前言
在工作中一次排查慢接口时,查到了一个函数耗时较长,最终定位到是通过 List 去重导致的。
由于测试环境还有线上早期数据较少,这个接口的性能问题没有引起较大关注,后面频繁超时,才引起重视。
之前看《阿里巴巴Java开发手册》里面有这样一段描述:

你看,阿里前辈们都免费总结了,不过还是会看到有人会用List的contains函数来去重......
不记得的,罚抄10万遍
如果需要这本书资源的网上下载也行,私聊我发你也行
今天我就结合源码聊聊Set是怎样保证数据的唯一性的,为什么两种去重方式性能差距这么大
HashSet源码
先看看类注释:
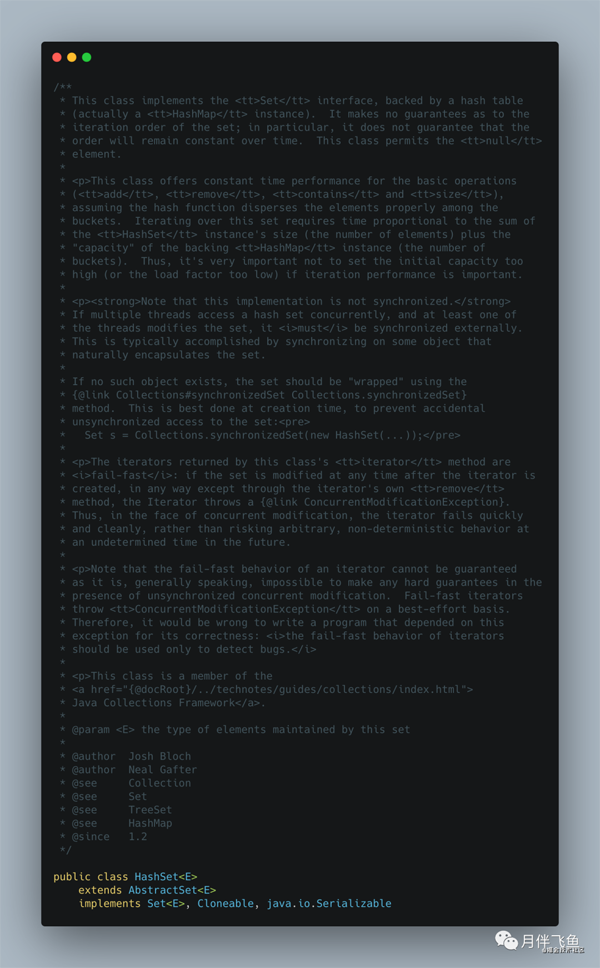
看类注释上,我们可以得到的信息有:
- 底层实现基于 HashMap,所以迭代时不能保证按照插入顺序,或者其它顺序进行迭代;
- add、remove、contanins、size 等方法的耗时性能,是不会随着数据量的增加而增加的,这个主要跟 HashMap 底层的数组数据结构有关,不管数据量多大,不考虑 hash 冲突的情况下,时间复杂度都是 O (1);
- 线程不安全的,如果需要安全请自行加锁,或者使用 Collections.synchronizedSet;
- 迭代过程中,如果数据结构被改变,会快速失败的,会抛出 ConcurrentModificationException 异常。
刚才是从类注释中看到,HashSet 的实现是基于 HashMap 的,在 Java 中,要基于基础类进行创新实现,有两种办法:
- 继承基础类,覆写基础类的方法,比如说继承 HashMap , 覆写其 add 的方法;
- 组合基础类,通过调用基础类的方法,来复用基础类的能力。
HashSet 使用的就是组合 HashMap,其优点如下:
继承表示父子类是同一个事物,而 Set 和 Map 本来就是想表达两种事物,所以继承不妥,而且 Java 语法限制,子类只能继承一个父类,后续难以扩展。
组合更加灵活,可以任意的组合现有的基础类,并且可以在基础类方法的基础上进行扩展、编排等,而且方法命名可以任意命名,无需和基础类的方法名称保持一致。
组合就是把 HashMap 当作自己的一个局部变量,以下是 HashSet 的组合实现:
// 把 HashMap 组合进来,key 是 Hashset 的 key,value 是下面的 PRESENT
private transient HashMap<E,Object> map;
// HashMap 中的 value
private static final Object PRESENT = new Object();
- 1.
- 2.
- 3.
- 4.
从这两行代码中,我们可以看出两点:
我们在使用 HashSet 时,比如 add 方法,只有一个入参,但组合的 Map 的 add 方法却有 key,value 两个入参,相对应上 Map 的 key 就是我们 add 的入参,value 就是第二行代码中的 PRESENT,此处设计非常巧妙,用一个默认值 PRESENT 来代替 Map 的 Value;
我们再来看看add方法:
public boolean add(E e) {
// 直接使用 HashMap 的 put 方法,进行一些简单的逻辑判断
return map.put(e, PRESENT)==null;
}
- 1.
- 2.
- 3.
- 4.
我们进入更底层源码java.util.HashMap#put:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
- 1.
- 2.
- 3.
再瞧瞧hash方法:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 1.
- 2.
- 3.
- 4.
可以看到如果 key 为 null ,哈希值为 0,否则将 key 通过自身hashCode函数计算的的哈希值和其右移 16 位进行异或运算得到最终的哈希值。
我们再回到 java.util.HashMap#putVal中:
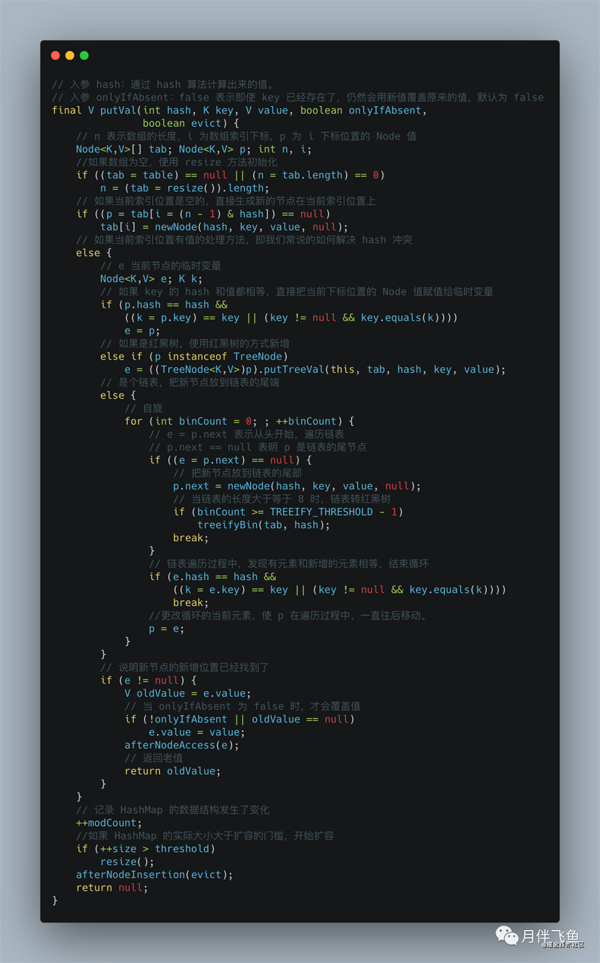
在 java.util.HashMap#putVal中,直接通过 (n - 1) & hash 来得到当前元素在节点数组中的位 置。如果不存在,直接构造新节点并存储到该节点数组的对应位置。如果存在,则通过下面逻 辑:
p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))
- 1.
来判断元素是否相等。
如果相等则用新值替换旧值,否则添加红黑树节点或者链表节点。
总结:通过HashMap的key的唯一性来保证的HashSet元素的唯一性。
最后再看看:
《阿里巴巴Java开发手册》里面还有这样一段描述:

到现在是不是明白了,这个2,3点的原因
性能对比
其实HashSet和ArrayList去重性能差异的核心在于contains函数性能对比。
我们分别查看java.util.HashSet#contains和java.util.ArrayList#contains的实现。
java.util.HashSet#contains源码:
public boolean contains(Object o) {
return map.containsKey(o);
}
- 1.
- 2.
- 3.
最终也是通过HashMap判断的
如果 hash 冲突不是极其严重(大多数都没怎么有哈希冲突),n 个元素依次判断并插入到 Set 的时间复杂度接近于 O (n),查找的复杂度是O(1)。
接下来我们看java.util.ArrayList#contains的源码:
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
- 1.
- 2.
- 3.
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
发现其核心逻辑为:如果为 null, 则遍历整个集合判断是否有 null 元素;否则遍历整个列表,通 过 o.equals(当前遍历到的元素) 判断与当前元素是否相等,相等则返回当前循环的索引。
所以, java.util.ArrayList#contains判断并插入n个元素到 Set 的时间复杂度接近于O (n^2),查找的复杂度是O(n)。
因此,通过时间复杂度的比较,性能差距就不言而喻了。
我们分别将两个时间复杂度函数进行作图, 两者增速对比非常明显:
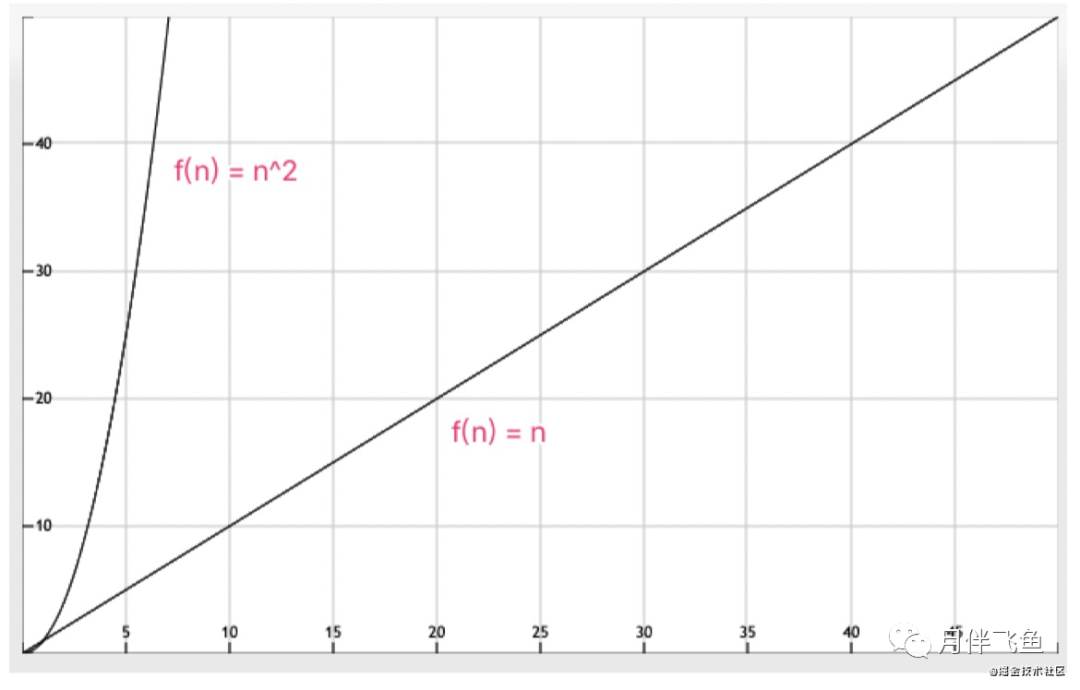
如果数据量不大时采用 List 去重勉强可以接受,但是数据量增大后,接口响应时间会超慢,这 是难以忍受的,甚至造成大量线程阻塞引发故障。
本文转载自微信公众号「 月伴飞鱼」,可以通过以下二维码关注。转载本文请联系 月伴飞鱼公众号。