












本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
见过3D物体数据集,见过会动的3D物体数据集吗?

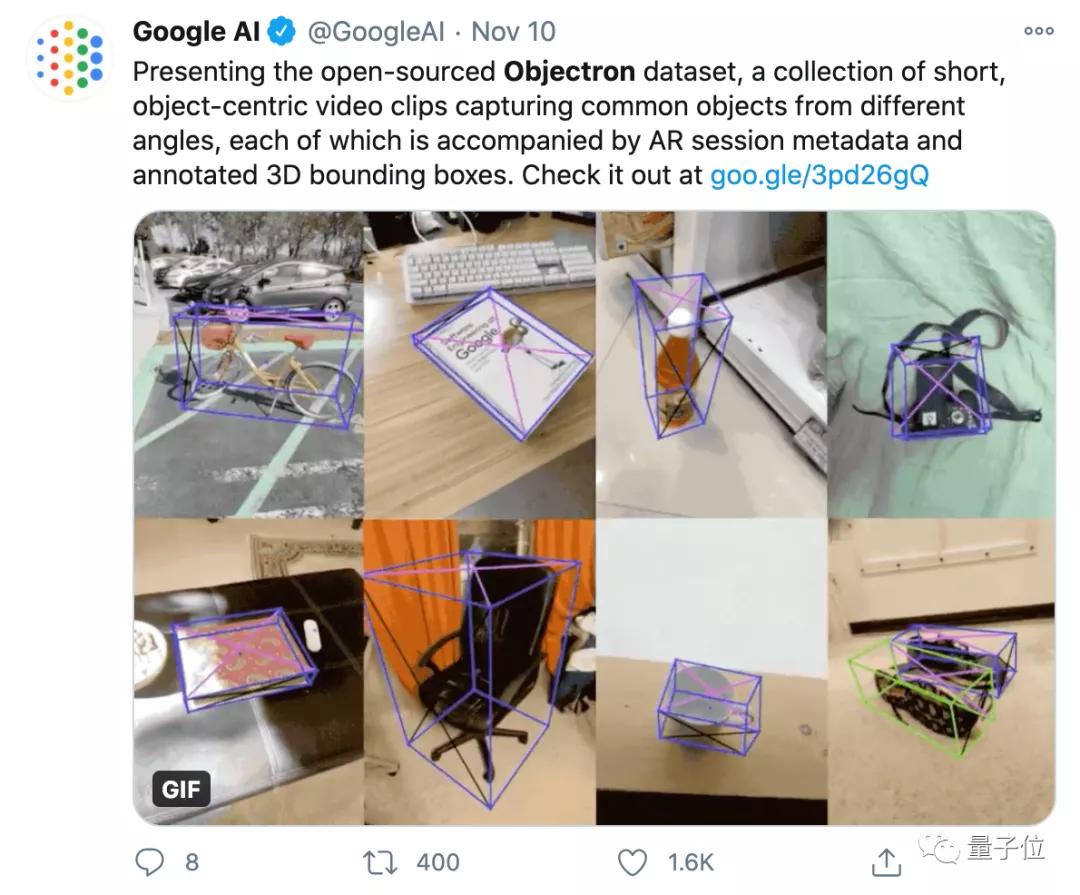
每段动态视频都以目标为中心拍摄,不仅自带标注整体的边界框,每个视频还附带相机位姿和稀疏点云。
这是谷歌的开源3D物体数据集Objectron,包含15000份短视频样本,以及从五个大洲、十个国家里收集来的400多万张带注释的图像。
谷歌认为,3D目标理解领域,缺少像2D中的ImageNet这样的大型数据集,而Objectron数据集能在一定程度上解决这个问题。
数据集一经推出,1.6k网友点赞。
有网友调侃,谷歌恰好在自己想“谷歌”这类数据集的时候,把它发了出来。

也有团队前成员表示,很高兴看到这样的数据集和模型,给AR带来进步的可能。

除此之外,谷歌还公布了用Objectron数据集训练的针对鞋子、椅子、杯子和相机4种类别的3D目标检测模型。
来看看这个数据集包含什么,以及谷歌提供的3D目标检测方案吧~(项目地址见文末)
9类物体,对AR挺友好
目前,这个数据集中包含的3D物体样本,包括自行车,书籍,瓶子,照相机,麦片盒子,椅子,杯子,笔记本电脑和鞋子。

当然,这个数据集,绝不仅仅只是一些以物体为中心拍摄的视频和图像,它具有如下特性:
注释标签(3D目标立体边界框)
用于AR数据的数据(相机位姿、稀疏点云、二维表面)
数据预处理(图像格式为tf.example,视频格式为SequenceExample)
支持通过脚本运行3D IoU指标的评估
支持通过脚本实现Tensorflow、PyTorch、JAX的数据加载及可视化,包含“Hello World”样例
支持Apache Beam,用于处理谷歌云(Google Cloud)基础架构上的数据集
所有可用样本的索引,包括训练/测试部分,便于下载
图像部分的画风,基本是这样的,也标注得非常详细:

而在视频中,不仅有从各个角度拍摄的、以目标为中心的片段(从左到右、从下到上):

也有不同数量的视频类型(一个目标、或者两个以上的目标):

谷歌希望通过发布这个数据集,让研究界能够进一步突破3D目标理解领域,以及相关的如无监督学习等方向的研究应用。
怎么用?谷歌“以身示范”
拿到数据集的第一刻,并不知道它是否好用,而且总感觉有点无从下手?
别担心,这个数据集的训练效果,谷歌已经替我们试过了。
看起来还不错:

此外,谷歌将训练好的3D目标检测模型,也一并给了出来。(传送见文末)
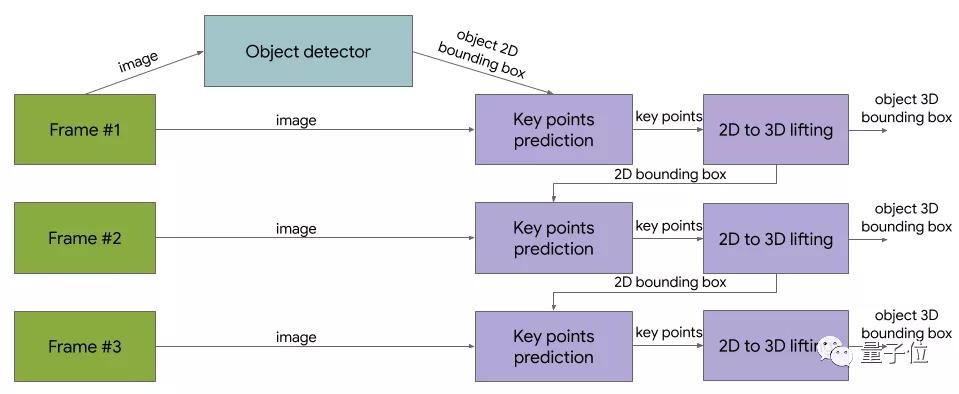
算法主要包括两部分,第一部分是Tensorflow的2D目标检测模型,用来“发现物体的位置”;
第二部分则进行图像裁剪,来估计3D物体的边界框(同时计算目标下一帧的2D裁剪,因此不需要运行每个帧),整体结构如下图:
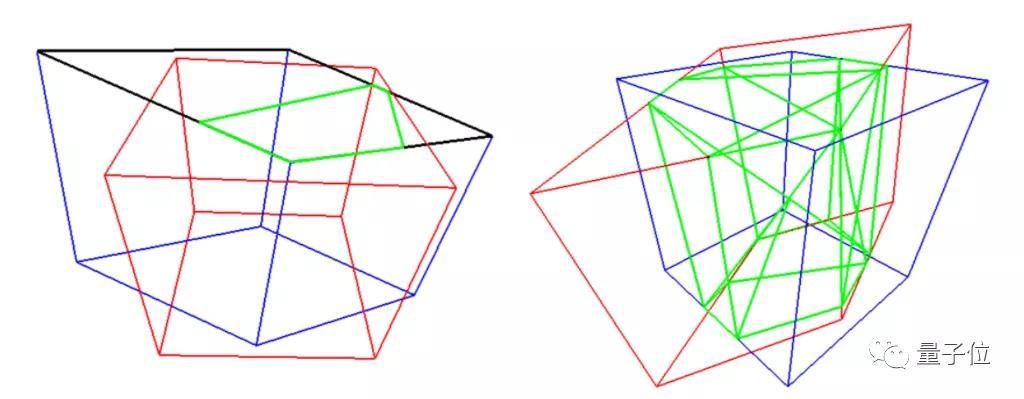
在模型的评估上,谷歌采用了Sutherland-Hodgman多边形裁剪算法,来计算两个立体边界框的交点,并计算出两个立方体的相交体积,最终计算出3D目标检测模型的IoU。
简单来说,两个立方体重叠体积越大,3D目标检测模型效果就越好。
这个模型是谷歌推出的MediaPipe中的一个部分,后者是一个开源的跨平台框架,用于构建pipeline,以处理不同形式的感知数据。

它推出的MediaPipe Objectron实时3D目标检测模型,用移动设备(手机)就能进行目标实时检测。
看,(他们玩得多欢快)实时目标检测的效果还不错:

其他部分3D数据集
除了谷歌推出的数据集以外,此前视觉3D目标领域,也有许多类型不同的数据集,每个数据集都有自己的特点。
例如斯坦福大学等提出的ScanNetV2,是个室内场景数据集,而ScanNet则是个RGB-D视频数据集,一共有21个目标类,一共1513个采集场景数据,可做语义分割和目标检测任务。

而目前在自动驾驶领域非常热门的KITTI数据集,也是一个3D数据集,是目前最大的自动驾驶场景下计算机视觉的算法评测数据集,包含市区、乡村和高速公路等场景采集的真实图像数据。

此外,还有Waymo、SemanticKITTI、H3D等等数据集,也都用在不同的场景中。(例如SemanticKITTI,通常被专门用于自动驾驶的3D语义分割)
无论是视频还是图像,这些数据集的单个样本基本包含多个目标,使用场景上也与谷歌的Objectron有所不同。
感兴趣的小伙伴们,可以通过下方传送门,浏览谷歌最新的3D目标检测数据集,以及相关模型~
Objectron数据集传送门:
https://github.com/google-research-datasets/Objectron/
针对4种物体的3D目标检测模型:
https://google.github.io/mediapipe/solutions/objectron




















