareAndSetHead(new Node()))
- tail = head;
- } else {
- node.prev = t;
- if (compareAndSetTail(t, node)) {
- t.next = node;
- return t;
- }
- }
节点入队不是原子操作,所以会出现短暂的 head != tail,此时 tail 指向最后一个节点,而且 tail 指向 head。如果 head 没有指向 tail,这种情况下也需要将相关线程加入队列中。所以这块代码是为了解决极端情况下的并发问题。
等待队列中线程出队列时机
回到最初的代码:
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- public final void acquire(int arg) {
- if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
- selfInterrupt();
- }
上面解释了addWaiter方法,这个方法其实就是把对应的线程以Node的数据结构形式加入到双端队列里,返回的是一个包含该线程的Node。而这个Node会作为参数,进入到acquireQueued方法中。acquireQueued方法可以对排队中的线程进行“获锁”操作。
总的来说,一个线程获取锁失败了,被放入等待队列,acquireQueued会把放入队列中的线程不断去获取锁,直到获取成功或者不再需要获取(中断)。
下面我们从“何时出队列?”和“如何出队列?”两个方向来分析一下acquireQueued源码:
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- final boolean acquireQueued(final Node node, int arg) {
- // 标记是否成功拿到资源
- boolean failed = true;
- try {
- // 标记等待过程中是否中断过
- boolean interrupted = false;
- // 开始自旋,要么获取锁,要么中断
- for (;;) {
- // 获取当前节点的前驱节点
- final Node p = node.predecessor();
- // 如果p是头结点,说明当前节点在真实数据队列的首部,就尝试获取锁(别忘了头结点是虚节点)
- if (p == head && tryAcquire(arg)) {
- // 获取锁成功,头指针移动到当前node
- setHead(node);
- p.next = null; // help GC
- failed = false;
- return interrupted;
- }
- // 说明p为头节点且当前没有获取到锁(可能是非公平锁被抢占了)或者是p不为头结点,这个时候就要判断当前node是否要被阻塞(被阻塞条件:前驱节点的waitStatus为-1),防止无限循环浪费资源。具体两个方法下面细细分析
- if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
- interrupted = true;
- }
- } finally {
- if (failed)
- cancelAcquire(node);
- }
- }
注:setHead方法是把当前节点置为虚节点,但并没有修改waitStatus,因为它是一直需要用的数据。
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- private void setHead(Node node) {
- head = node;
- node.thread = null;
- node.prev = null;
- }
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- // 靠前驱节点判断当前线程是否应该被阻塞
- private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
- // 获取头结点的节点状态
- int ws = pred.waitStatus;
- // 说明头结点处于唤醒状态
- if (ws == Node.SIGNAL)
- return true;
- // 通过枚举值我们知道waitStatus>0是取消状态
- if (ws > 0) {
- do {
- // 循环向前查找取消节点,把取消节点从队列中剔除
- node.prev = pred = pred.prev;
- } while (pred.waitStatus > 0);
- pred.next = node;
- } else {
- // 设置前任节点等待状态为SIGNAL
- compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
- }
- return false;
- }
parkAndCheckInterrupt主要用于挂起当前线程,阻塞调用栈,返回当前线程的中断状态。
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- private final boolean parkAndCheckInterrupt() {
- LockSupport.park(this);
- return Thread.interrupted();
- }
上述方法的流程图如下:
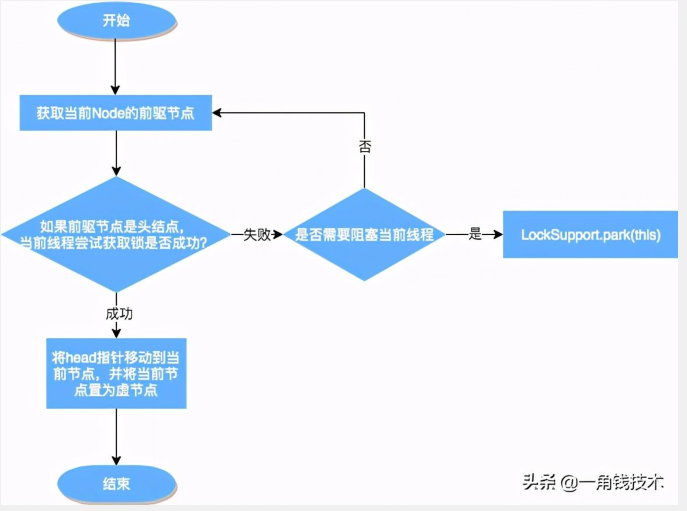
从上图可以看出,跳出当前循环的条件是当“前置节点是头结点,且当前线程获取锁成功”。为了防止因死循环导致CPU资源被浪费,我们会判断前置节点的状态来决定是否要将当前线程挂起,具体挂起流程用流程图表示如下(shouldParkAfterFailedAcquire流程):
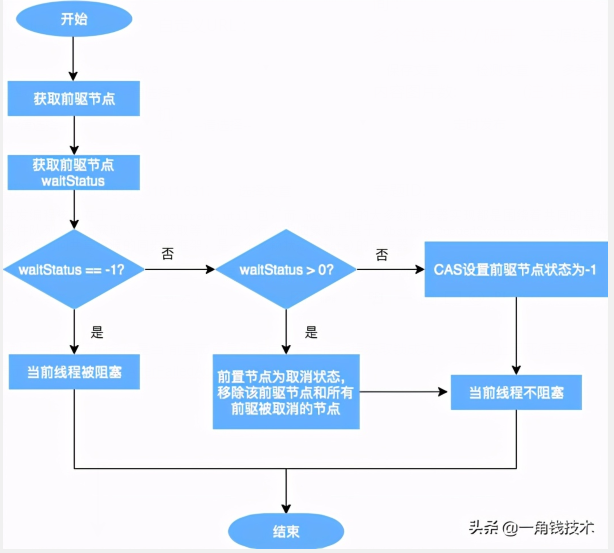
从队列中释放节点的疑虑打消了,那么又有新问题了:
- shouldParkAfterFailedAcquire 中取消节点是怎么生成的呢?什么时候会把一个节点的 waitStatus 设置为 -1?
- 是在什么时间释放节点通知到被挂起的线程呢?
CANCELLED状态节点生成
acquireQueued 方法中的Finally代码:
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- final boolean acquireQueued(final Node node, int arg) {
- boolean failed = true;
- try {
- ...
- for (;;) {
- final Node p = node.predecessor();
- if (p == head && tryAcquire(arg)) {
- ...
- failed = false;
- ...
- }
- ...
- } finally {
- if (failed)
- cancelAcquire(node);
- }
- }
通过 cancelAcquire 方法,将 Node 的状态标记为 CANCELLED。接下来,我们逐行来分析这个方法的原理:
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- private void cancelAcquire(Node node) {
- // 将无效节点过滤
- if (node == null)
- return;
- // 设置该节点不关联任何线程,也就是虚节点
- node.thread = null;
- Node pred = node.prev;
- // 通过前驱节点,跳过取消状态的node
- while (pred.waitStatus > 0)
- node.prev = pred = pred.prev;
- // 获取过滤后的前驱节点的后继节点
- Node predNext = pred.next;
- // 把当前node的状态设置为CANCELLED
- node.waitStatus = Node.CANCELLED;
- // 如果当前节点是尾节点,将从后往前的第一个非取消状态的节点设置为尾节点
- // 更新失败的话,则进入else,如果更新成功,将tail的后继节点设置为null
- if (node == tail && compareAndSetTail(node, pred)) {
- compareAndSetNext(pred, predNext, null);
- } else {
- int ws;
- // 如果当前节点不是head的后继节点,1:判断当前节点前驱节点的是否为SIGNAL,2:如果不是,则把前驱节点设置为SINGAL看是否成功
- // 如果1和2中有一个为true,再判断当前节点的线程是否为null
- // 如果上述条件都满足,把当前节点的前驱节点的后继指针指向当前节点的后继节点
- if (pred != head && ((ws = pred.waitStatus) == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) && pred.thread != null) {
- Node next = node.next;
- if (next != null && next.waitStatus <= 0)
- compareAndSetNext(pred, predNext, next);
- } else {
- // 如果当前节点是head的后继节点,或者上述条件不满足,那就唤醒当前节点的后继节点
- unparkSuccessor(node);
- }
- node.next = node; // help GC
- }
- }
当前的流程:
- 获取当前节点的前驱节点,如果前驱节点的状态是 CANCELLED,那就一直往前遍历,找到第一个 waitStatus <= 0 的节点,将找到的 pred节点和当前Node关联,将当前Node设置为CANCELLED。
- 根据当前节点的位置,考虑以下三种情况:当前节点是尾节点当前节点是head的后继节点当前节点不是head的后继节点,也不是尾节点
根据上述第二条,我们来分析每一种情况的流程。
当前节点是尾节点
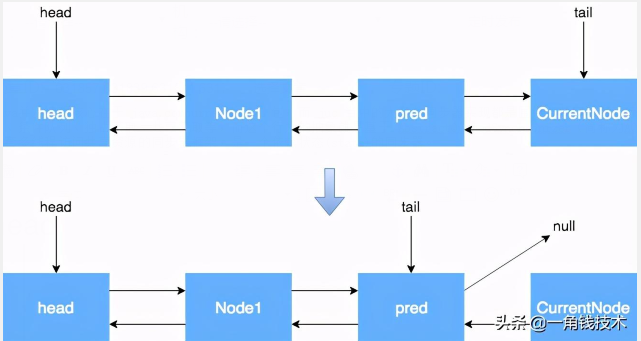
当前节点是head的后继节点
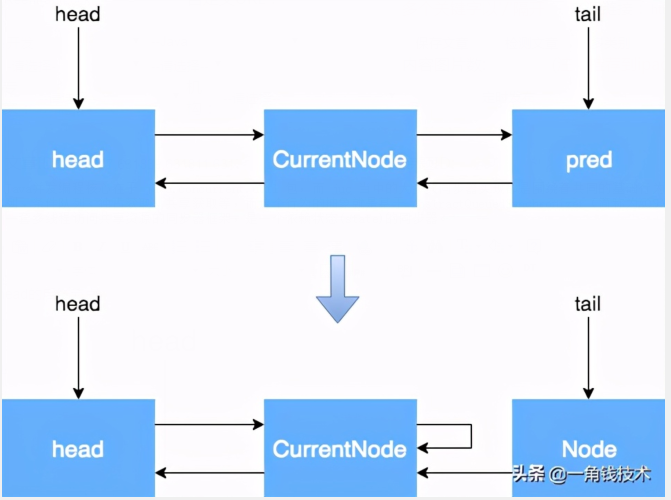
当前节点不是head的后继节点,也不是尾节点
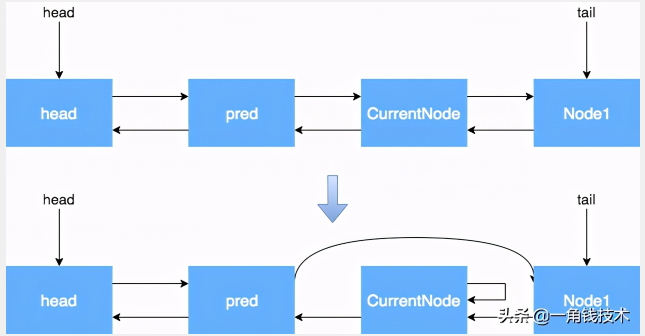
通过上面的流程,我们对于 CANCELLED 节点状态的产生和变化已经有了大致的了解,但是为什么所有的变化都是对 next 指针进行了操作,而没有对 prev 指针进行操作呢?什么情况下会对 prev 指针进行操作?
执行 cancelAcquire 的时候,当前节点的前置节点可能已经从队列中出去了(已经执行过程 try 代码块中的 shouldParkAfterFailedAcquire 方法了),如果此时修改 prev 指针,有可能会导致 prev 指向另一个已经移除队列的 Node,因此这块变化 prev 指针不安全。shouldParkAfterFailedAcquire 方法中,会执行下面的代码,其实就是在处理 prev 指针。shouldParkAfterFailedAcquire 是获取锁失败的情况下才会执行,进入该方法后,说明共享资源已被获取,当前节点之前的节点都不会出现变化,因此这个时候变更 prev 指针比较安全。
- do {
- node.prev = pred = pred.prev;
- } while (pred.waitStatus > 0);
如何解锁
我们已经剖析了加锁过程中的基本流程,接下来再对解锁的基本流程进行分析。由于 ReentrantLock 在解锁的时候,并不区分公平锁和非公平锁,所以我们直接看解锁的源码:
- // java.util.concurrent.locks.ReentrantLock
- public void unlock() {
- sync.release(1);
- }
可以看到,本质释放锁的地方,是通过框架来完成的。
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- public final boolean release(int arg) {
- if (tryRelease(arg)) {
- Node h = head;
- if (h != null && h.waitStatus != 0)
- unparkSuccessor(h);
- return true;
- }
- return false;
- }
在ReentrantLock里面的公平锁和非公平锁的父类Sync定义了可重入锁的释放锁机制。
- // java.util.concurrent.locks.ReentrantLock.Sync
- // 方法返回当前锁是不是没有被线程持有
- protected final boolean tryRelease(int releases) {
- // 减少可重入次数
- int c = getState() - releases;
- // 当前线程不是持有锁的线程,抛出异常
- if (Thread.currentThread() != getExclusiveOwnerThread())
- throw new IllegalMonitorStateException();
- boolean free = false;
- // 如果持有线程全部释放,将当前独占锁所有线程设置为null,并更新state
- if (c == 0) {
- free = true;
- setExclusiveOwnerThread(null);
- }
- setState(c);
- return free;
- }
我们来解释下述源码:
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- public final boolean release(int arg) {
- // 上边自定义的tryRelease如果返回true,说明该锁没有被任何线程持有
- if (tryRelease(arg)) {
- // 获取头结点
- Node h = head;
- // 头结点不为空并且头结点的waitStatus不是初始化节点情况,解除线程挂起状态
- if (h != null && h.waitStatus != 0)
- unparkSuccessor(h);
- return true;
- }
- return false;
- }
这里的判断条件为什么是h != null && h.waitStatus != 0?
h == null Head还没初始化。初始情况下,head == null,第一个节点入队,Head会被初始化一个虚拟节点。所以说,这里如果还没来得及入队,就会出现head == null 的情况。 h != null && waitStatus == 0 表明后继节点对应的线程仍在运行中,不需要唤醒。 h != null && waitStatus < 0 表明后继节点可能被阻塞了,需要唤醒。
再看一下unparkSuccessor方法:
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- private void unparkSuccessor(Node node) {
- // 获取头结点waitStatus
- int ws = node.waitStatus;
- if (ws < 0)
- compareAndSetWaitStatus(node, ws, 0);
- // 获取当前节点的下一个节点
- Node s = node.next;
- // 如果下个节点是null或者下个节点被cancelled,就找到队列最开始的非cancelled的节点
- if (s == null || s.waitStatus > 0) {
- s = null;
- // 就从尾部节点开始找,到队首,找到队列第一个waitStatus<0的节点。
- for (Node t = tail; t != null && t != node; t = t.prev)
- if (t.waitStatus <= 0)
- s = t;
- }
- // 如果当前节点的下个节点不为空,而且状态<=0,就把当前节点unpark
- if (s != null)
- LockSupport.unpark(s.thread);
- }
为什么要从后往前找第一个非Cancelled的节点呢?原因如下。
之前的addWaiter方法:
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- private Node addWaiter(Node mode) {
- Node node = new Node(Thread.currentThread(), mode);
- // Try the fast path of enq; backup to full enq on failure
- Node pred = tail;
- if (pred != null) {
- node.prev = pred;
- if (compareAndSetTail(pred, node)) {
- pred.next = node;
- return node;
- }
- }
- enq(node);
- return node;
- }
我们从这里可以看到,节点入队并不是原子操作,也就是说,node.prev = pred; compareAndSetTail(pred, node) 这两个地方可以看作tail入队的原子操作,但是此时pred.next = node 还没执行,如果这个时候执行了unparkSuccessor方法,就没办法从前往后找了,所以需要从后往前找。还有一点原因,在产生CANCELLED状态节点的时候,先断开的是Next指针,Prev指针并未断开,因此也是必须要从后往前遍历才能够遍历完全部的Node。
综上所述,如果是从前往后找,由于极端情况下入队的非原子操作和CANCELLED节点产生过程中断开Next指针的操作,可能会导致无法遍历所有的节点。所以,唤醒对应的线程后,对应的线程就会继续往下执行。继续执行acquireQueued方法以后,中断如何处理?
中断恢复后的执行流程
唤醒后,会执行return Thread.interrupted();,这个函数返回的是当前执行线程的中断状态,并清除。
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- private final boolean parkAndCheckInterrupt() {
- LockSupport.park(this);
- return Thread.interrupted();
- }
再回到acquireQueued代码,当parkAndCheckInterrupt返回true或者false的时候,interrupted的值不同,但都会执行下次循环。如果这个时候获取锁成功,就会把当前interrupted返回。
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- final boolean acquireQueued(final Node node, int arg) {
- boolean failed = true;
- try {
- boolean interrupted = false;
- for (;;) {
- final Node p = node.predecessor();
- if (p == head && tryAcquire(arg)) {
- setHead(node);
- p.next = null; // help GC
- failed = false;
- return interrupted;
- }
- if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
- interrupted = true;
- }
- } finally {
- if (failed)
- cancelAcquire(node);
- }
- }
如果acquireQueued为True,就会执行selfInterrupt方法。
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- static void selfInterrupt() {
- Thread.currentThread().interrupt();
- }
该方法其实是为了中断线程。但为什么获取了锁以后还要中断线程呢?这部分属于Java提供的协作式中断知识内容,感兴趣同学可以查阅一下。这里简单介绍一下:
- 当中断线程被唤醒时,并不知道被唤醒的原因,可能是当前线程在等待中被中断,也可能是释放了锁以后被唤醒。因此我们通过Thread.interrupted()方法检查中断标记(该方法返回了当前线程的中断状态,并将当前线程的中断标识设置为False),并记录下来,如果发现该线程被中断过,就再中断一次。
- 线程在等待资源的过程中被唤醒,唤醒后还是会不断地去尝试获取锁,直到抢到锁为止。也就是说,在整个流程中,并不响应中断,只是记录中断记录。最后抢到锁返回了,那么如果被中断过的话,就需要补充一次中断。
这里的处理方式主要是运用线程池中基本运作单元Worder中的runWorker,通过Thread.interrupted()进行额外的判断处理,感兴趣的同学可以看下ThreadPoolExecutor源码。
AQS应用
ReentrantLock的可重入应用
ReentrantLock的可重入性是AQS很好的应用之一,在了解完上述知识点以后,我们很容易得知 ReentrantLock 实现可重入的方法。在 ReentrantLock 里面,不管是公平锁还是非公平锁,都有一段逻辑。
公平锁:
- // java.util.concurrent.locks.ReentrantLock.FairSync#tryAcquire
- if (c == 0) {
- if (!hasQueuedPredecessors() && compareAndSetState(0, acquires)) {
- setExclusiveOwnerThread(current);
- return true;
- }
- }
- else if (current == getExclusiveOwnerThread()) {
- int nextc = c + acquires;
- if (nextc < 0)
- throw new Error("Maximum lock count exceeded");
- setState(nextc);
- return true;
- }
非公平锁:
- // java.util.concurrent.locks.ReentrantLock.Sync#nonfairTryAcquire
- if (c == 0) {
- if (compareAndSetState(0, acquires)){
- setExclusiveOwnerThread(current);
- return true;
- }
- }
- else if (current == getExclusiveOwnerThread()) {
- int nextc = c + acquires;
- if (nextc < 0) // overflow
- throw new Error("Maximum lock count exceeded");
- setState(nextc);
- return true;
- }
从上面这两段都可以看到,有一个同步状态state来控制整体可重入的情况。state是volatile修饰的,用于保证一定的可见性和有序性。
- // java.util.concurrent.locks.AbstractQueuedSynchronizer
- private volatile int state;
接下来看state这个字段的主要的过程:
- state初始化的时候为0,表示没有任何线程持有锁。
- 当有线程持有该锁时,值就会在原来的基础上+1,同一个线程多次获得锁时,就会多次+1,这里就是可重入的概念。
- 解锁也是对这个字段-1,一直到0,此线程对锁释放。
JCU中的应用场景
除了上边ReentrantLock的可重入性的应用,AQS作为并发编程的框架,为很多其他同步工具提供了良好的解决方案。下面列出了JUC中的几种同步工具,大体介绍一下AQS的应用场景:

自定义同步工具
了解AQS基本原理以后,按照上面所说的AQS知识点,自己实现一个同步工具。
- package com.niuh.lock;
- import java.util.concurrent.locks.AbstractQueuedSynchronizer;
- /**
- * 自己实现一个同步工具
- */
- public class CustomLock {
- private static class Sync extends AbstractQueuedSynchronizer {
- @Override
- protected boolean tryAcquire(int arg) {
- return compareAndSetState(0, 1);
- }
- @Override
- protected boolean tryRelease(int arg) {
- setState(0);
- return true;
- }
- @Override
- protected boolean isHeldExclusively() {
- return getState() == 1;
- }
- }
- private Sync sync = new Sync();
- public void lock() {
- sync.acquire(1);
- }
- public void unlock() {
- sync.release(1);
- }
- }
通过我们自己定义的Lock完成一定的同步功能
- static int count = 0;
- static CustomLock customLock = new CustomLock();
- public static void main(String[] args) throws InterruptedException {
- Runnable runnable = new Runnable() {
- @Override
- public void run() {
- try {
- customLock.lock();
- for (int i = 0; i < 10000; i++) {
- count++;
- }
- } catch (Exception ex) {
- ex.printStackTrace();
- } finally {
- customLock.unlock();
- }
- }
- };
- Thread thread1 = new Thread(runnable);
- Thread thread2 = new Thread(runnable);
- thread1.start();
- thread2.start();
- thread1.join();
- thread2.join();
- System.out.println(count);
- }
上述代码每次运行结果都会是20000。通过简单的几行代码就能实现同步功能,这就是AQS的强大之处。
参考
- https://tech.meituan.com/2019/12/05/aqs-theory-and-apply.html
PS:以上代码提交在 Github :
https://github.com/Niuh-Study/niuh-juc-final.git