2020 年 11 月 11 日晚,又一年天猫双 11 狂欢接近尾声。新交易纪录、新流量峰值,一切都是十全十美的样子。
图片来自 Pexels
此时,阿里巴巴 CTO 程立(鲁肃)才将一段实录视频公之于众:
11 月 5 日凌晨,阿里技术上下完成双 11 大考期间最后一次全链路压测后休息和交接间隙……服务器连续遭遇了两次攻击。
第一次,凌晨两点左右,监控大屏显示四个地区数据中心数值迅速下跌,技术保障团队启动紧急响应处理,确定遭遇了断网攻击。
紧接着第二次,2:10,更凶猛直接的攻击来了。华东区域某个数据中心,直接被拉闸断了电……
但最令人震惊的是,这一切居然是阿里巴巴合伙人、双 11 新零售技术负责人吴泽明(花名范禹)干的。
突然袭击,实弹攻击
这不是事先明确的一次突袭。
甚至只有范禹和霜波——阿里双 11 技术大队长、技术安全生产负责人陈琴“小范围”知道。
但是即便如此,陈琴看到这次断网攻击时还是吓了一跳,因为与之前商定的攻击量级并不符合。
当时,明面上压测已经结束,参与的阿里技术工程师们,有的在进行夜宵补给,有的在工位上小憩休息,对于这次意料之外的实弹攻击,没有一点点防备。
庆幸的是,技术保障上下训练有序。迅速锁定故障源头,启动应急方案,紧急展开修复……
仅 1 分 28 秒,一切如故。
甚至如果恰好有在那时下单的用户,都难以察觉有过“抖动”。
对于阿里技术上下,虽然事出突然毫无防备,但对于这样的突袭应对,已然肌肉记忆一样……因为在阿里,这种突袭早已普遍而日常,还有专门因此形成的红蓝军对抗。
蓝军负责设计突袭弹药,常在不经意间发起突袭。红军则需要在极短时间内修复故障。
对外,这种技术突袭和红蓝对抗一直不为人知。
对内,无数次突袭和演练之后,连故障恢复机制都形成了“1-5-10”的方法论,即在 1 分钟内发出警报、5 分钟内定位故障、10 分钟内修复故障。
这也是阿里敢将可用性目标提升到达 99.9999% 的底气所在。之所以能如此精确,就是因为一次次突袭演练之后得出的结果。
阿里内部,还将这种红蓝军的偷袭与防守,类比为对系统打疫苗。
故意在可控半径内将故障注入系统以测试系统的响应,类似于将少量有害物质注入体内激发免疫反应以防止未来疾病。
这似乎很疯狂,但能让公司提前为包括宕机在内的各种故障做好准备,将其影响降至最低。
甚至还有更疯狂的举动。阿里为这种突袭专门设计了 App,简化成一个“按钮”,串联了阿里巴巴经济体的各种技术架构和业务手段。
方便随时随地,按下按钮完成突袭。

它可能发生在任何时候,比如,某一次会议结束后所有人都处于放松状态时。
这次双 11 前的突袭攻击,就出现在范禹闲庭信步走出“光明顶”时——双 11 核心作战室内没人察觉异常。
有内部工程师把这种偷袭演练与马斯克 SpaceX 那次知名的“事故逃逸”演习类比。
核心都是以真实可能发生的事故,来实际检验自身的技术和应急保障机制。
你听过混沌工程吗?
Chaos Engineering,混沌工程。
被称为“故意破坏的艺术”,主要通过主动制造故障,测试系统在各种压力下的行为,从而识别并修复故障问题,以此提高生产环境中系统的容错性和可恢复性,最终实现系统弹性的提升。

在硅谷科技公司中,混沌工程已经有过实践。
2010 年,Netflix 团队开发出了 Chaos Monkey——混沌猴子这个工具用于测试系统。
模拟一只讨厌的猴子,在系统中随机位置上蹦下窜,不停捣乱,直到搞挂你的系统。
随后的几年里,Netflix 还将混沌猴子在 GitHub 上开源分享,并指出这种随机故障测试,对测试分布式系统的稳定性有传统方式难以超越的优势。
在这样一整套原理基础上,混沌工程师这样的岗位开始在硅谷出现,角色和功能如这次阿里对外公开的蓝军,把这种随机破坏性攻击,变成一种日常测试手段来提升自身的抗灾能力。
混沌工程是一种专门的理论,本质上是一种反脆弱的思想。
如果再往上追溯,哲学源头可以找到尼采——杀不死我的必使我更强大。
而对于阿里来说,混沌工程思想理念,与技术稳定体系需求不谋而合,与阿里异地多活、容灾容错的发展需求契合在一起。
实际上从 2010 年左右,阿里电商域开始尝试故障注入测试的工作,开始的目标是想解决微服务架构带来的强弱依赖问题。
后来经过多个阶段的改进,最终演进到 MonkeyKing 线上故障演练平台。
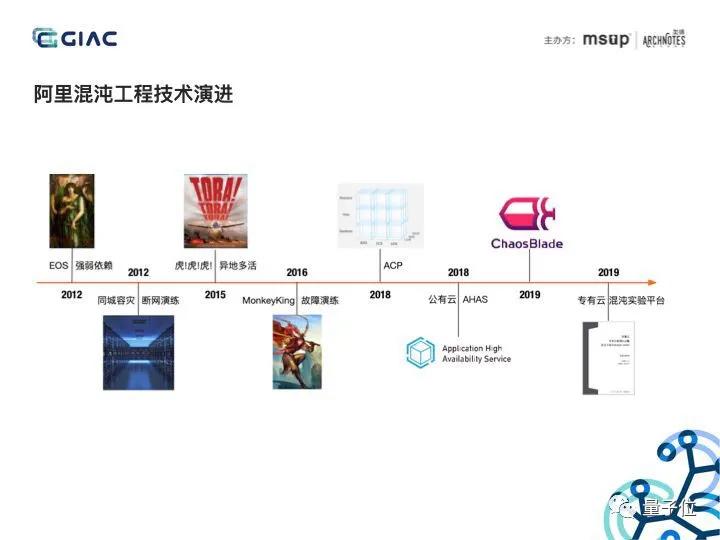
作为阿里集团使用广泛的混沌工程平台,MonkeyKing 不但帮助很多业务团队进行故障演练,提升了业务稳定性,同时也支撑阿里集团内部定期的联合演练活动。
2019 年开始,还开始在小范围生产环境内推进突袭演练,并对外开源了阿里巴巴混沌工程工具 ChaosBlade。
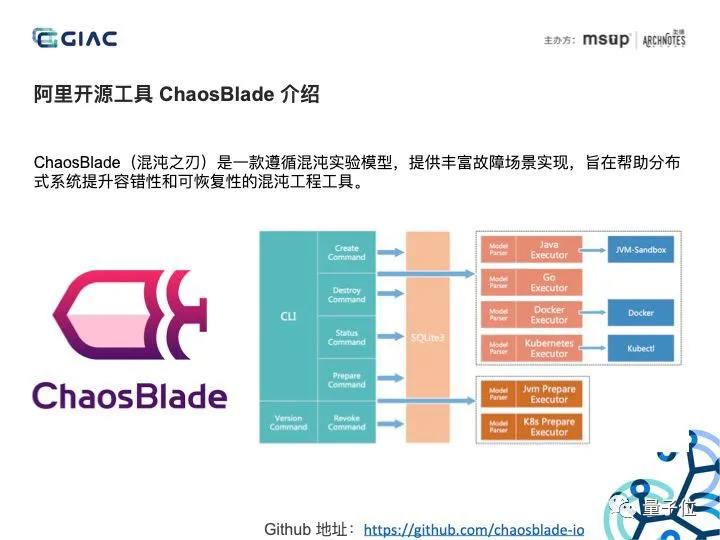
而这次双 11 前夜的突然袭击、断网断电,本质也是混沌工程的一次实践。
即便双 11 这样的节点里,显得异常惊险,但对于阿里来说,拥抱「混沌工程」,搞出「红蓝演练」,也是业务倒逼的结果。
被逼出来的阿里
阿里历史上很多业务改革,都与双 11 密切相关。
比如「异地多活」,起初就是因为双 11 很火,流量带来扩容需求。
阿里集团 CTO 程立就回忆说,2009 年第一次双 11,因为是淘宝商城临时决定搞的活动,技术侧还不太有感觉。

但 2010 年,双 11 流量一下子涨了好几倍,服务器根本不够用……当时在支付宝的程立,亲身经历了把支付宝系统一再瘦身,只留下核心的支付链路,才总算扛过了那次交易洪峰。
而其后对于每年迎来新纪录流量洪峰挑战的双 11,阿里开始在平时倒逼改革。
另外,也有一些意想不到的天灾人祸,带来容灾警醒。
2013 年夏天,因为杭州 40° 高温酷暑,全城电力供应极度紧张,而阿里的服务器机房又是耗电大户,拉闸限电的威胁迫在眉睫,一旦机房停电,业务就关门大吉了……

上述等等经历,让阿里技术意识到,不能再等到下一个高温酷暑的夏天,不能再等到下一次天灾教训,再来思考如何保障业务稳定性。
也不能忽视地域中的物理灾害,影响到线上数以亿计的用户。更不能因为基础设施的限制,阻碍快速增长的业务。
所以先是解决同城多活的挑战,其后又进一步解决异地多活的世界难题。
都是面对问题和挑战,倒逼出来的创新。

实际上,这种倒逼出创新的案例,在阿里发展历史上比比皆是,例如支付宝研发 OceanBase,阿里云研发飞天云操作系统……
当年为了支撑双 11 的流量,支付宝一个不到 100 人的团队,研发出可代替甲骨文数据库的 OceanBase 数据库。
今年,在去年双 11 核心系统 100% 上云后,程立透露——阿里把全副身家性命放到云上,飞天云操作系统、神龙服务器集群、中台等数字新基建还在不断升级,技术的沟沟坎坎几近解决,应对峰值不再是最大技术挑战。
消费者的热情越来越高,倒逼阿里技术持续进化。而混沌工程和突袭计划,也是这种倒逼着进化的一部分。
互联网本身就充满了未知和不确定性,例如高温、洪水、台风、暴雨、地震、雷电等自然灾害以及人为操作失误等种种黑天鹅事件,都可能对业务造成严重打击。
阿里敢在双 11 期间对业务系统发起各种高危故障,这种自信源自成熟的突袭机制,而底气则来自阿里云十年来搭建的灾备体系。
Gartner 就曾预测过,2020 年,90% 的容灾操作会发生在云端。尤其是大型云服务商,数据中心都遍布全球,是企业天然的异地灾备中心。
而阿里云的云灾备能力无疑处于云厂商第一阵营。
阿里云曾率先在业内提出数据中心的“四个不”原则,即不在同一火山地震带,不在同一水系,不在同一电网,不在同一运营商网络出口。这是传统企业所不具备的硬实力。
另一方面,阿里云的灾备能力全面涵盖了网络、数据库、存储等领域,这是能应对各种故障的软实力。
举个栗子,在存储领域,阿里云凭借存储高可用等能力,持续三年入选 Gartner 全球云存储魔力象限,并且被列为全球领导者地位。
所以只有兼具软硬实力,才能最大程度地保障业务和数据稳定安全。这也是阿里敢把全副身家性命都放在云上的原因之一。
甚至这种「最大程度保障」,还需要考虑到被断网断电的极端场景……
所以,拉闸断电的攻击成功了吗?
11 月 5 日凌晨 02:10,阿里华东区域某一数据中心被内部拉闸断电。
瞬间,蓄电系统启动……服务器供能无缝切换,未受一丝影响。
4 秒钟后,柴油发电机群启动。电力完全恢复供应,数据中心运转如常。
阿里云灾备体系,至此交了满分答卷。
混沌工程 ChaosBlade 项目地址:
- https://github.com/chaosblade-io/chaosblade
作者:雷刚
编辑:陶家龙
出处:转载自公众号量子位(ID:QbitAI)