前端优化是一个大的课题,需要花好多时间才能理解,之前对前端优化陆陆续续有一些了解。所以这次从渲染优化,打包优化,代码优化做了一个系统的总结,并且引申出了几个需要关注的问题,文章可能有点长,大家一定要看到最后。最后写作不易,希望觉得还可以的话,帮忙点赞一波,提前感谢了。当然如果有写不好的地方,也请指出来,我会积极改进,共同成长。
渲染优化
渲染优化是前端优化中一个很重要的部分,一个好的首屏时间能给用户带来很好的体验,这里要说的一点是关于首屏时间的定义,不同的团队对首屏时间定义不一样,有的团队认为首屏时间就是白屏时间,是从页面加载到第一个画面出现的时间。但是当我们说到用户体验的时候,仅仅是这样还达不到效果,所以有的前端团队认为,首屏时间应该是从页面加载到用户可以进行正常的页面操作时间,那么我们就依照后者来进行说明
js css 加载顺序
说渲染优化之前,我们还需要说一个小插曲,就是比较经典的一道问题"浏览器地址栏输入url发生了什么",理解了这个我们才可以更清楚js,css加载顺序对渲染的影响
问题 1:地址栏输入url 发生了什么
这个问题经常被人提起,有人回答比较简洁点,有人可能回答的比较详细,下面就说一下主要流程
- 首先会进行 url 解析,根据 dns 系统进行 ip 查找
- 根据 ip 就可以找到服务器,然后浏览器和服务器会进行 TCP 三次握手建立连接,如果此时是 https 的话,还会建立 TLS 连接以及协商加密算法,这里就会出现另一个需要注意的问题"https 和 http 的区别"(下文会讲到)
- 连接建立之后浏览器开始发送请求获取文件,此时这里还会出现一种情况就是缓存,建立连接后是走缓存还是直接重新获取,需要看后台设置,所以这里会有一个关注的问题"浏览器缓存机制",缓存我们等会在讲,现在我们就当没有缓存,直接去获取文件
- 首先获取 html 文件,构建 DOM 树,这个过程是边下载边解析,并不是等 html 文件全部下载完了,再去解析 html,这样比较浪费时间,而是下载一点解析一点
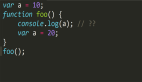
- 好了解析到 html 头部时候,又会出现一种问题,css,js 放到哪里了?不同的位置会造成渲染的不同,此时就会出现另一个需要关注的问题"css,js 位置应该放哪里?为什么",我们先按照正确的位置来说明(css 放头部,js 放尾部)
- 解析到了 html 头部发现有 css 文件,此时下载 css 文件,css 文件也是一边下载一边解析的,构建的是 CSSOM 树,当 DOM 树和 CSSOM 树全部构建完之后,浏览器会把 DOM 树和 CSSOM 树构建成渲染树。
- 样式计算, 上面最后一句"DOM 树和 CSSOM 树会一起构建成渲染树"说的有点笼统,其实还有更细一点的操作,但是一般回答到上面应该就可以了,我们现在接上面说一下构造渲染树的时候还做了哪些事情。第一个就是样式计算,DOM树 和 CSSOM树有了之后,浏览器开始样式计算,主要是为 DOM 树上的节点找到对应的样式
- 构建布局树,样式计算完之后就开始构建布局树。主要是为 DOM 树上的节点找到页面上对应位置以及一些"display:none"元素的隐藏。
- 构建分层树,布局树完成后浏览器还需要建立分层树,主要是为了满足滚动条,z-index,position 这些复杂的分层操作
- 将分层树图块化,利用光栅找到视图窗口下的对应的位图。主要是因为一个页面可能有几屏那么长,一下渲染出来比较浪费,所以浏览器会找到视图窗口对应的图块,将这部分的图块进行渲染
- 最终渲染进程将整个页面渲染出来,在渲染的过程中会还出现重排和重绘,这也是比较爱问的问题"重排重绘为什么会影响渲染,如何避免?"
- 以上过程大概讲解了一下从 url 到页面渲染的整个过程,其实涉及到了几个需要关注的问题,下面来具体讲讲
问题 2:js css 顺序对前端优化影响
上面我们说到了整个渲染流程,但是没有说到 css 和 js 对渲染的影响。渲染树的构成必须要 DOM 树和 CSSOM 树的,所以尽快的构建 CSSOM 树是一个重要的优化手段,如果 css 文件放在尾部,那么整个过程就是一个串行的过程先解析了 dom,再去解析 css。所以 css 我们一般都是放在头部,这样 DOM 树和 CSSOM 树的构建是同步进行的。
再来看 js,因为 js 的运行会阻止 DOM 树的渲染的,所以一旦我们的 js 放在了头部,而且也没有异步加载这些操作的话,js 一旦一直在运行,DOM 树就一直构建不出来,那么页面就会一直出现白屏界面,所以一般我们会把 js 文件放在尾部。当然放到尾部也不是就没有问题了,只是问题相对较小,放到尾部的 js 文件如果过大,运行时间长,代码加载时,就会有大量耗时的操作造成页面不可点击,这就是另一个问题,但这肯定比白屏要好,白屏是什么页面都没有,这种是页面有了只是操作不流畅。
js 脚本放在尾部还有一个原因,有时候 js 代码会有操作 dom 节点的情况,如果放在头部执行,DOM树还没有构建,拿不到 DOM 节点但是你又去使用就会出现报错情况,错误没处理好的话页面会直接崩掉
问题 3:重排重绘为什么会影响渲染,如何避免?
重排和重绘为什么会影响渲染,哪个影响更大,如何避免是经常被问到的一道题目,我们先来说一下重绘
- 重绘
重绘指的是不影响界面布局的操作,比如更改颜色,那么根据上面的渲染讲解我们知道,重绘之后我们只需要在重复进行一下样式计算,就可以直接渲染了,对浏览器渲染的影响相对较小
- 重排
重排指的是影响界面布局的操作,比如改变宽高,隐藏节点等。对于重排就不是一个重新计算样式那么简单了,因为改变了布局,根据上面的渲染流程来看涉及到的阶段有样式计算,布局树 重新生成,分层树重新生成,所以重排对浏览器的渲染影响是比较高的
- 避免方法
- js 尽量减少对样式的操作,能用 css 完成的就用 css
- 果必须要用 js 操作样式,能合并尽量合并不要分多次操作
- resize 事件 最好加上防抖,能尽量少触发就少触发
- 加载对 dom 操作尽量少,能用 createDocumentFragment 的地方尽量用
- 加图片的时候,提前写好宽高
问题 4:浏览器缓存机制
浏览器缓存是比较常见的问题,我会从浏览器缓存的方式,缓存的实现, 缓存在哪里这几个点来说明
缓存方式
我们经常说的浏览器缓存有两种,一种是强制缓存,一种是协商缓存,因为下面有具体实现讲解,所以这里就说一下概念
- 协商缓存
协商缓存意思是文件已经被缓存了,但是否从缓存中读取是需要和服务器进行协商,具体如何协商要看请求头/响应头的字段设置,下面会说到。需要注意的是协商缓存还是发了请求的
- 强制缓存
强制缓存就是文件直接从缓存中获取,不需要发送请求
缓存实现
- 强制缓存
强制缓存在 http1.0 的时候用的是 Expires,是响应头里面的一个字段表示的是文件过期时间。是一个绝对时间,正因为是绝对时间所以在某些情况下,服务器的时区和浏览器时区不一致的时候就会导致缓存失效。为了解决这个问题,HTPP1.1 引入了一个新的响应头 cache-control 它的可选值如下
cache-control
- max-age: 缓存过期时间,是一个相对时间
- public: 表示客户端和代理服务器都会缓存
- private: 表示只在客户端缓存
- no-cache: 协商缓存标识符,表示文件会被缓存但是需要和服务器协商
- no-store: 表示文件不会被缓存
HTTP1.1 利用的就是 max-age:600 来强制缓存,因为是相对时间,所以不会出现 Expires 问题
- 协商缓存
协商缓存是利用 Last-Modified/if-Modified-Since,Etag/if-None-Match 这两对请求、响应头。
Last-Modified/if-Modified-Since
Etag/If-None-Match
由于 Last-Modified 的时间粒度是秒,有的文件在 1s 内可能被改动多次。这种方式在这种特殊情况下还是会失效,所以HTTP1.1又引入了 Etag 字段。这个字段是根据文件内容生成一个标记符比如"W/"5f9583bd-10a8"",然后再和 If-None-Match 进行对比就能更准确的知道文件有没有被改动过
- 浏览器第一次发送请求获取文件缓存下来,服务器响应头返回一个 if-Modified-Since,记录被改动的时间
- 浏览器第二次发送请求的时候会带上一个 Last-Modified 请求头,时间就是 if-Modified-Since 返回的值。然后服务器拿到这个字段和自己内部设置的时间进行对比,时间相同表示没有修改,就直接返回 304 从缓存里面获取文件
缓存在哪里
知道了缓存方式和实现,再来说一下缓存存在哪个地方,我们打开掘金可以看到如下的信息 。缓存的来源有两个地方 from dist cache,from memeory cache

form memory cache
这个是缓存在内存里面,优点是快速,但是具有时效性,当关闭 tab 时候缓存就会失效。
from dist cache
这个是缓存在磁盘里面,虽然慢但是还是比请求快,优点是缓存可以一直被保留,即使关闭 tab 页,也会一直存在
何时缓存在memory,合适缓存在dist?
这个问题网上很少找的到标准答案,大家一致的说法是js,图片文件浏览器会自动保存在memory中,css文件因为不常修改保存在dist里面,我们可以打开掘金网站,很大一部分文件都是按照这个规则来的,但是也有少数js文件也是缓存在dist里面。所以他的存放机制到底是什么样了?我带着这个疑问查了好多文章,虽然最后没有确切找到答案,但是一个知乎的回答可以给我们提供思路,下面引用一个知乎回答者一段话
- 第一个现象(以图片为例):访问-> 200 -> 退出浏览器再进来-> 200(from disk cache) -> 刷新 -> 200(from memory cache)。总结: 会不会是chrome很聪明的判断既然已经从disk拿来了, 第二次就内存拿吧 快。(笑哭)
- 第二个现象(以图片为例):只要图片是base64 我看都是from memroy cache。总结: 解析渲染图片这么费劲的事情,还是做一次然后放到内存吧。用的时候直接拿
- 第三个现象(以js css为例):个人在做静态测试的发现,大型的js css文件都是直接disk cache。结: chrome会不会说 我去 你这么大太占地方了。你就去硬盘里呆着吧。慢就慢点吧。
- 第四个现象:隐私模式下,几乎都是 from memroy cache。总结: 隐私模式 是吧。我不能暴露你东西,还是放到内存吧。你关,我死。
上面几点是虽然很幽默,但是却可以从中找到一部分答案,但是我觉得另一个知乎回答我更赞同
浏览器运行的时候也是由几个进程协作的,所以操作系统为了节省内存,会把一部分内存里的资源交换回磁盘的交换区,当然交换是有策略的,比如最常用的就是LRU。
什么时候存dist,什么时候存memoey都是在浏览器控制下的,memory不够了可能就会考虑去存dist了,所以经过上面所说我自己总结结果如下
- 大一点的文件会缓存在dist里面,因为内存也是有限的,磁盘的空间更大
- 小一点文件js,图片存的是memory
- css文件一般存在dist
- 特殊情况memory大小是有限制的,浏览器也会根据自己的内置算法,把一部分js文件存到dist里面
问题 5:https 和 http 的区别
说到https和http的区别,可以说一下https服务器和客户端连接的差异,以及https特定的加密算法协商,甚至可能还要说到对称加密,非对称加密和证书等,篇幅很长,请看我之前单独写的一篇https详解,里面讲的非常详细。
请求优化
讲请求优化的之前先来总结下上面说到的js, css文件顺序优化,为了让渲染更快,我们需要把js放到尾部,css放到头部,然后还要注意在书写js的时候尽量减少重排,重绘。书写html,css的时候尽量简洁,不要冗余,目的是为了更快的构建DOM树和CSSOM树。好了下面我们在来说说请求优化,请求优化可以从请求数量和请求时间两方面入手
减少请求数量
- 将小图片打包成base64
- 利用雪碧图融合多个小图片
- 利用缓存上面已经说到过
减少请求时间
- 将js,css,html等文件能压缩的尽量压缩,减少文件大小,加快下载速度
- 利用webpack打包根据路由进行懒加载,不要初始就加载全部,那样文件会很大
- 能升级到高版本的http就升级到高版本(这个回答是套话),为什么高版本能提高速度具体看上面我说的那篇https文章
- 建立内部CDN能更快速的获取文件
webpack优化
介绍了渲染优化,现在来看看webpack优化,自己平常写demo给团队做培训的时候都是自己手写webpack配置,虽然也就几十行,但每次都能让我巩固webpack的基本配置,下面直接说一下webpack优化手段有哪些
基础配置优化
- extensions 这个配置是属于resolve里面的,经常用来对文件后缀进行扩展,写法如下
- resolve: {
- extensions: ['.ts', '.tsx', '.js']
- }
这个配置表示webpack会根据extensions去寻找文件后缀名,所以如果我们的项目主要用ts写的话,那我们就可以.tsx和.ts写前面,目的是为了让webpack能够快速解析
- alias 这个配置也是属于resolve里面的,是用来映射路劲,能减少打包时间的主要原因是能够让webpack快速的解析文件路径,找到对应的文件,配置如下
- resolve: {
- alias: {
- Components: path.resolve(__dirname, './src/components')
- }
- }
- noParse
noParse表示不需要解析的文件,有的文件可能是来自第三方的文件,被 providePlugin引入作为windows上的变量来使用,这样的文件相对比较大,并且已经是被打包过的,所以把这种文件排除在外是很有必要的,配置如下
- module: {
- noParse: [/proj4\.js/]
- }
- exclude
某些loader会有这样一个属性,目的是指定loader作用的范围,exclude表示排除某些文件不需要babel-loader处理,loader的作用范围小了,打包速度自然就快了,用babel-loader举一个简单例子
- {
- test: /\.js$/,
- loader: "babel-loader",
- exclude: path.resolve(__dirname, 'node_modules')
- }
- devtool
这个配置是一个调试项,不同的配置展示效果不一样,打包大小和打包速度也不一样,比如开发环境下cheap-source-map肯定比source-map快,至于为什么,强烈推荐自己之前写的这一篇讲解devtool的文章:webpack devtools篇讲的非常详细。
- {
- devtool: 'cheap-source-map'
- }
.eslintignore
这个虽不是webpack配置但是对打包速度优化还是很有用的,在我的实践中eslint检查对打包的速度影响很大,但是很多情况我们不能没有这个eslint检查,eslint检查如果仅仅在vs里面开启的话,可能不怎么保险。
因为有可能你vs中的eslint插件突然关闭了或者某些原因vs不能检查了,只能靠webpack构建去帮你拦住错误代码的提交,即使这样还不能确保万无一失,因为你可能某一次提交代码很急没有启动服务,直接盲改提交上去了。这个时候只能通过最后一道屏障给你保护,就是在CI的时候。比如我们也会是在jenkins构建的时候帮你进行eslint检查,三道屏障确保了我们最终出的镜像是不会有问题的。
所以eslint是很重要的,不能删掉,在不能删掉的情况下怎么让检查的时间更少了,我们就可以通过忽略文件,让不必要的文件禁止eslint,只对需要的文件eslint可以很大程度提高打包速度
loader,plugins优化
上述说了几个基础配置优化,应该还有其他的基础配置,今后遇到了再继续添加,现在在来讲讲利用某些loader,plugins来提高打包速度的例子
- cache-loader
这个loader就是在第一次打包的时候会缓存打包的结果,在第二次打包的时候就会直接读取缓存的内容,从而提高打包效率。但是也需要合理利用,我们要记住一点你加的每一个loader,plugins都会带来额外的打包时间。这个额外时间比他带来的减少时间多,那么一味的增加这个loader就没意义,所以cache-loader最好用在耗时比较大的loader上,配置如下
- {
- rules: [
- {
- test: /\.vue$/,
- use: [
- 'cache-loader',
- 'vue-loader'
- ],
- include: path.resolve(__dirname, './src')
- }
- ]
- }
- webpack-parallel-uglify-plugin, uglifyjs-webpack-plugin, terser-webpack-plugin
在上面的渲染优化中我们已经知道,文件越小渲染的速度是越快的。所以我们在配置webpack时候经常会用到压缩,但是压缩也是需要消耗时间的,所以我们我们经常会用到上面三个插件之一来开启并行压缩,减少压缩时间,我们用webpack4推荐使用的terse-webpack-plugin做例子来说明
- optimization: {
- minimizer: [
- new TerserPlugin({
- parallel: true,
- cache: true
- })
- ],
- }
- happypack, parallel-webpack, thread-loader
这几个loader/plugin和上面一样也是开启并行的,只不过是开启并行构建。由于happypack的作者说自己的兴趣已经不再js上了,所以已经没有维护了,并推荐如果使用的是webpack4的话,就去使用thread-loader。基本配置如下
- {
- test: /\.js$/,
- use: [
- {
- loader: "thread-loader",
- options: threadLoaderOptions
- },
- "babel-loader",
- ],
- exclude: /node_modules/,
- }
- DllPlugin,webpack.DllReferencePlugin
上面说的几个并行插件理论上是可以增加构建速度,网上很多文章都是这么说的,但是我在实际的过程中使用,发现有时候不仅没提升反而还降低了打包速度,网速查阅给的理由是可能你的电脑核数本来就低,或者当时你CPU运行已经很高了,再去开启多进程导致构建速度降低。
上面说的几个并行插件可能在某些情况下达不到你想要的效果,然而在我们团队优化webpack性能经验来看,这次所说的两个插件是很明显并且每次都能提高打包速度的。原理就是先把第三方依赖先打包一次生成一个js文件,然后真正打包项目代码时候,会根据映射文件直接从打包出来的js文件获取所需要的对象,而不用再去打包第三方文件。只不过这种情况打包配置稍微麻烦点,需要写一个webpack.dll.js。大致如下
webpack.dll.js
- const path = require('path');
- const webpack = require('webpack');
- module.exports = {
- entry: {
- library: ["vue", "moment"]
- },
- output: {
- filename: '[name].dll.js',
- path: path.resolve(__dirname, 'json-dll'),
- library: '[name]'
- },
- plugins: [
- new webpack.DllPlugin({
- path: './json-dll/library.json',
- name: '[name].json'
- })
- ]
- }
webpack.dev.js
- new AddAssetHtmlWebpack({
- filepath: path.resolve(__dirname, './json-dll/library.dll.js')
- }),
- ew webpack.DllReferencePlugin({
- manifest: require("./json-dll/library.json")
- })
其他优化配置
这些插件就简单的介绍下,在我的个人项目中已经使用过,自我感觉还可以,具体使用可以查阅npm或者github
- webpack-bundle-analyzer
这个插件可以用可视化帮我们分析打包体积,从而来采用合适的优化方式去改进我们的webpack配置
- speed-measure-webpack-plugin
这个插件可以告诉我们打包时候每一个loader或者plugin花费了多少时间,从而对耗时比较长的plugin和loader做优化
- friendly-errors-webpack-plugin
这个插件可以帮我们优化打包日志,我们打包时候经常看到很长一个日志信息,有的时候是不需要的,也不会去看所以可以用这个插件来简化
代码优化
这是最后一部分代码优化了,这里的代码性能优化我只说我在工作中感受到的,至于其他的比较小的优化点比如createDocumentFragment使用可以查查其他文章
能不操作dom不要操作dom,哪怕有时候需要改设计
很多情况下我们都能用css还原设计稿,但是有些时候单单从css没法还原,尤其组件还不是你写的时候,比如我们团队用的就是antd,有时候的产品设计单从css上没法实现,只能动用js,删除,增加节点在配合样式才能完成。
由于我们又是一个做大数据的公司,这个时候就会出现性能问题,最开始写代码时候,产品说什么就是什么,说什么我都会想办法搞出来,不管用什么方法。后来到客户现场大数据请况下,性能缺点立马暴露的出来。
所以代码优化的原则之一我认为是能不写的代码就不写,当然这是要从性能角度出发,通过性能分析给产品说出理由,并且最好还能提供更好的解决方案,这个才是我们需要考虑的。
如果用的是react 一定用写shouldComponentUpdate这个生命周期函数,不然打印的时候你会发现,你自己都迷糊为什么执行了这么多遍
将复杂的比对,变成简单比对
这句话是什么意思了?我们就拿shouldComponentUpdate举例子,用这个函数没问题,但是可以做的更好,我们在工作中经常这么写
- shouldComponentUpdate(nextPrpops) {
- return JSON.stringify(nextPrpops.data) !== JSON.stringify(this.props.data)
- }
如果这是一个分页表格,data是每一页数据,数据改变了重新渲染,在小数据场景下这本身是没有问题。但是如果在大数据的场景下可能会有问题,可能有人有疑问,既然做了分页怎么还会有大数据了,因为我们的产品是做大数据分析日志的,一页十条日志,有的日志可能非常的长,也就是说就算是10条数据比对起来也是很耗时,所以当时想法能不能找到其他的替代变量来表示数据变了?比如下面这样
- shouldComponentUpdate(nextPrpops) {
- return nextPrpops.data[0].id !== this.props.data[0].id
- }
第一条的id不一样就表示数据变化了行不行,显然在某种情况下是存在的,也有人会说可能会出现id一样,那如果换成下面这种了?
- shouldComponentUpdate(nextPrpops) {
- return nextPrpops.current !== this.props.current
- }
将data的比对转换成了current的比对,因为页数变了,数据基本都是变了,对于我们自己日志的展示来说基本不存在两页数据是一模一样的,如果有那可能是后台问题。然后在好好思考这个问题,即使存在了两页数据一摸一样,顶多就是这个表格不重新渲染,但是两页数据一摸一样不重新渲染是不是也没有问题,因为数据是一样的。或者如果你还是不放心,那下面这种会不会好点
- this.setState({
- data,
- requestId: guid()
- })
- shouldComponentUpdate(nextPrpops) {
- return nextPrpops.requestId !== this.props.requestId
- }
给一个requestId跟宗data,后面就只比对requestId。上面的写法可能都有问题,但是主要是想说的是我们在写代码时候可以想想是不是可以"将复杂的比对,变成简单比对"
学习数据结构和算法,一定会在你的工作中派上用场
我们经常会听到学习数据结构和算法没有什么大的用处,因为工作基本用不上。这句话我之前觉得没错,现在看来错的很严重。我们所学的每一样技能,都会在将来的人生中派上用场。之前写完代码就丢了不去优化所以我觉得算法没意义,又难又容易忘记。但现在要求自己做完需求,开启mock,打开perfermance进行大数据量的测试,看着那些标红的火焰图和肉眼可见的卡顿,就明白了算法和数据结构的重要性,因为此时你只能从它身上获取优化,平时你很排斥它,到优化的时候你是那么想拥有它。我拿自己之前写的代码举例,由于公司代码是保密的我就把变量换一下,伪代码如下
- data.filter(({id}) => {
- return selectedIds.includes(id);
- })
就是这样几行代码,逻辑就是筛选出data里面已经被勾选的数据。基本上很多人都可能这么写,因为我看我们团队里面都是这么写的。产品当时已经限制data最多200数据,所以写完完全没压力,性能没影响。但是秉着对性能优化的原则(主要是被现场环境搞怕了~~~),我开启了mock服务,将数据调到了2万条再去测试,代码弊端就暴露出来了,界面进入卡顿,重新选择的时候也会卡顿。然后就开始了优化,当时具体的思路如下
按照现在的代码来看,这是一个两层循环的暴力搜索时间复杂度为O(n^2)。所以想着能不能降一下复杂度至少是O(nlogn),看了一下代码只能从selectedIds.includes(id)这句入手,于是想着可不可以用二分,但是立马被否定因为二分是需要有序的,我这数组都是字符串怎么二分。
安静了一下之后,回想起看过的算法课程和书籍以及做的算法题,改变暴力搜索的方法基本都是
1:上指针
2:数组升维
3:利用hash表
前两者被我否定了因为我觉得还没那么复杂,于是利用hash表思想解决这个问题,因为js里面有一个天然的hash表结构就是对象。我们知道hash表的查询是O(1)的,所以我将代码改写如下
- const ids = {};
- selectedIds.forEach(id => ids[id] = 1);
- data.filter(({id}) => {
- return !!ids[id];
- })
将从selectedIds查询变成从ids查询,这样时间复杂度就从O(n^2)变成了O(n)了,这段代码增加了
- const ids = {};
- selectedIds.forEach(id => ids[id] = 1);
其实增加了一个selectedIds遍历也是一个O(n)的复杂度,总来说复杂度是O(2n),但是从时间复杂度长期期望来看还是一个O(n)的时间复杂度,只不过额外增加了一个对象,所以这也是一个典型的空间换时间的例子,但是也不要担心,ids用完之后垃圾回收机制会把他回收的。
最后
其实这篇文章写出来还是对自己帮助很大,让自己系统的梳理了一下自己理解的前端优化,希望对你们也有帮助。