深度强化学习(DRL)是深度学习领域研究最快的领域之一。DRL负责AI近年来的一些顶级里程碑,例如AlphaGo,Dota2 Five或Alpha Star,DRL似乎是最接近人类智能的学科。但是,尽管取得了所有进展,但DRL方法在现实世界中的实现仍然受限于大型人工智能(AI)实验室。部分原因是DRL体系结构依赖不成比例的大量培训,这使得它们对大多数组织而言在计算上昂贵且不切实际。最近,Google Research发表了一篇论文,提出了SEED RL,这是一种可大规模扩展的DRL模型的新架构。
在现实世界中实现DRL模型的挑战与它们的体系结构直接相关。 本质上,DRL包含各种任务,例如运行环境,模型推断,模型训练或重放缓冲区。 大多数现代DRL体系结构无法有效地分配用于此任务的计算资源,从而使其实施成本不合理。 诸如AI硬件加速器之类的组件已帮助解决了其中一些限制,但它们只能走得那么远。 近年来,出现了新架构,这些新架构已被市场上许多最成功的DRL实现所采用。
从IMPALA汲取灵感
在当前的DRL体系结构中,IMPALA为该领域树立了新的标准。IMPALA最初是由DeepMind在2018年的研究论文中提出的,它引入了一种模型,该模型利用专门用于数值计算的加速器,充分利用了监督学习多年来受益的速度和效率。IMPALA的中心是一个基于参与者的模型,该模型通常用于最大化并发和并行化。
基于IMPALA的DRL代理的体系结构分为两个主要组件:参与者和学习者。在此模型中,参与者通常在CPU上运行,并在环境中采取的步骤与对该模型进行推断之间进行迭代,以预测下一个动作。参与者经常会更新推理模型的参数,并且在收集到足够数量的观察结果之后,会将观察结果和动作的轨迹发送给学习者,从而对学习者进行优化。在这种体系结构中,学习者使用来自数百台机器上的分布式推理的输入在GPU上训练模型。从计算的角度来看,IMPALA体系结构可以使用GPU加速学习者的学习,而参与者可以在许多机器上进行扩展。
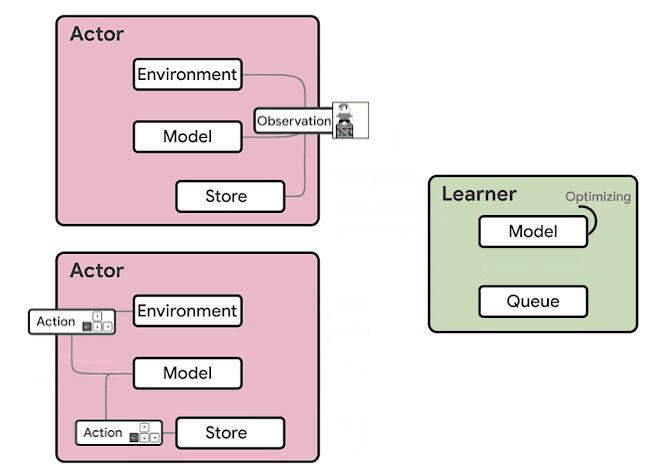
> Source: https://ai.googleblog.com/2020/03/massively-scaling-reinforcement.html
IMPALA在DRL体系结构中建立了新标准。 但是,该模型具有一些固有的局限性。
·使用CPU进行神经网络推断:参与者机器通常基于CPU。 当模型的计算需求增加时,推理所花费的时间开始超过环境步长的计算。 解决方案是增加参与者的数量,这会增加成本并影响融合。
·资源利用效率低下:参与者在两个任务之间交替进行:环境步骤和推断步骤。这两个任务的计算要求通常不相似,从而导致利用率低下或参与者行动缓慢。
·带宽要求:模型参数,循环状态和观察值在参与者和学习者之间传递。此外,基于内存的模型会发送大状态,从而增加了带宽需求。
Google以IMPALA actor模型为灵感,开发了一种新架构,该架构解决了其前身在DRL模型缩放方面的一些局限性。
种子RL
总体而言,Google的SEED RL体系结构与IMPALA极为相似,但它引入了一些变体,解决了DeepMind模型的一些主要限制。 在SEED RL中,神经网络推理由学习者在专用硬件(GPU或TPU)上集中完成,从而通过确保模型参数和状态保持局部状态来加快推理速度并避免数据传输瓶颈。 对于每个环境步骤,都会发送观测值
给学习者,学习者进行推理并将动作发送回参与者。这个聪明的解决方案解决了IMPALA等模型的推理限制,但可能会带来延迟挑战。
为了最大程度地减少延迟影响,SEED RL依靠gPRC进行消息传递和流传输。 具体来说,SEED RL利用流式RPC,从参与者到学习者的连接保持打开状态,元数据仅发送一次。 此外,该框架包括一个批处理模块,该模块可有效地将多个参与者推理调用一起批处理。
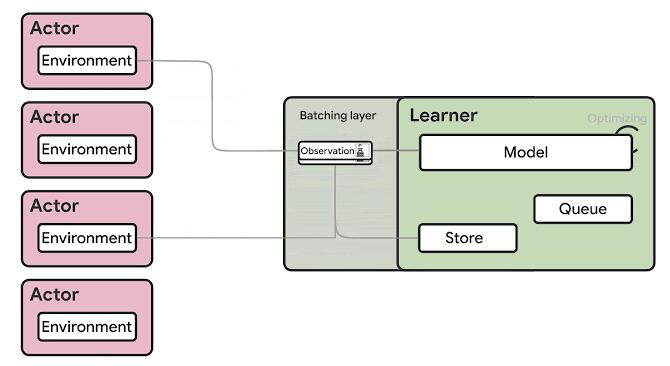
> Source: https://ai.googleblog.com/2020/03/massively-scaling-reinforcement.html
深入研究IMPALA架构,将运行三种基本类型的线程:
1.推论
2.数据预取
3.训练
推理线程会收到一批观察,奖励和情节终止标志。它们加载循环状态并将数据发送到推理TPU内核。接收采样的动作和新的重复状态,并且在存储最新的重复状态的同时,将动作发送回参与者。轨迹完全展开后,它将添加到FIFO队列或重播缓冲区中,然后由数据预取线程进行采样。最后,将轨迹推入设备缓冲区,以供每个参加训练的TPU内核使用。训练线程(Python主线程)采用预取的轨迹,使用训练的TPU内核计算梯度,并将梯度同步应用于所有TPU内核的模型(推理和训练)。可以调整推理和训练核心的比率,以实现最大的吞吐量和利用率。
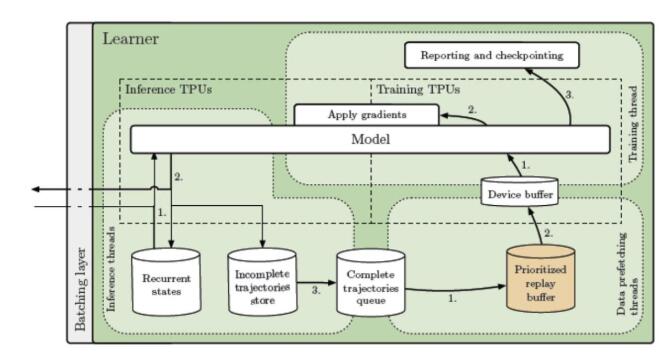
> Source: https://arxiv.org/abs/1910.06591
SEED RL体系结构允许将学习者扩展到成千上万个内核,而参与者的数量也可以扩展到成千上万台机器,以充分利用学习者,从而可以以每秒数百万帧的速度进行训练。鉴于SEED RL基于TensorFlow 2 API,并且TPU加速了其性能。
为了评估SEED RL,Google使用了常见的DRL基准测试环境,例如cade学习环境,DeepMind Lab环境以及最近发布的Google Research Football环境。 在所有环境下的结果都是惊人的。 例如,在DeepMind实验室环境中,SEED RL使用64个Cloud TPU内核达到了每秒240万帧,这比以前的最新分布式代理IMPALA提高了80倍。 还看到了速度和CPU利用率的提高。
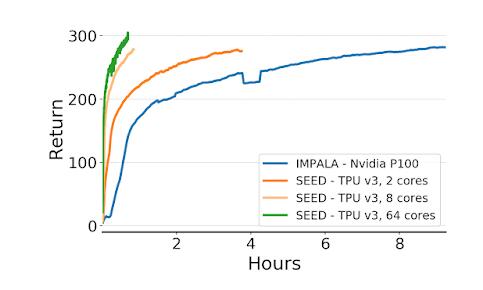
> Source: https://ai.googleblog.com/2020/03/massively-scaling-reinforcement.html
SEED RL代表了可大规模扩展的DRL模型的改进。 Google Research在GitHub上开源了最初的SEED RL体系结构。 我可以想象,在可预见的将来,这将成为许多实际DRL实现的基础模型。