












之前写了两篇文章,都是针对Linux这个系统的,为什么?我为什么这么喜欢写这个系统的知识,可能就是为了今天的内容多线程系列,现在多线程不是一个面试重点 啊,那如果你能深入系统内核回答这个知识点,面试官会怎么想?你会不会占据面试的主动权(我不会说今天被一个面试者惊艳到了的)今天,我就开始一个系列的内容,多线程--高并发,深入的给大家讲解,我就不信讲不明白这么个小东西,有问题的地方希望大家能够指出,谢谢,大家一起成长
今天我们将第一个知识点:进程
Linux 内核如何描述一个进程?
1. Linux 的进程
进程的术语是 process,是 Linux 最基础的抽象,另一个基础抽象是文件。
最简单的理解,进程就是执行中 (executing, 不等于running) 的程序。
更准确一点的理解,进程包括执行中的程序以及相关的资源 (包括cpu状态、打开的文件、挂起的信号、tty、内存地址空间等)。
一种简洁的说法:进程 = n*执行流 + 资源,n>=1。
Linux 进程的特点:
- 通过系统调用 fork() 创建进程,fork() 会复制现有进程来创建一个全新的进程。
- 内核里,并不严格区分进程和线程。
- 从内核的角度看,调度单位是线程 (即执行流)。可以把线程看做是进程里的一条执行流,1个进程里可以有1个或者多个线程。
- 内核里,常把进程称为 task 或者 thread,这样描述更准确,因为许多进程就只有1条执行流。
- 内核通过轻量级进程 (lightweight process) 来支持多线程。1个轻量级进程就对应1个线程,轻量级进程之间可以共享打开的文件、地址空间等资源。
2. Linux 的进程描述符
2.1 task_struct
内核里,通过 task_struct 结构体来描述一个进程,称为进程描述符 (process descriptor),它保存着支撑一个进程正常运行的所有信息。
每一个进程,即便是轻量级进程(即线程),都有1个 task_struct。
- sched.h (include\linux)
- struct task_struct {
- struct thread_info thread_info;
- volatile long state;
- void *stack;
- [...]
- struct mm_struct *mm;
- [...]
- pid_t pid;
- [...]
- struct task_struct *parent;
- [...]
- char comm[TASK_COMM_LEN];
- [...]
- struct files_struct *files;
- [...]
- struct signal_struct *signal;
- }
这是一个庞大的结构体,不仅有许多进程相关的基础字段,还有许多指向其他数据结构的指针。
它包含的字段能完整地描述一个正在执行的程序,包括 cpu 状态、打开的文件、地址空间、挂起的信号、进程状态等。
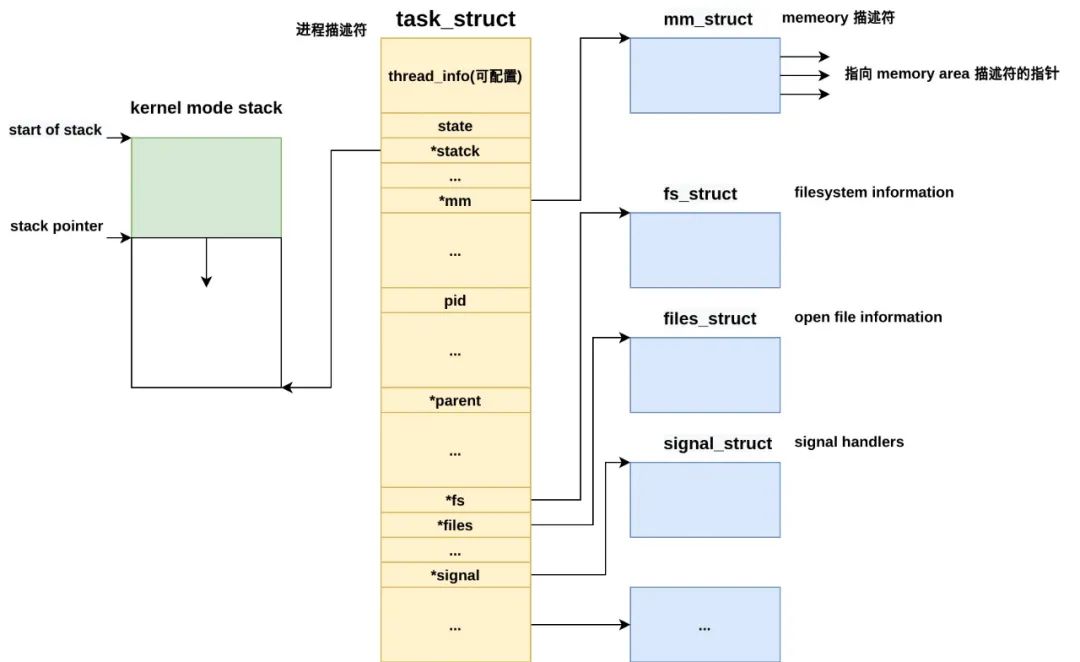
作为初学者,先简单地了解部分字段就好::
- struct thread_info thread_info: 进程底层信息,平台相关,下面会详细描述。
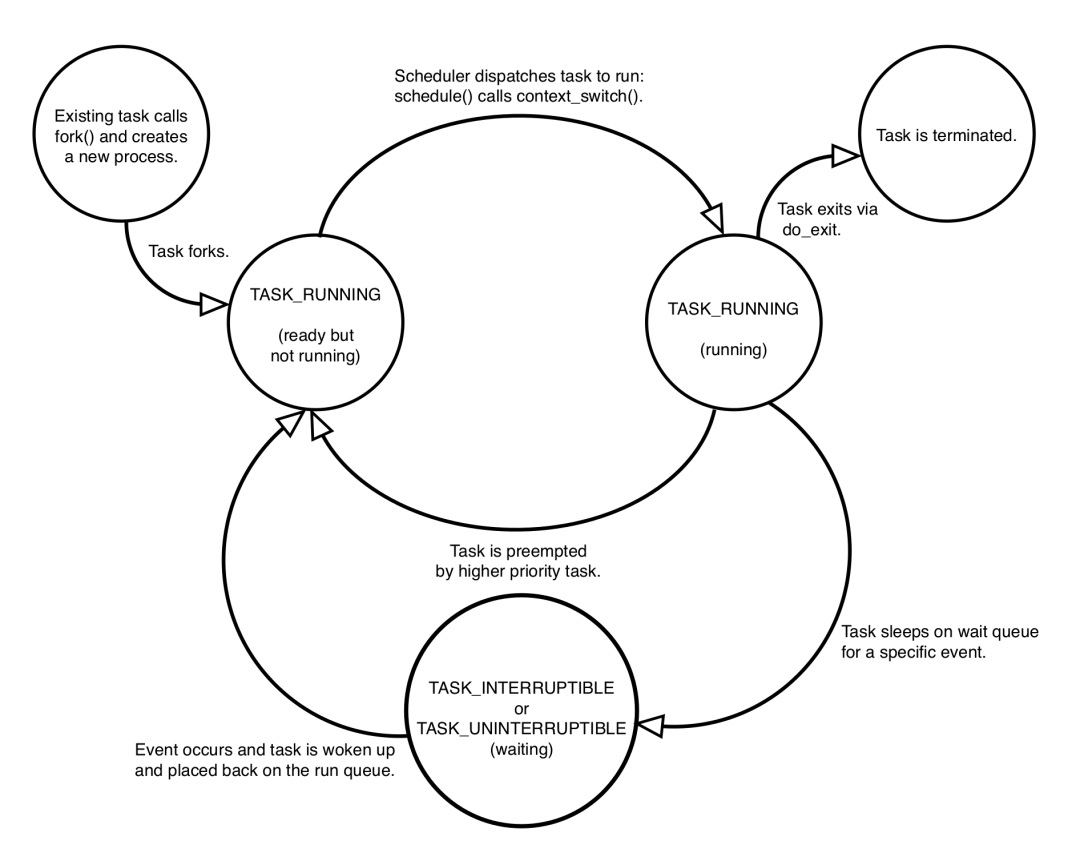
- long state: 进程当前的状态,下面是几个比较重要的进程状态以及它们之间的转换流程。
- void *stack: 指向进程内核栈,下面会解释。
- struct mm_struct *mm: 与进程地址空间相关的信息都保存在一个叫内存描述符 (memory descriptor) 的结构体 (mm_struct) 中。
pid_t pid: 进程标识符,本质就是一个数字,是用户空间引用进程的唯一标识。
- struct task_struct *parent: 父进程的 task_struct。
- char comm[TASK_COMM_LEN]: 进程的名称。
- struct files_struct *files: 打开的文件表。
- struct signal_struct *signal: 信号处理相关。
其他字段,等到有需要的时候再回过头来学习。
2.2 当发生系统调用或者进程切换时,内核如何找到 task_struct ?
对于 ARM 架构,答案是:通过内核栈 (kernel mode stack)。
为什么要有内核栈?
因为内核是可重入的,在内核中会有多条与不同进程相关联的执行路径。因此不同的进程处于内核态时,都需要有自己私有的进程内核栈 (process kernel stack)。
当进程从用户态切换到内核态时,所使用的栈会从用户栈切换到内核栈。
至于是如何切换的,关键词是系统调用,这不是本文关注的重点,先放一边,学习内核要懂得恰当的时候忽略细节。
当发生进程切换时,也会切换到目标进程的内核栈。
同上,关键词是硬件上下文切换 (hardware context switch),忽略具体实现。
无论何时,只要进程处于内核态,就会有内核栈可以使用,否则系统就离崩溃不远了。
ARM 架构的内核栈和 task_struct 的关系如下:
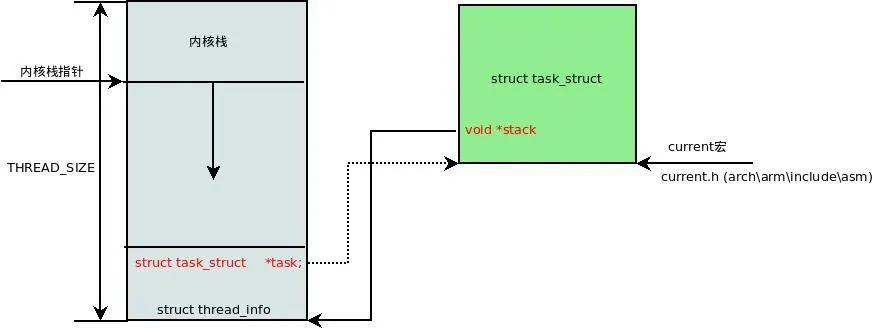
内核栈的长度是 THREAD_SIZE,对于 ARM 架构,一般是 2 个页框的大小,即 8KB。
内核将一个较小的数据结构 thread_info 放在内核栈的底部,它负责将内核栈和 task_struct 串联起来。thread_info 是平台相关的,在 ARM 架构中的定义如下:
- // thread_info.h (arch\arm\include\asm)
- struct thread_info {
- unsigned long flags; /* low level flags */
- int preempt_count; /* 0 => preemptable, <0 => bug */
- mm_segment_t addr_limit; /* address limit */
- struct task_struct *task; /* main task structure */
- [...]
- struct cpu_context_save cpu_context; /* cpu context */
- [...]
- };
thread_info 保存了一个进程能被调度执行的最底层信息(low level task data),例如struct cpu_context_save cpu_context 会在进程切换时用来保存/恢复寄存器上下文。
内核通过内核栈的栈指针可以快速地拿到 thread_info:
- // thread_info.h (include\linux)
- static inline struct thread_info *current_thread_info(void)
- {
- // current_stack_pointer 是当前进程内核栈的栈指针
- return (struct thread_info *)
- (current_stack_pointer & ~(THREAD_SIZE - 1));
- }
- 然后通过 thread_info 找到 task_struct:
- // current.h (include\asm-generic)
- #define current (current_thread_info()->task)
内核里通过 current 宏可以获得当前进程的 task_struct。
2.3 task_struct 的分配和初始化
当上层应用使用 fork() 创建进程时,内核会新建一个 task_struct。
进程的创建是个复杂的工作,可以延伸出无数的细节。这里我们只是简单地了解一下 task_struct 的分配和部分初始化的流程。
fork() 在内核里的核心流程:
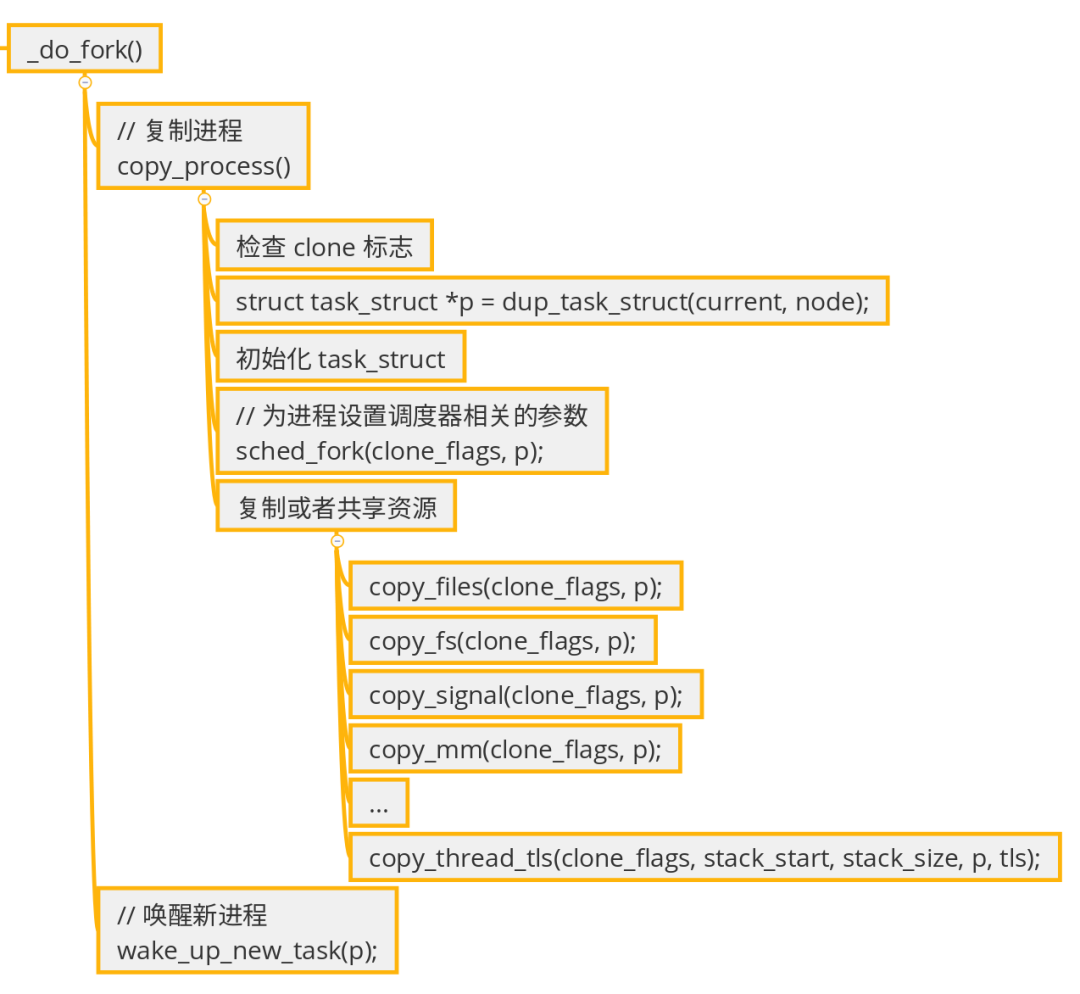
dup_task_struct() 做了什么?

至于设置内核栈里做了什么,涉及到了进程的创建与切换,不在本文的关注范围内,以后再研究了。
3. 实验:打印 task_struct / thread_info / kernel mode stack
实验目的:
- 梳理 task_struct / thread_info / kernel mode stack 的关系。
实验代码:
- 实验代码:
- #include <linux/init.h>
- #include <linux/module.h>
- #include <linux/sched.h>
- static void print_task_info(struct task_struct *task)
- {
- printk(KERN_NOTICE "%10s %5d task_struct (%p) / stack(%p~%p) / thread_info->task (%p)",
- task->comm,
- task->pid,
- task,
- task->stack,
- ((unsigned long *)task->stack) + THREAD_SIZE,
- task_thread_info(task)->task);
- }
- static int __init task_init(void)
- {
- struct task_struct *task = current;
- printk(KERN_INFO "task module init\n");
- print_task_info(task);
- do {
- task = task->parent;
- print_task_info(task);
- } while (task->pid != 0);
- return 0;
- }
- module_init(task_init);
- static void __exit task_exit(void)
- {
- printk(KERN_INFO "task module exit\n ");
- }
- module_exit(task_exit);
运行效果:
- task module init
- insmod 3123 task_struct (edb42580) / stack(ed46c000~ed474000) / thread_info->task (edb42580)
- bash 2393 task_struct (eda13e80) / stack(c9dda000~c9de2000) / thread_info->task (eda13e80)
- sshd 2255 task_struct (ee5c9f40) / stack(c9d2e000~c9d36000) / thread_info->task (ee5c9f40)
- sshd 543 task_struct (ef15f080) / stack(ee554000~ee55c000) / thread_info->task (ef15f080)
- systemd 1 task_struct (ef058000) / stack(ef04c000~ef054000) / thread_info->task (ef058000)
在程序里,我们通过 task_struct 找到 stack,然后通过 stack 找到 thread_info,最后又通过 thread_info->task 找到 task_struct。
到这里,不知道你对进程的概念是不是有了一个清晰的理解
但是上面是通过Linux进行了线程的展示,在日常的工作中,代码的实现和编写我们还是以Java为主,那我们来看一下Java进程
1.Java进程的创建
Java提供了两种方法用来启动进程或其它程序:
- 使用Runtime的exec()方法
- 使用ProcessBuilder的start()方法
1.1 ProcessBuilder
ProcessBuilder类是J2SE 1.5在java.lang中新添加的一个新类,此类用于创建操作系统进程,它提供一种启动和管理进程(也就是应用程序)的方法。在J2SE 1.5之前,都是由Process类处来实现进程的控制管理。
每个 ProcessBuilder 实例管理一个进程属性集。start() 方法利用这些属性创建一个新的 Process 实例。start() 方法可以从同一实例重复调用,以利用相同的或相关的属性创建新的子进程。
每个进程生成器管理这些进程属性:
- 命令 是一个字符串列表,它表示要调用的外部程序文件及其参数(如果有)。在此,表示有效的操作系统命令的字符串列表是依赖于系统的。例如,每一个总体变量,通常都要成为此列表中的元素,但有一些操作系统,希望程序能自己标记命令行字符串——在这种系统中,Java 实现可能需要命令确切地包含这两个元素。
- 环境 是从变量 到值 的依赖于系统的映射。初始值是当前进程环境的一个副本(请参阅 System.getenv())。
- 工作目录。默认值是当前进程的当前工作目录,通常根据系统属性 user.dir 来命名。
- redirectErrorStream 属性。最初,此属性为 false,意思是子进程的标准输出和错误输出被发送给两个独立的流,这些流可以通过 Process.getInputStream() 和 Process.getErrorStream() 方法来访问。如果将值设置为 true,标准错误将与标准输出合并。这使得关联错误消息和相应的输出变得更容易。在此情况下,合并的数据可从 Process.getInputStream() 返回的流读取,而从 Process.getErrorStream() 返回的流读取将直接到达文件尾。
修改进程构建器的属性将影响后续由该对象的 start() 方法启动的进程,但从不会影响以前启动的进程或 Java 自身的进程。大多数错误检查由 start() 方法执行。可以修改对象的状态,但这样 start() 将会失败。例如,将命令属性设置为一个空列表将不会抛出异常,除非包含了 start()。
注意,此类不是同步的。如果多个线程同时访问一个 ProcessBuilder,而其中至少一个线程从结构上修改了其中一个属性,它必须 保持外部同步。
构造方法摘要
- ProcessBuilder(List command)
- 利用指定的操作系统程序和参数构造一个进程生成器。
- ProcessBuilder(String... command)
- 利用指定的操作系统程序和参数构造一个进程生成器。
方法摘要
- List command()
- 返回此进程生成器的操作系统程序和参数。
- ProcessBuilder command(List command)
- 设置此进程生成器的操作系统程序和参数。
- ProcessBuilder command(String... command)
- 设置此进程生成器的操作系统程序和参数。
- File directory()
- 返回此进程生成器的工作目录。
- ProcessBuilder directory(File directory)
- 设置此进程生成器的工作目录。
- Map environment()
- 返回此进程生成器环境的字符串映射视图。
- boolean redirectErrorStream()
- 通知进程生成器是否合并标准错误和标准输出。
- ProcessBuilder redirectErrorStream(boolean redirectErrorStream)
- 设置此进程生成器的 redirectErrorStream 属性。
- Process start()
- 使用此进程生成器的属性启动一个新进程。
1.2 Runtime
每个 Java 应用程序都有一个 Runtime 类实例,使应用程序能够与其运行的环境相连接。可以通过 getRuntime 方法获取当前运行时。
应用程序不能创建自己的 Runtime 类实例。但可以通过 getRuntime 方法获取当前Runtime运行时对象的引用。一旦得到了一个当前的Runtime对象的引用,就可以调用Runtime对象的方法去控制Java虚拟机的状态和行为。
Java代码 收藏代码
- void addShutdownHook(Thread hook)
- 注册新的虚拟机来关闭挂钩。
- int availableProcessors()
- 向 Java 虚拟机返回可用处理器的数目。
- Process exec(String command)
- 在单独的进程中执行指定的字符串命令。
- Process exec(String[] cmdarray)
- 在单独的进程中执行指定命令和变量。
- Process exec(String[] cmdarray, String[] envp)
- 在指定环境的独立进程中执行指定命令和变量。
- Process exec(String[] cmdarray, String[] envp, File dir)
- 在指定环境和工作目录的独立进程中执行指定的命令和变量。
- Process exec(String command, String[] envp)
- 在指定环境的单独进程中执行指定的字符串命令。
- Process exec(String command, String[] envp, File dir)
- 在有指定环境和工作目录的独立进程中执行指定的字符串命令。
- void exit(int status)
- 通过启动虚拟机的关闭序列,终止当前正在运行的 Java 虚拟机。
- long freeMemory()
- 返回 Java 虚拟机中的空闲内存量。
- void gc()
- 运行垃圾回收器。
- InputStream getLocalizedInputStream(InputStream in)
- 已过时。 从 JDK 1.1 开始,将本地编码字节流转换为 Unicode 字符流的首选方法是使用 InputStreamReader 和 BufferedReader 类。
- OutputStream getLocalizedOutputStream(OutputStream out)
- 已过时。 从 JDK 1.1 开始,将 Unicode 字符流转换为本地编码字节流的首选方法是使用 OutputStreamWriter、BufferedWriter 和 PrintWriter 类。
- static Runtime getRuntime()
- 返回与当前 Java 应用程序相关的运行时对象。
- void halt(int status)
- 强行终止目前正在运行的 Java 虚拟机。
- void load(String filename)
- 加载作为动态库的指定文件名。
- void loadLibrary(String libname)
- 加载具有指定库名的动态库。
- long maxMemory()
- 返回 Java 虚拟机试图使用的最大内存量。
- boolean removeShutdownHook(Thread hook)
- 取消注册某个先前已注册的虚拟机关闭挂钩。
- void runFinalization()
- 运行挂起 finalization 的所有对象的终止方法。
- static void runFinalizersOnExit(boolean value)
- 已过时。 此方法本身具有不安全性。它可能对正在使用的对象调用终结方法,而其他线程正在操作这些对象,从而导致不正确的行为或死锁。
- long totalMemory()
- 返回 Java 虚拟机中的内存总量。
- void traceInstructions(boolean on)
- 启用/禁用指令跟踪。
- void traceMethodCalls(boolean on)
- 启用/禁用方法调用跟踪。
1.3 Process
不管通过哪种方法启动进程后,都会返回一个Process类的实例代表启动的进程,该实例可用来控制进程并获得相关信息。Process 类提供了执行从进程输入、执行输出到进程、等待进程完成、检查进程的退出状态以及销毁(杀掉)进程的方法:
- void destroy()
- 杀掉子进程。
- 一般情况下,该方法并不能杀掉已经启动的进程,不用为好。
- int exitValue()
- 返回子进程的出口值。
- 只有启动的进程执行完成、或者由于异常退出后,exitValue()方法才会有正常的返回值,否则抛出异常。
- InputStream getErrorStream()
- 获取子进程的错误流。
- 如果错误输出被重定向,则不能从该流中读取错误输出。
- InputStream getInputStream()
- 获取子进程的输入流。
- 可以从该流中读取进程的标准输出。
- OutputStream getOutputStream()
- 获取子进程的输出流。
- 写入到该流中的数据作为进程的标准输入。
- int waitFor()
- 导致当前线程等待,如有必要,一直要等到由该 Process 对象表示的进程已经终止。
2.多进程编程实例
一般我们在java中运行其它类中的方法时,无论是静态调用,还是动态调用,都是在当前的进程中执行的,也就是说,只有一个java虚拟机实例在运行。而有的时候,我们需要通过java代码启动多个java子进程。这样做虽然占用了一些系统资源,但会使程序更加稳定,因为新启动的程序是在不同的虚拟机进程中运行的,如果有一个进程发生异常,并不影响其它的子进程。
在Java中我们可以使用两种方法来实现这种要求。最简单的方法就是通过Runtime中的exec方法执行java classname。如果执行成功,这个方法返回一个Process对象,如果执行失败,将抛出一个IOException错误。下面让我们来看一个简单的例子。
- // Test1.java文件
- import java.io.*;
- public class Test
- {
- public static void main(String[] args)
- {
- FileOutputStream fOut = new FileOutputStream("c:\\Test1.txt");
- fOut.close();
- System.out.println("被调用成功!");
- }
- }
- // Test_Exec.java
- public class Test_Exec
- {
- public static void main(String[] args)
- {
- Runtime run = Runtime.getRuntime();
- Process p = run.exec("java test1");
- }
- }
通过java Test_Exec运行程序后,发现在C盘多了个Test1.txt文件,但在控制台中并未出现"被调用成功!"的输出信息。因此可以断定,Test已经被执行成功,但因为某种原因,Test的输出信息未在Test_Exec的控制台中输出。这个原因也很简单,因为使用exec建立的是Test_Exec的子进程,这个子进程并没有自己的控制台,因此,它并不会输出任何信息。
如果要输出子进程的输出信息,可以通过Process中的getInputStream得到子进程的输出流(在子进程中输出,在父进程中就是输入),然后将子进程中的输出流从父进程的控制台输出。具体的实现代码如下如示:
- // Test_Exec_Out.java
- import java.io.*;
- public class Test_Exec_Out
- {
- public static void main(String[] args)
- {
- Runtime run = Runtime.getRuntime();
- Process p = run.exec("java test1");
- BufferedInputStream in = new BufferedInputStream(p.getInputStream());
- BufferedReader br = new BufferedReader(new InputStreamReader(in));
- String s;
- while ((s = br.readLine()) != null)
- System.out.println(s);
- }
- }
从上面的代码可以看出,在Test_Exec_Out.java中通过按行读取子进程的输出信息,然后在Test_Exec_Out中按每行进行输出。 上面讨论的是如何得到子进程的输出信息。那么,除了输出信息,还有输入信息。既然子进程没有自己的控制台,那么输入信息也得由父进程提供。我们可以通过Process的getOutputStream方法来为子进程提供输入信息(即由父进程向子进程输入信息,而不是由控制台输入信息)。我们可以看看如下的代码:
- // Test2.java文件
- import java.io.*;
- public class Test
- {
- public static void main(String[] args)
- {
- BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
- System.out.println("由父进程输入的信息:" + br.readLine());
- }
- }
- // Test_Exec_In.java
- import java.io.*;
- public class Test_Exec_In
- {
- public static void main(String[] args)
- {
- Runtime run = Runtime.getRuntime();
- Process p = run.exec("java test2");
- BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(p.getOutputStream()));
- bw.write("向子进程输出信息");
- bw.flush();
- bw.close(); // 必须得关闭流,否则无法向子进程中输入信息
- // System.in.read();
- }
- }
从以上代码可以看出,Test1得到由Test_Exec_In发过来的信息,并将其输出。当你不加bw.flash()和bw.close()时,信息将无法到达子进程,也就是说子进程进入阻塞状态,但由于父进程已经退出了,因此,子进程也跟着退出了。如果要证明这一点,可以在最后加上System.in.read(),然后通过任务管理器(在windows下)查看java进程,你会发现如果加上bw.flush()和bw.close(),只有一个java进程存在,如果去掉它们,就有两个java进程存在。这是因为,如果将信息传给Test2,在得到信息后,Test2就退出了。在这里有一点需要说明一下,exec的执行是异步的,并不会因为执行的某个程序阻塞而停止执行下面的代码。因此,可以在运行test2后,仍可以执行下面的代码。
exec方法经过了多次的重载。上面使用的只是它的一种重载。它还可以将命令和参数分开,如exec("java.test2")可以写成exec("java", "test2")。exec还可以通过指定的环境变量运行不同配置的java虚拟机。
除了使用Runtime的exec方法建立子进程外,还可以通过ProcessBuilder建立子进程。ProcessBuilder的使用方法如下:
- // Test_Exec_Out.java
- import java.io.*;
- public class Test_Exec_Out
- {
- public static void main(String[] args)
- {
- ProcessBuilder pb = new ProcessBuilder("java", "test1");
- Process p = pb.start();
- … …
- }
- }
在建立子进程上,ProcessBuilder和Runtime类似,不同的ProcessBuilder使用start()方法启动子进程,而Runtime使用exec方法启动子进程。得到Process后,它们的操作就完全一样的。
ProcessBuilder和Runtime一样,也可设置可执行文件的环境信息、工作目录等。下面的例子描述了如何使用ProcessBuilder设置这些信息。
- ProcessBuilder pb = new ProcessBuilder("Command", "arg2", "arg2", ''');
- // 设置环境变量
- Map<String, String> env = pb.environment();
- env.put("key1", "value1");
- env.remove("key2");
- env.put("key2", env.get("key1") + "_test");
- pb.directory("..\abcd"); // 设置工作目录
- Process p = pb.start(); // 建立子进程















