














一 引用基本概念

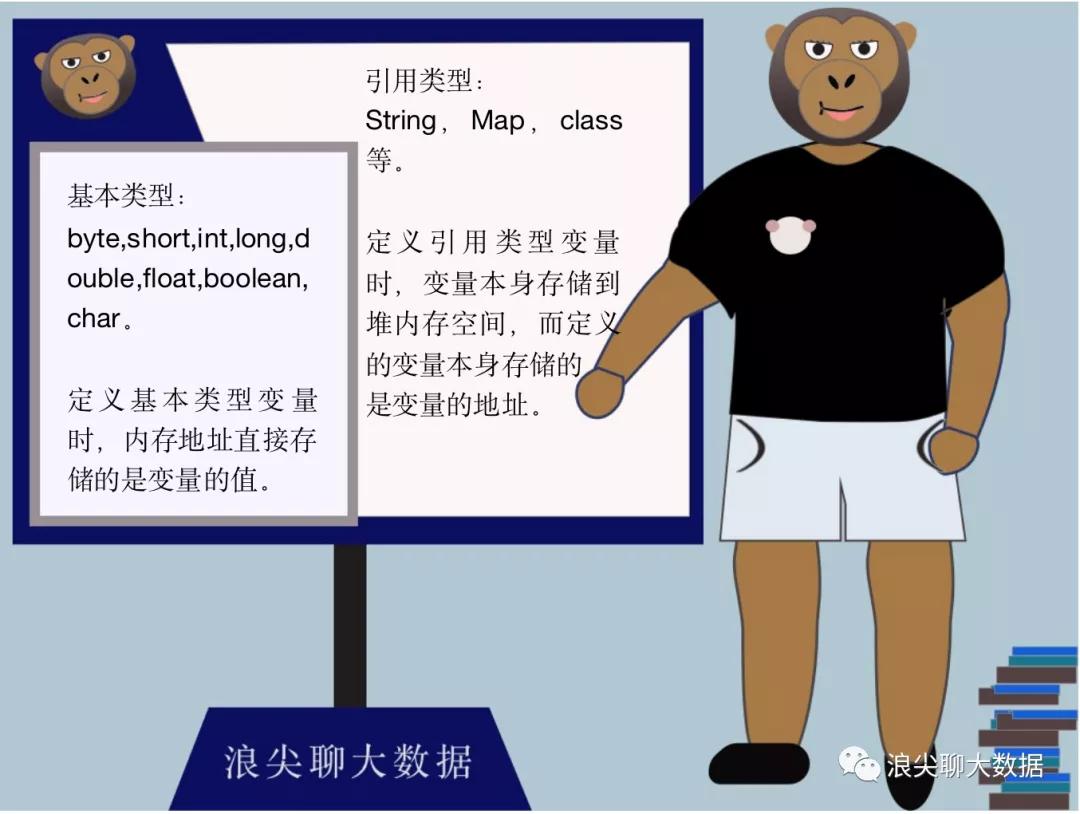
如下面,定义两个变量num,str,存储模型大致如下图:
int num = 6;
String str = “浪尖聊大数据”;
- 1.
- 2.
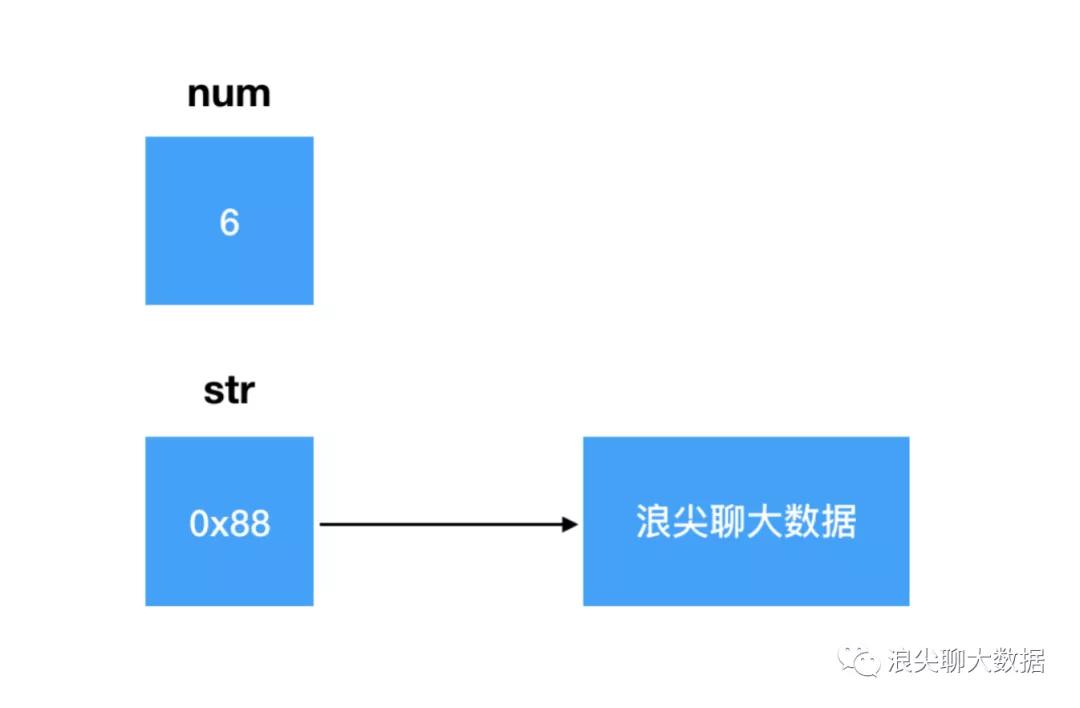

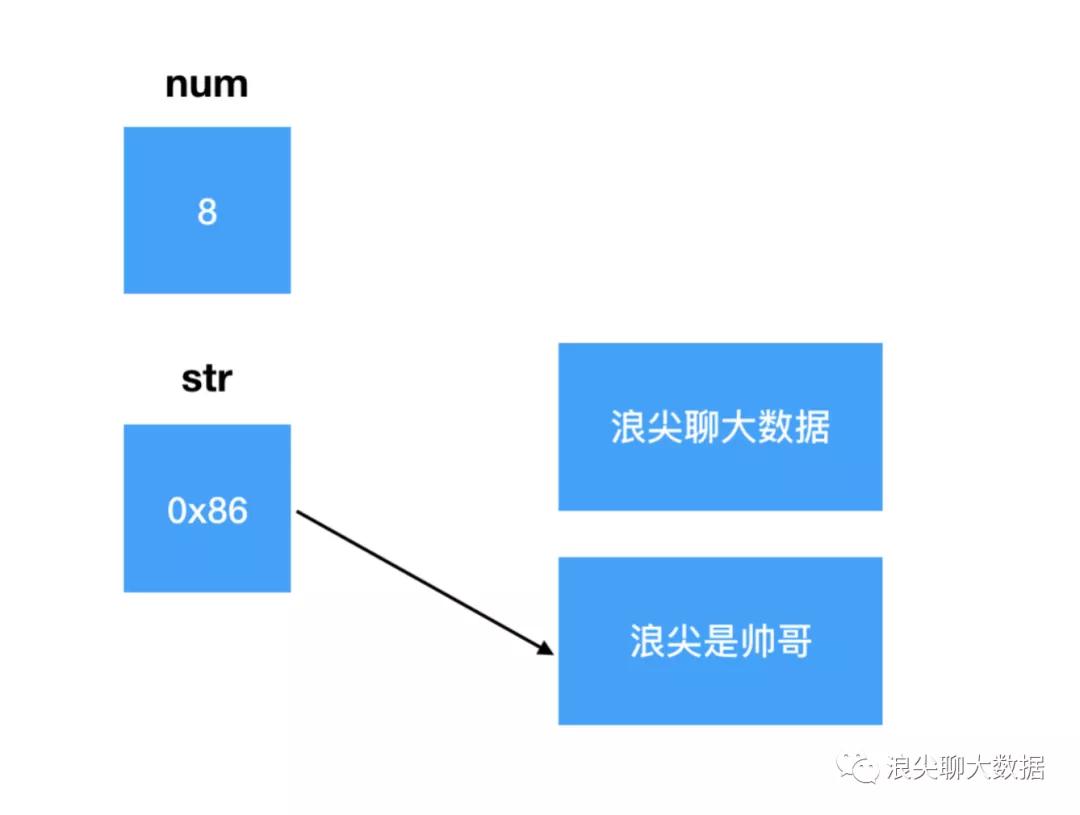
变量num值直接从6修改为了8;变量str只是修改了其保存的地址,从0x88修改为0x86,对象 “浪尖聊大数据 ”本身还在内存中,并没有被修改。只是内存中新增了对象 “浪尖是帅哥”。
二 值传递&引用传递

举例说明引用传递和值传递:
第一个栗子:基本类型
void foo(int value) {
value = 88;
}
foo(num); // num 没有被改变
第二个栗子:没有提供改变自身方法的引用类型
void foo(String text) {
text = "mac";
}
foo(str); // str 也没有被改变
第三个栗子:提供了改变自身方法的引用类型
StringBuilder sb = new StringBuilder("vivo");
void foo(StringBuilder builder) {
builder.append("5");
}
foo(sb); // sb 被改变了,变成了"vivo5"。
第四个栗子:提供了改变自身方法的引用类型,但是不使用,而是使用赋值运算符。
StringBuilder sb = new StringBuilder("oppo");
void foo(StringBuilder builder) {
builder = new StringBuilder("vivo");
}
foo(sb); // sb 没有被改变,还是 "oppo"。
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
三 引用的类型



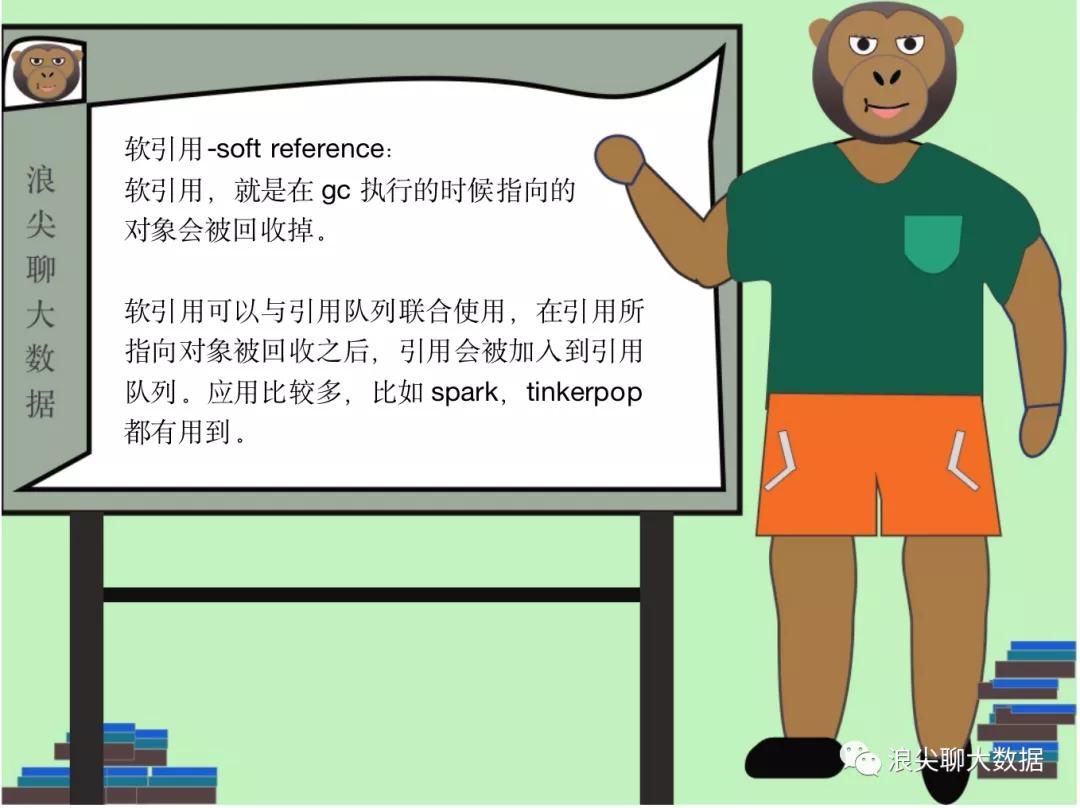
单纯的申明一个软引用,指向一个person对象
1 SoftReference pSoftReference=new SoftReference(new Person(“张三”,12));
声明一个引用队列
ReferenceQueue<Person> queue = new ReferenceQueue<>();
声明一个person对象,李四,obj是其强引用
Person obj = new Person(“李四”,13);
使软引用softRef指向李四对应的对象,并且将该软引用关联到引用队列
2 SoftReference softRef = new SoftReference<Object>(obj,queue);
声明一个person对象,名叫王酒,并保证其仅含软引用,且将软引用关联到引用队列queue
3 SoftReference softRef = new SoftReference<Object>(new Person(“王酒”,15),queue);
使用很简单softRef.get即可获取对应的value。
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
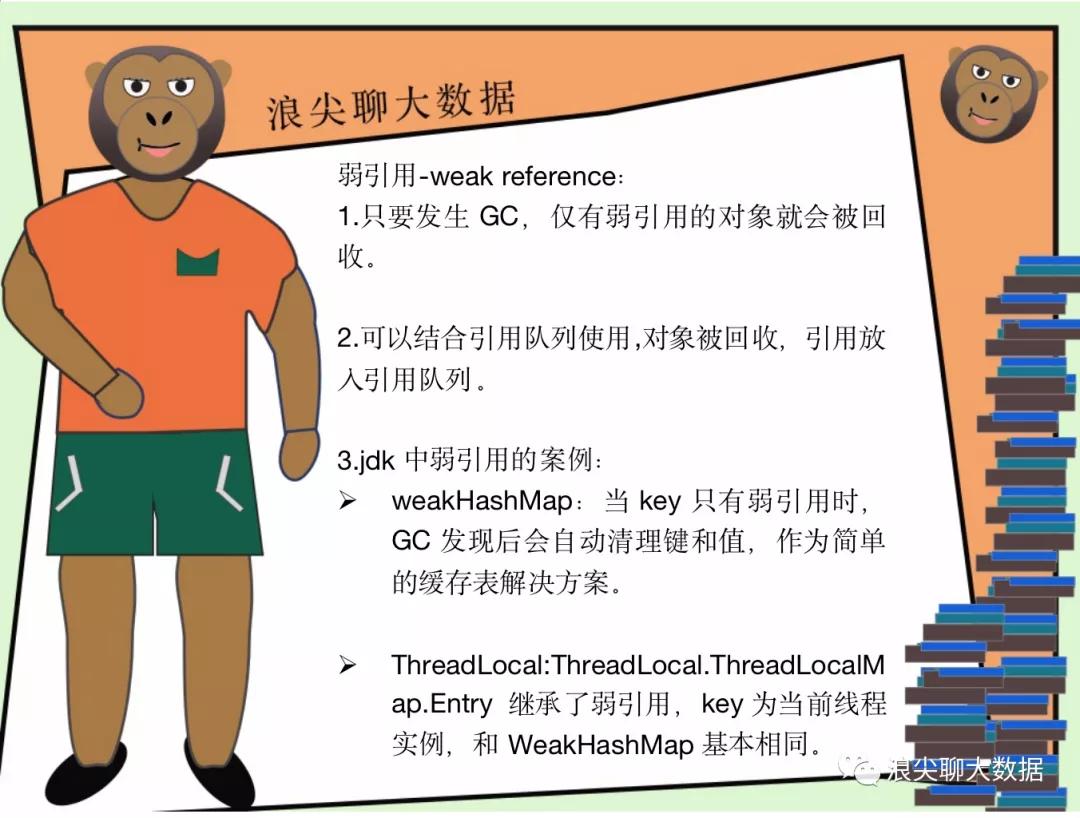
WeakReference<Person> weakReference = new WeakReference<>(new Person(“浪尖”,18));
声明一个引用队列
ReferenceQueue<Person> queue = new ReferenceQueue<>();
声明一个person对象,李四,obj是其强引用
Person obj = new Person(“李四”,13);
声明一个弱引用,指向强引用obj所指向的对象,同时该引用绑定到引用队列queue。
WeakReference weakRef = new WeakReference<Object>(obj,queue);
使用弱引用也很简单,weakRef.get
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.

声明引用队列
ReferenceQueue queue = new ReferenceQueue();
声明一个虚引用
PhantomReference<Person> reference = new PhantomReference<Person>(new Person(“浪尖”,18), queue);
获取虚引用的值,直接为null,因为无法通过虚引用获取引用对象。
System.out.println(reference.get());
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.

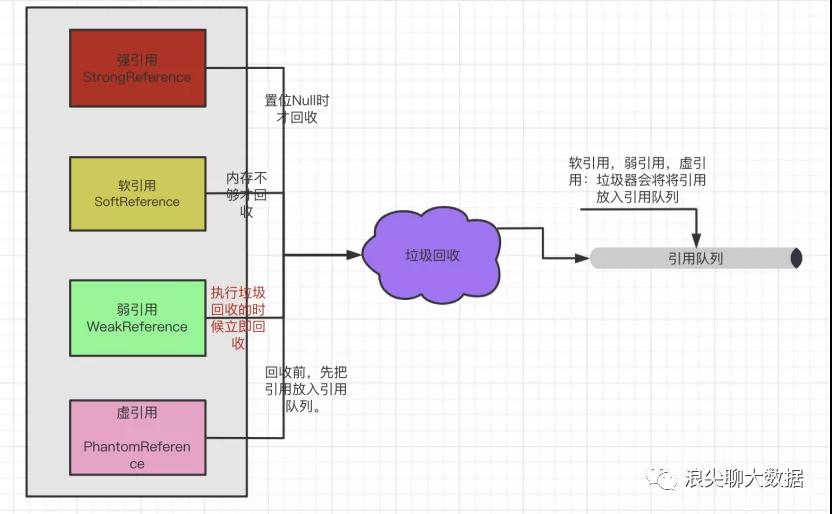

四 Threadlocal如何使用弱引用

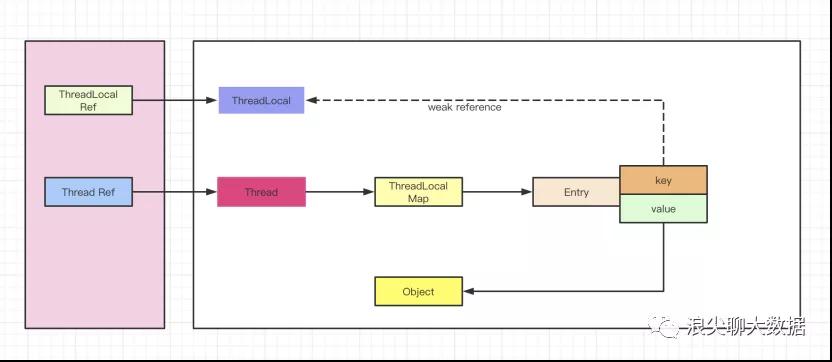
五 spark如何使用弱引用进行数据清理

shuffle相关的引用,实际上是在ShuffleDependency内部实现了,shuffle状态注册到ContextCleaner过程:
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
- 1.
然后,我们翻开registerShuffleForCleanup函数源码可以看到,注释的大致意思是注册ShuffleDependency目的是在垃圾回收的时候清除掉它对应的数据:
/** Register a ShuffleDependency for cleanup when it is garbage collected. */
def registerShuffleForCleanup(shuffleDependency: ShuffleDependency[_, _, _]): Unit = {
registerForCleanup(shuffleDependency, CleanShuffle(shuffleDependency.shuffleId))
}
- 1.
- 2.
- 3.
- 4.
其中,registerForCleanup函数如下:
/** Register an object for cleanup. */
private def registerForCleanup(objectForCleanup: AnyRef, task: CleanupTask): Unit = {
referenceBuffer.add(new CleanupTaskWeakReference(task, objectForCleanup, referenceQueue))
}
- 1.
- 2.
- 3.
- 4.
referenceBuffer主要作用保存CleanupTaskWeakReference弱引用,确保在引用队列没处理前,弱引用不会被垃圾回收。
/**
* A buffer to ensure that `CleanupTaskWeakReference`s are not garbage collected as long as they
* have not been handled by the reference queue.
*/
private val referenceBuffer =
Collections.newSetFromMap[CleanupTaskWeakReference](new ConcurrentHashMap)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
ContextCleaner内部有一个线程,循环从引用队列里取被垃圾回收的RDD等相关弱引用,然后完成对应的数据清除工作。
private val cleaningThread = new Thread() { override def run(): Unit = keepCleaning() }
- 1.
其中,keepCleaning函数,如下:
/** Keep cleaning RDD, shuffle, and broadcast state. */
private def keepCleaning(): Unit = Utils.tryOrStopSparkContext(sc) {
while (!stopped) {
try {
val reference = Option(referenceQueue.remove(ContextCleaner.REF_QUEUE_POLL_TIMEOUT))
.map(_.asInstanceOf[CleanupTaskWeakReference])
// Synchronize here to avoid being interrupted on stop()
synchronized {
reference.foreach { ref =>
logDebug("Got cleaning task " + ref.task)
referenceBuffer.remove(ref)
ref.task match {
case CleanRDD(rddId) =>
doCleanupRDD(rddId, blocking = blockOnCleanupTasks)
case CleanShuffle(shuffleId) =>
doCleanupShuffle(shuffleId, blocking = blockOnShuffleCleanupTasks)
case CleanBroadcast(broadcastId) =>
doCleanupBroadcast(broadcastId, blocking = blockOnCleanupTasks)
case CleanAccum(accId) =>
doCleanupAccum(accId, blocking = blockOnCleanupTasks)
case CleanCheckpoint(rddId) =>
doCleanCheckpoint(rddId)
}
}
}
} catch {
case ie: InterruptedException if stopped => // ignore
case e: Exception => logError("Error in cleaning thread", e)
}
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
shuffle数据清除的函数是doCleanupShuffle,具体内容如下:
/** Perform shuffle cleanup. */
def doCleanupShuffle(shuffleId: Int, blocking: Boolean): Unit = {
try {
logDebug("Cleaning shuffle " + shuffleId)
mapOutputTrackerMaster.unregisterShuffle(shuffleId)
shuffleDriverComponents.removeShuffle(shuffleId, blocking)
listeners.asScala.foreach(_.shuffleCleaned(shuffleId))
logDebug("Cleaned shuffle " + shuffleId)
} catch {
case e: Exception => logError("Error cleaning shuffle " + shuffleId, e)
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
细节就不细展开了。

ContextCleaner的start函数被调用后,实际上启动了一个调度线程,每隔30min主动调用了一次System.gc(),来触发垃圾回收。
/** Start the cleaner. */
def start(): Unit = {
cleaningThread.setDaemon(true)
cleaningThread.setName("Spark Context Cleaner")
cleaningThread.start()
periodicGCService.scheduleAtFixedRate(() => System.gc(),
periodicGCInterval, periodicGCInterval, TimeUnit.SECONDS)
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
具体参数是:
spark.cleaner.periodicGC.interval
- 1.
本文转载自微信公众号「浪尖聊大数据」,可以通过以下二维码关注。转载本文请联系浪尖聊大数据公众号。














