摘要
代码生成将程序描述映射到可执行文件编程语言的源代码。现有方法主要依靠递归神经网络(RNN)编码器。但是,我们发现一个程序包含比自然语言句子更多的标记,因此它可能不适合 RNN 捕获如此长的序列。在本文提出了一种基于语法的结构卷积用于代码生成的传统神经网络(CNN)。我们的模型通过预测语法规则来生成程序编程语言;我们设计了多个 CNN 模块,包括基于树的卷积和预卷积,其信息将由专门的参与者进一步汇总-活动池层。《炉石传说》的实验结果基准数据集显示,我们的 CNN 代码生成器明显比以前的最新方法高 5 个百分比;在几个语义解析任务上的其他实验证明了我们模型的鲁棒性。我们还进行深入的消融测试,以更好地了解每个模型的组成部分。
介绍
根据自然语言描述生成代码是一种人工智能中艰巨而艰巨的任务。对 var-应用程序。例如,程序员想在 Python 中“打开文件,F1”,但不知道如何用编程语言来实现,他可以获得目标代码“f=open('F1','r')”通过代码生成。随着深度学习的繁荣,编解码器框架成为流行的序列生成方法联盟。特别是递归神经网络(RNN)通常用作编码器和解码器;这样的建筑师也称为序列到序列(Seq2Seq)模型。当应用于代码生成,它将程序描述作为输入放置序列并生成所需的代码作为输出序列。
在深度学习社区中,研究人员正在展示对使用卷积神经网络的兴趣日益浓厚(CNN)作为解码器,因为它的效率高且容易训练的精神。我们进一步观察到,一个程序大于自然语言的句子,而 RNN 则是即使有很长的短期记忆。相反,CNN 能够有效地捕获不同位置的特征通过滑动窗口区域。
为此,我们提出了一种基于语法的结构 CNN 用于代码生成。我们的模型通过 AST 中的语法构造规则,例如 If→exprstmtstmt,遵循我们之前的框架工作。由于子节点的顺序是通过一个预测步骤生成的,它可以使更多的契约预测比逐 token 生成。其他换句话说,我们的模型会预测语法规则的顺序,最终形成一个完整的程序。
在我们的方法中,语法规则的预测是主要基于三种类型的信息:指定要生成的程序的频率先前预测的语法规则,以及部分 AST 已生成。在这里,前一个是编码器。后两者使模型能够自回归解码器,并且像往常一样,解码器还取决于编码器。我们为结构设计了几个不同的组件适用于程序生成的 CNN:(1)我们首先采用应用滑动窗口的基于树的卷积思想在 AST 结构上。然后我们设计另一个 CNN 模块,用于对节点中的节点进行遍历部分 AST。这两种 CNN 捕获邻居-不仅在序列中而且在树中获取信息结构体。(2)为了增强“自回归”,我们应用了-其他 CNN 模块到要生成的节点的祖先安装,因此网络知道在哪里生成在某个步骤。(3)我们设计了一个专心的集中池聚合与 CNN 互动的机制不同的神经模块。特别是,我们发现它对考虑范围名称(例如,函数和方法名称)在代码生成过程中,请使用诸如几个细心的池化层的 troller。
我们根据既定基准进行了实验数据集《炉石传说》,用于 python 代码生成。实验结果表明,我们基于 CNN 代码生成器的性能优于以前的 RNN 方法很大程度上。我们在两个方面进一步评估了我们的方法 Mantic 解析任务,其中目标程序较短比《炉石传说》;我们的方法也取得了可比性结果与先前的最新方法一致,表明我们方法的鲁棒性。我们进行了广泛的消融测试,表明我们基于语法的结构设计 CNN 比单纯使用 CNN 更好。
模型
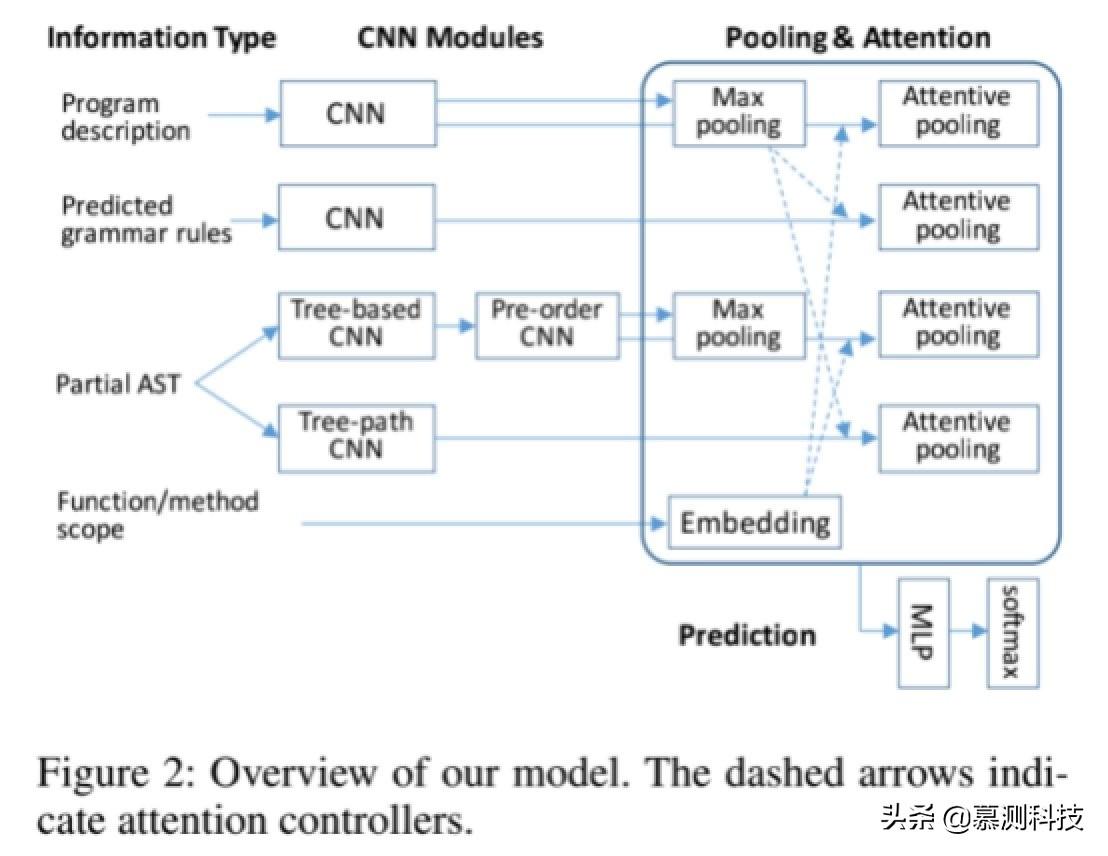
图 2 显示了我们网络的整体结构。我们会首先描述基于语法的代码生成过程,然后详细介绍每个模块。
基于语法的代码生成
对于程序说明的输入,我们的任务是生成一个符合描述的一段可执行代码。在传统的 Seq2Seq 模型中,可以表示一个程序作为 token 序列 x1,x2,···,xT,这些 token 是按顺序生成。
另外,有效的程序可以用抽象语法树(AST)。叶节点是表示为 x 终端的符号,x1,x2,···,xT。非叶节点是非终端符号 n1,···,nN,每个表示程序的抽象组件(例如,If 块)。此外,子节点 n1,···,nk 源自它们的父节点 p 是通过应用一些语法规则 r 获得的,表示为 p→n1···nk。在我们的工作中,不同的叶子节点用户定义的变量被视为单独的语法通过检查训练集来确定规则。我们以深度优先的顺序遍历树,对于首先遇到非终结符,我们预测什么规则应该用来扩展它。换句话说,概率程序的分解为
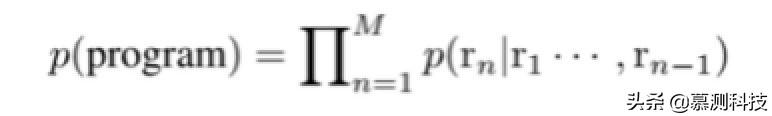
尽管典型的编程语言包含更多内容语法规则比不同的 AST 节点多,基于语法生成更加紧凑,因为子节点 c1,···,ck 通过对规则的单个预测而就位 p→c1···ck。而且,生成的程序保证在语法上正确。在本节的其余部分,我们将介绍 CNN 编码器-解码器模型,用于预测语法规则。
输入的 CNN
我们模型的输入是一段描述,它指定要生成的程序。用于卡片的代码生成在《炉石传说》中,输入是半结构化数据,包含图示卡片的名称,属性和说明在图 4 中。对于其他任务,例如语义解析,则输入可能是自然的量词句。
形式上,提取的特征可以被计算
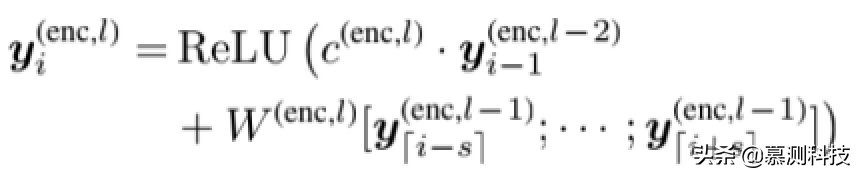
其中,W(enc,l)是编码器的卷积权重 CNN,s 由 s=(k−1)/2 计算,k 是窗口大小(在我们的实验中设置为 2),并且 l=1,···,L 表示 CNN 的深层。特别是 y(enc,0)是输入嵌入 x(enc)。c(enc,l)=1 表示偶数层,0 表示奇数层层,指示是否存在以下快捷方式连接这一层。对于第一个和最后几个词,我们执行零填充。
预测规则的 CNN
我们跟踪所有之前的规则,并建立一个深度神经网络来提取此类信息信息。
令 r1,...,rn-1 为先前预测的规则。我们将它们嵌入为实值向量 r1,···,rn-1,其中嵌入是随机初始化的,可以通过反向学习传播。我们应用带有快捷方式连接的深层 CNN 模块规则嵌入 r1,···,rn-1 的注释,提取特征 y。
预测的语法规则完全指定生成的(部分)程序以紧凑的方式,这是有益的用于精确的代码生成。
但是,仅向解码器提供预规定的自回归规则,因为它们没有提供该程序的具体/图片视图。为了减轻这个问题,我们增强了解码器部分 AST,如下所述。
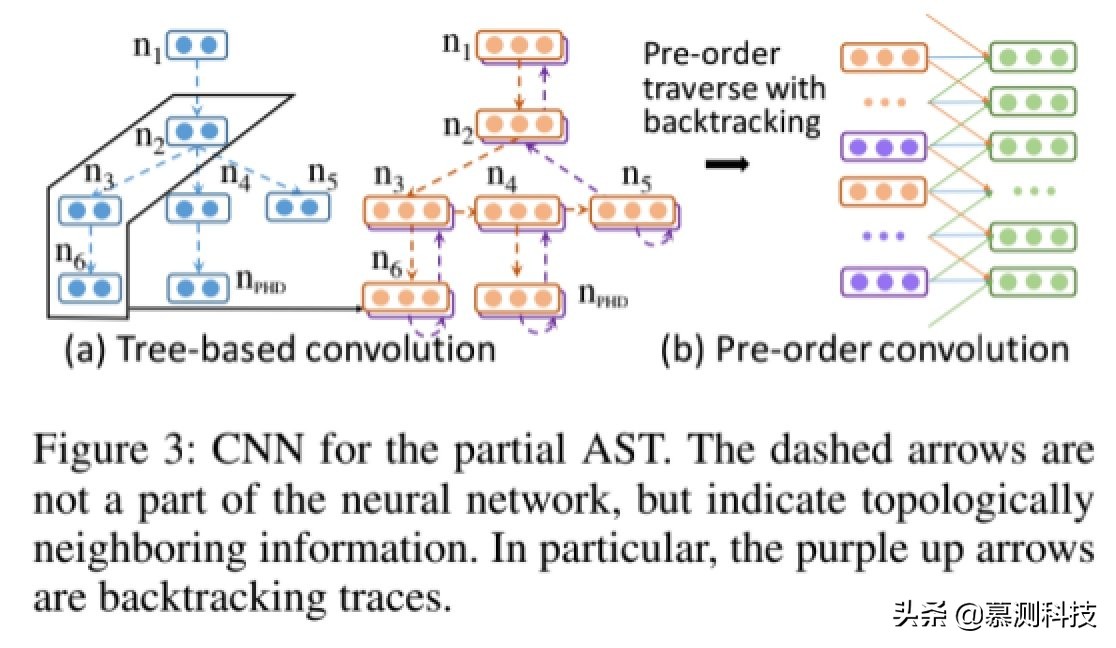
部分 AST 的 CNN
我们设计了一个深层的 CNN 模块来捕获 AST 的结构,文化信息。它包含基于树的卷积层,预遍历遍历卷积层以及树状路径 CNN 子模块,通知网络何处下一个语法规则被应用。
基于树的 CNN。我们首先将基于树的 CNN 应用于部分 AST。主要是设计一个固定深度的局部特征检测器,在树上滑动以提取结构特征。基于树的 CNN 的输入是具有以下内容的部分 AST:生成后,每个节点都由嵌入表示。我们也把一个占位符的节点至指示在哪里应用下一个语法规则。
假设节点 n 有一个父节点 p 和一个祖先节点 g。然后基于树的 CNN 提取特征可以被计算为
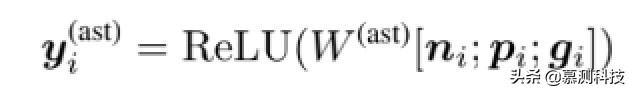
其中 W(ast)是基于树的卷积 ker-内尔。我们为前两个节点填充特殊 token 没有父母和/或祖父母的图层。
基于树的卷积,因为我们有一个更深的窗口,但没有考虑同级信息。这是因为我们的语法-基于世代的人通过申请一次获得所有兄弟姐妹-遵循一定的规则,因此,兄弟姐妹的重要性降低-比祖先更坦诚。不幸的是,深度会成倍增长,而深度会变小易处理,而我们的基于树的 CNN 变体会线性增长早。在卷积计算方面,我们采用类似感知器的互动方式。基于深度树的卷积和快捷方式连接,如 ResNet 可以作为未来的工作来探索。
前序遍历 CNN。获得一组通过基于树的 CNN 提取的向量,我们应用了预输入 y(ast)进行遍历卷积。也就是说,AST 节点是按照预先遍历顺序。
可以证明,简单的预遍历不是可以反转为树结构,即不同的树结构可能产生相同的序列。为了解决这个问题,我们在预购遍历期间跟踪回溯跟踪。T 是节点中的节点数 AST 和带回溯的预遍历可产生 2S 输入单位。
请注意,基于树的 CNN 和顺序遍历 CNN 捕获不同的信息。预购遍历产生的顺序可解决顺序邻居生成期间 AST 节点的引擎盖,而基于树卷积可为以下节点提供信息融合在结构上相邻。在图 3 中,例如,节点 n4 是 n2 的子节点。但是,生成后有些程序的其他部分(即 n3 和 n6),节点 n2 和 n4 不再彼此靠近。基于树的卷积直接为节点及其节点构建特征提取器祖先实现他们的互动。因此,我们相信这两类 CNN 互为补充。
树路径 CNN。我们应该只考虑以上 CNN,该模型很难说出位置应用下一个语法规则的位置。例如,基于树的 CNN 和预先遍历的 CNN 如果我们将图 3 中的 n4 或 n5 展开,将产生非常相似的特征,尽管有占位符,但我们还是为预购 CNN 引入了占位符。从技术上讲,如果我们遵循最左边的推导,那么应用下一条规则的位置将是明确的。但是这样线索太隐含,应该更明确地建模。因此,我们提取了从根到节点的路径,以 d 例如,如果我们要扩展 n4,则路径应该是 n1,n2,n4。我们称这种树路径卷积。
集合和注意机制
CNN 提取与尺寸或形状相同的一组特征输入。为了促进用于代码生成的 softmax 预测,我们需要将信息汇总到一个或几个固定的大小向量,与输入大小无关。
传统上,人使用最高汇集对于 CNN 以及基于树的 CNN。但是,这使得潜在的 CNN 模块分离且无法通信在信息聚合过程中。因此,我们纳入了 CNN 的关注机制池。本质上,注意机制计算候选集的加权和功能(由 CNN 提取),其中权重由由控制向量放置(例如,最大池另一个 CNN 模块的向量)。形式上,给定一个控制向量 c 和一组候选卷积特征 y1,···,yD 通过一个 CNN 模块(D 是特征向量的数量)。
将这样一个细心的池化层应用于我们的底层 CNN,我们将一些关键信息视为控制权-向量。(1)输入描述指定程序生成,然后用它来控制语法规则 CNN 和树路径 CNN。特别是,我们应用最大池层将输入的 CNN 功能汇总为固定大小控制向量,用于计算注意力树路径 CNN 的权重和预测语法规则。(2)我们注意到作用域名称(即函数名称或方法名称)提供照明信息关于它的后代。此类信息未被捕获 AST 节点类型,因此我们将范围名称嵌入为向量并使用它来控制预遍历 CNN 和输入的 CNN。应该注意的是,如果当前程序段位于两个或多个范围内(一个函数和一个方法),我们仅将最接近的范围视为曳向量。如果代码段不属于任何函数或类,然后将范围嵌入设置为零向量。除了针对基于树的层级,将另一个最大池化层应用于预订遍历 CNN 功能。我们的经验发现这是因为控制范围内的嵌入使相应的 AST 节点的注意力也达到最高峰,汇总信息不足。尽管控制向量,另一个最大池-信息层也可以保留更多信息。
我们还要指出的是,注意机制设计的选择及其含义在具有多个神经网络的深层神经网络中拖曳连接模块。例如,我们最好将 CNN 用于遵循以下控制原则把所有其他模块的输入在编码器-解码器框架。但是,我们的初步实验表明,这样的设计产生了更低的性能,因此我们采用了当前的体系结构。
训练和推论
我们将所有最大池化层和激活池化层连接在一起。它们被输入到两层感知器,最后一个层具有 softmax 激活函数,可预测下一个语法规则。
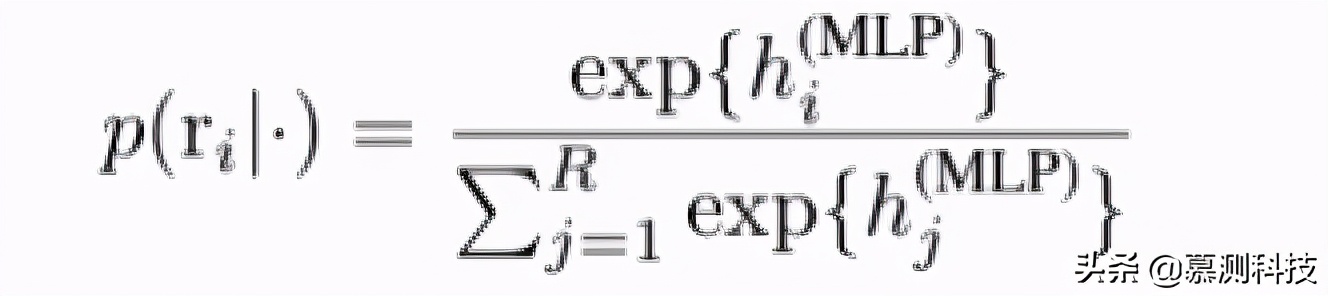
我们的模型是通过针对地面程序。由于我们的整个模型是不同的可靠,所有参数都是通过基于梯度的更新来学习的。
为了进行推断,我们寻求一系列的语法规则,最大化以输入为条件的概率。递归如果规则中的每个叶子节点都终止了对规则的密集预测(部分)树是终端符号。我们使用光束搜索近似于全局推断,并且波束大小为 5in 我们的实验。特定节点类型的无效规则是推理期间不考虑。例如,p2→c1c2,如果 p1 不等于 p2,则不能应用于节点 p1。
评估
在本部分中,我们介绍了 CNN 的实验结果基于代码的生成。我们在两个方面评估了我们的方法任务:(1)用 Python 代码生成《炉石传说》游戏,以及(2)用于生成可执行逻辑表单语义解析。
实验一《炉石传说》代码生成
数据集。我们的第一个实验基于建立基准数据集《炉石传说》。数据集包含 665 个不同的《炉石传说》游戏;每个数据点的输入都是半字段的结构化描述,例如卡名,费用,攻击,描述和其他属性;输出是可实现以下功能的 Python 代码段。
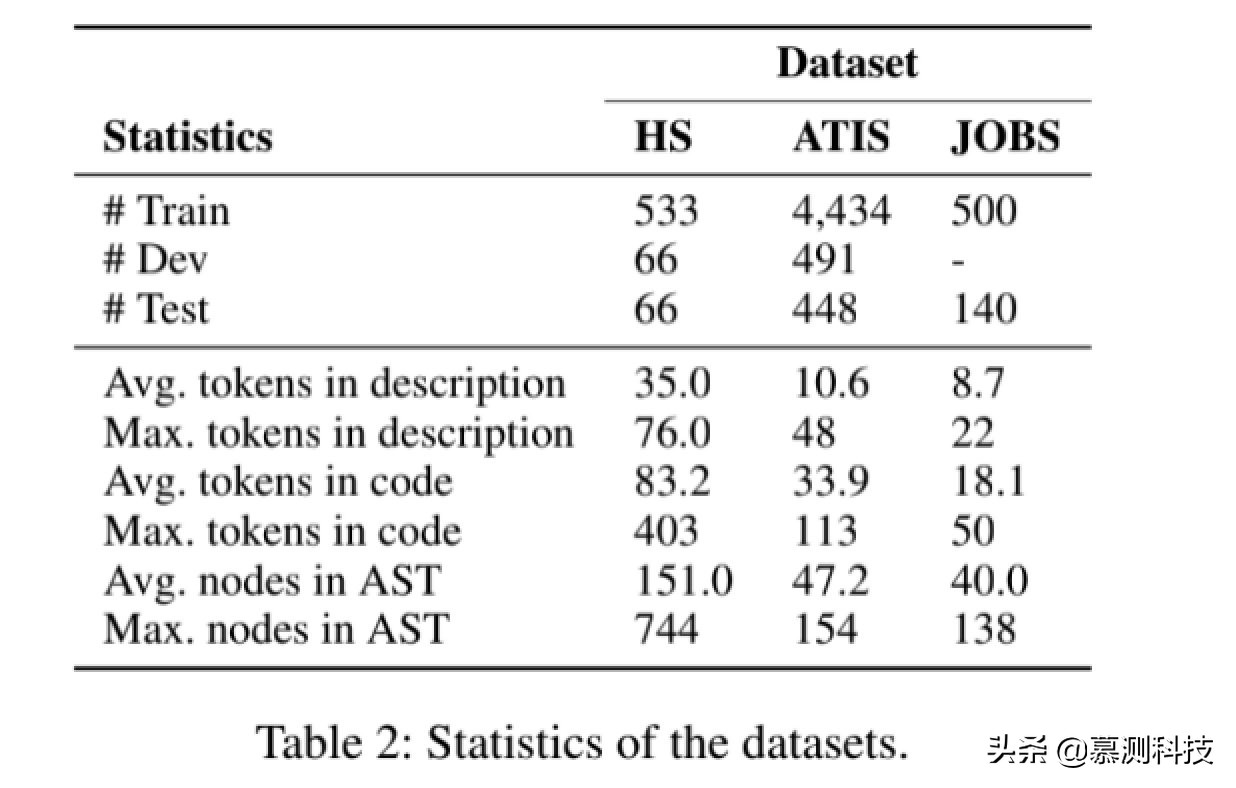
指标。表 2 中的《炉石传说》列列出了相关的数据集的统计信息。指标。我们通过准确性评估了我们的方法,BLEU 得分。理想情况下,精度应计入分数功能上正确的程序的位置,不幸的是不是图灵可计算的。我们还发现,几个生成的程序使用不同的变量名称,但实现了正确的功能,并且有时函数调用中的参数名称是或未指定。虽然与参考程序不同,但经过人工检查,它们显然是正确的程序,我们用 Acc 表示人为调整的精度。在这里,我们没有执行非 ob 检查算法的 Vious 替代实现,因此 Acc 仍然是功能精度的下界。
生成的代码的质量由 BLEU 评分作为辅助度量进一步评估,该度量计算生成的代码与地面真相代码的接近程度。
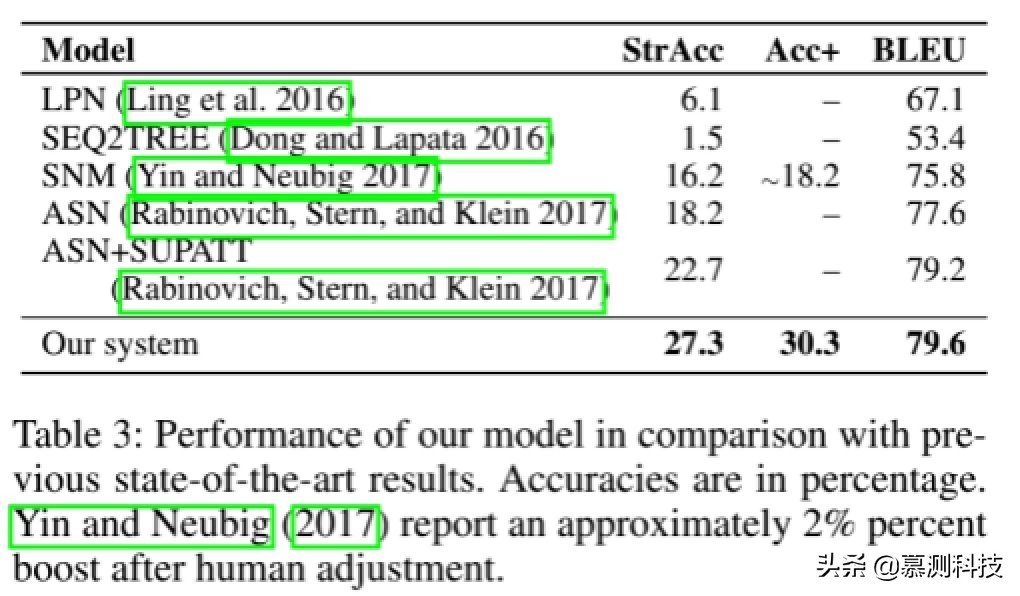
总体结果。表 3 列出了我们的 CNN-基于代码的生成,与之前的状态相比最先进的模型:(1)潜在预测网络,一种增强的序列到序列模型,具有多个 token 级别的预测器;(2)SEQ2TREE,基于 AST 的序列到序列模型;(3)句法神经模型,基于 AST 结构的 LSTM 解码器;和(4)Abstract 语法网络,另一个基于 AST 的序列到序列模型,它建立了两个 LSTM 水平预测规则和垂直方向。如图所示,我们的模型优于之前的所有结果准确性和 BLEU 分数。特别是,我们的准确性大大高于以前的状态弦乐方面的最新成果大约降低了 5 个百分点。生成的代码示例。
准确性。对于人工调整的精度(Acc+),报告显示,在我们的场景中观察到类似的现象,并且我们的 Acc+得分达到了 30.3%,表明我们的方法具有有效性。我们发现一个有趣的事实,即先前的几种方法可以达到与我们的方法类似的 BLEU 分数,但是精度要低得多。例如,ASN 模型 BLEU 分数为 79.2,与我们的 79.6 分相当模型。但是,ASN 只能达到 22.7%的字符串精度,而我们的是 27.3%。这是因为 BLEU 指标仅测量程序的相似度。预先以前的方法(例如 ASN)似乎可以生成合理的代码,实际上在细节上是不正确的。因此,我们仅考虑 BLEU 得分(在之前的作品)作为次要指标。主要指标即准确性,表明我们的方法产生了更多的交流策划程序比以前的模型。
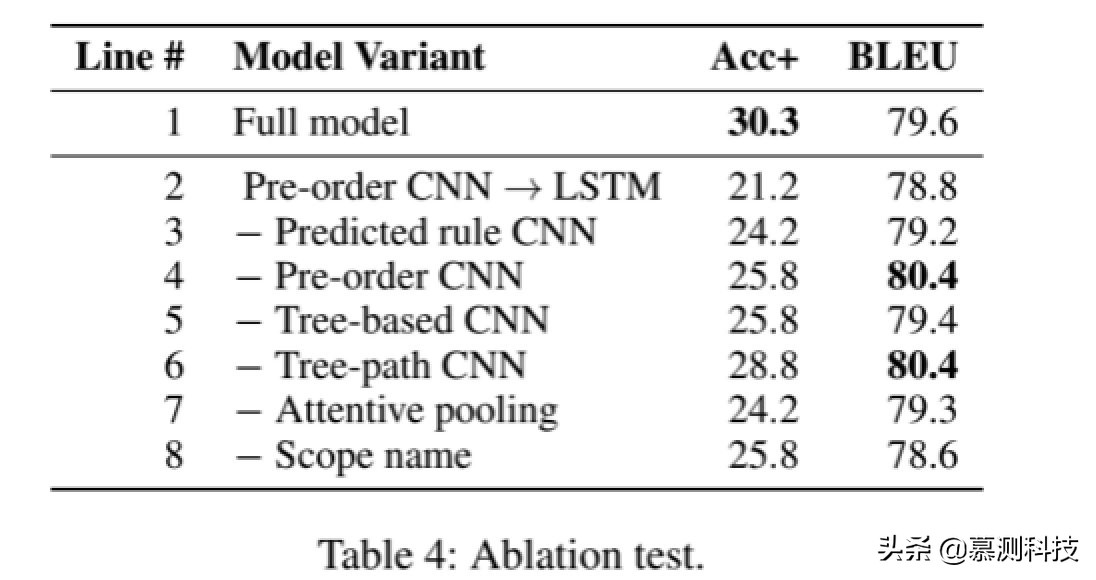
消融测试。我们进行了广泛的消融测试分析每个组成部分的贡献。虽然我们网络的发展从简单的基准开始然后我们逐步添加了有用的组件,相对测试是以相反的方式进行的:它从完整的模型,我们要么删除了一个组件或用一些合理的替代品。我们在表 4 中报告了消融测试的结果。
我们首先通过替代 CNN 来分析 CNN 的效果基于 LSTM 的 RNN 的组件。自从主要信息在于部分 AST 中显示的年龄,而不是预测语法规则中,我们仅将预遍历 CNN 替换为 LSTM 在此对照实验中。RNN 应用于如此长的序列可能很难训练,实现显著恶化性能。
我们还分析了模型的其他组成部分,包括为 CNN 预测规则,基于树的卷积常规层,树路径卷积,池化层机制,以及合并的范围控制器。我们看到上述每个组件都包含以自己的方式为整个模型做出贡献,准确度提高了 3–6%。这些结果表明我们有设计了神经体系结构的合理组成部分,适合于代码生成任务。
实验二
数据集和设置。语义解析旨在生成逻辑形式给出自然语言描述。它可以被认为是针对特定领域的代码生成,因为逻辑形式是可执行文件,所以一种正式语言。但是,语义解析的样式与 python 代码生成明显不同。自从我们模型主要是在《炉石传说》数据集上开发的,该实验用作对泛化性的附加评估我们的模型。
我们在两个语义解析数据集上评估了我们的模型,其中输入的是自然语言句子。ATIS 的输出是 λ 微积分形式,而对于 JOBS,它采用 Prolog 样式。从表 2 的统计数据可以看出语义解析的逻辑形式包含节点少于《炉石传说》Python 代码。
我们采用了与《炉石传说》基本相同的网络层进行语义解析。网络层数是 7。我们没有建立一个单独的不同的节点类型的网络,因为我们的网络容易对于如此小的数据集过拟合。此外,我们介绍了指针网络进行复制变量名称。
结果。我们通过准确性来评估我们的方法。它计算精确匹配的分数,除了我们调整连接和分离子句的顺序以避免虚假错误,就像以前的所有工作一样。我们没有测量 BLEU,因为它没有用于现有的研究。
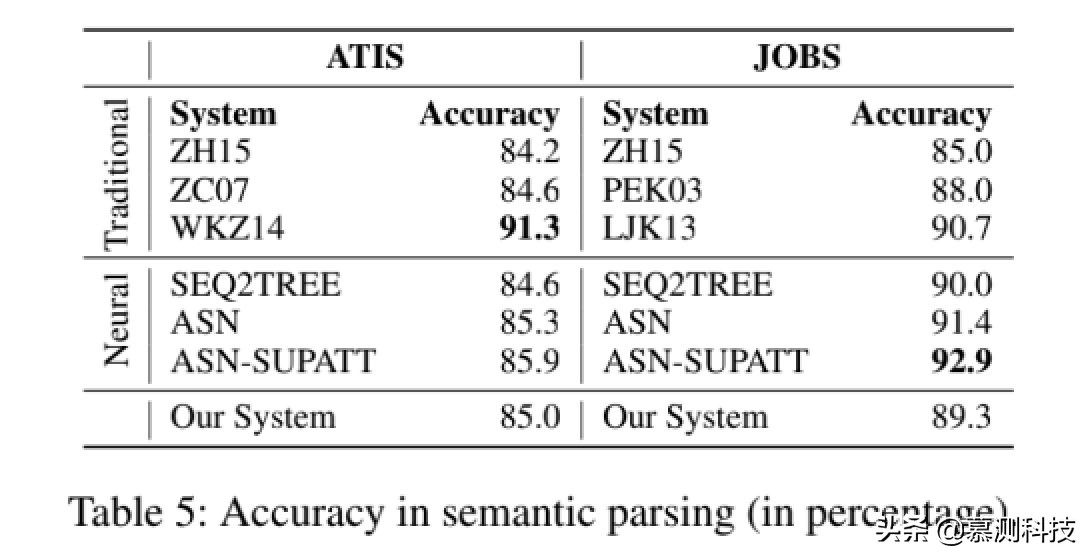
表 5 显示了我们模型的性能。我们还看到我们基于语法的结构 CNN 编码器可达到与最新的神经网络相似的结果拉尔模型。还应该指出,在语义上解析,我们无法像《炉石传说》代码生成。这可能是因为语义解析的逻辑形式通常很短,包含像《炉石传说》中一样只处理 1/4–1/3 个 token,因此 RNN 和 CNN 适合生成逻辑表格。这个实验提供了泛化的其他证据,自从我们创建 CNN 代码以来,我们的能力和灵活性模型基本上是为长程序设计的(例如《炉石传说》)但也可以与语义解析一起很好地工作。
结论
在本文中,我们提出了一种基于语法的结构 CNN 用于代码生成。我们的模型利用了抽象程序的语法树(AST),并通过规定语法规则。我们解决了基于 RNN 的传统方法可能不适合于克生成,可能是由于大量的程序中的 kens/nodes。因此,我们设计了 CNN 编码器-基于 AST 结构的解码器模型。我们在《炉石传说》数据集上的主要实验显示我们取得了比以前的基于 RNN 的方法。的其他实验两个语义解析任务证明了鲁棒性我们的方法。我们还进行了深度消融测试,以验证模型中每个组件的有效性。
致谢
本文由南京大学软件学院 iSE 实验室 2020 级硕士研究生张晶翻译转述。