












本文转载自公众号“读芯术”(ID:AI_Discovery)。
生活中的许多地方都在运用着数据库技术,例如诈骗检测、知识图谱、资产管理、推荐浏览器、物联网、权限管理等等。数据库技术能够快速分析相关度高的数据点以及其之间的联系,图形数据库便是其中之一。
但由于图形数据本身性质特殊,其在架构方面还面临诸多挑战。那么,图形数据库是否能够扩展呢?本文将全面分析可能阻碍图形数据库扩展的两个挑战,并讨论当前可用的解决方案。
什么是"图形数据库的可扩展性"?
“扩展”,不只是指将更多的数据存入一台计算机或随便存进多台计算机。对于大型数据集或不断增长的数据集,良好的查询性能十分必要。
所以,其中真正的问题在于,当单台计算机上的数据集增长到会影响其他功能时,图形数据库的表现能否令人满意呢?如果你还不能理解为什么这是首要问题,请和我一起快速回顾以下图形数据库。
简单来说,图形数据库用于存储无架构对象(顶点或节点)以及任意数据(属性)和对象(边缘)的关联数据。边通常能够指出对象之间的着力点,顶点和边共同构成图形网络数据集。
离散数学将图形定义为一组顶点和边;而计算机科学则将其定义为一种抽象的数据类型,它能够表示连接或关系。它不同于关系数据库系统中的表格数据结构,后者表达数据关系的能力十分有限。
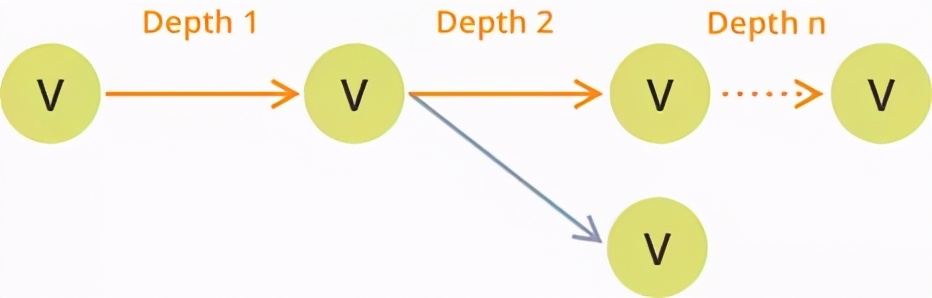
如上所述,图形由节点(又名顶点[V]) 组成,这些节点由关系(即边[E])连接。

顶点具有任意数量的边和任意深度(路径的长度)的窗体路径。
它也可以针对跨行金融交易进行图形建模,如下图所示。此例中,我们可以将银行帐户定义为节点,银行交易记录与其他关系定义为边缘。
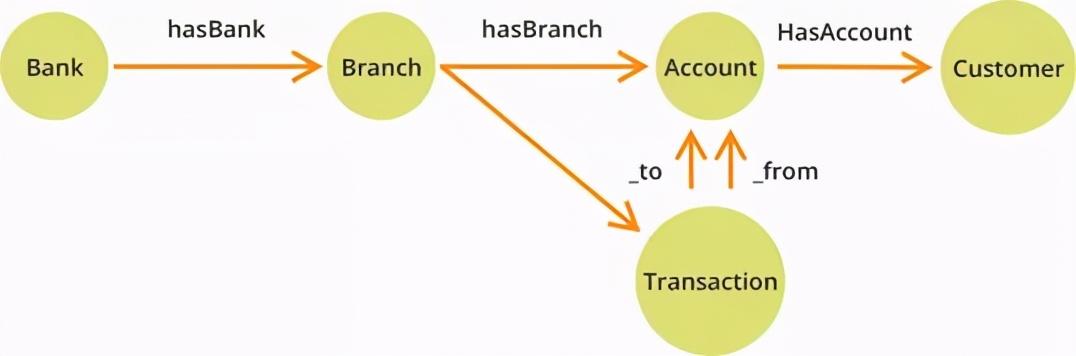
以这种方式存储帐户和交易信息,以遍历创建图形未知或变化的数据深度。在关系数据库中编写和运行此类查询功能往往是一项复杂的工作(使用多模型数据库能够以银行与其分支机构之间的关系来建模)。
图形数据库提供各种算法,以便用户查询所存储的数据及分析其间关系。包括遍历、模式匹配、最短路径或分布式图形处理,如分析社区侦测、连接组件或中心性。大多数算法都有一个共同点,这也是解决超节点和网络跃点问题的本质——算法通过边从一个节点遍历到另一个节点。
快速回顾之后,挑战就要开始啦!
“名人效应”
上文已提到顶点或节点可以具有任意数量的边。超级点的一个经典例子便是网红——超节点是图形数据集中传入或传出边条数过多的节点。帕特里克·斯图尔特爵士的Twitter账户目前就拥有340多万粉丝。
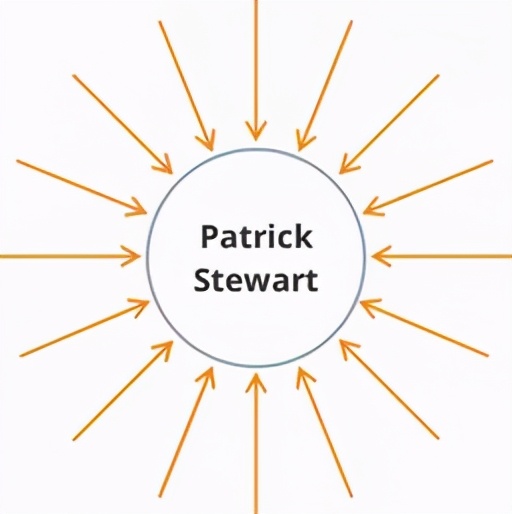
如果现在将帐户和推文数据进行图形建模,遍历其数据即Patrick Stewart的帐户信息,那么算法必须定向分析Steward帐户所有的340万条边。这就会延长查询执行时间,甚至可能突破被授权的权限。类似的问题存在于欺诈检测(帐户进行大量交易、网络管理-大型 IP hub)等案例中。
超级节点是图形的固有问题,也是所有图形数据库面临的问题,以下两种方法能尽量减少超节点的影响。
图源:unsplash
方法一:拆分超节点
更准确来说,可以复制节点"Patrick Stewart",并按某个属性(如粉丝的国家/地区或其他特定分组)拆分数据边缘。这样就会将超节点遍历数据对性能的影响降至最低,以便查询分类时所用。
方法二:中心节点索引
以顶点为中心的索引同时存储边缘信息和有关节点的信息。还是以帕特里克·斯图尔特的 Twitter 帐户为例,可以这样分组:粉丝的起始关注日期/时间信息、粉丝的国家/地区、粉丝的粉丝数等等,以上所有属性都可以为更高效地使用()提供选择性。
查询引擎可使用索引来减少执行遍历功能所需的线性查找次数,诈骗检测也可采用此方法。上文中金融交易便是边缘,交易日期或交易金额等属性可以增加选择效率。
某些情况下,以上两种方法都不适用;遍历超节点时,性能一定程度上会下降。多数情况下,还是有办法优化性能,但另一个问题是大多数图形数据库尚未解决的。
网络跃点问题
假如需要遍历一个高度连接的数据集,查询所需的所有数据的记忆都负荷在同一台计算机上,查询单个主要记忆大约需要100ns。
假设数据集已经远远满足单个实例所需,或者操作者想要提高群集或是全包的可用性和处理能力。在图形案例中,分片的意思就是拆除之前所建立的连接,因为图形遍历所需的数据当前可能留在不同计算机上。这会导致的查询信息时网络延迟,网络可能不是开发人员的问题,但查询性能就是了。
即使现代Gbit 网络和服务器位于同一机架,网络查找的成本也比内存中在查找贵5000倍左右。若在连接群集服务器的网络上添加一点负载,后果不可预想。
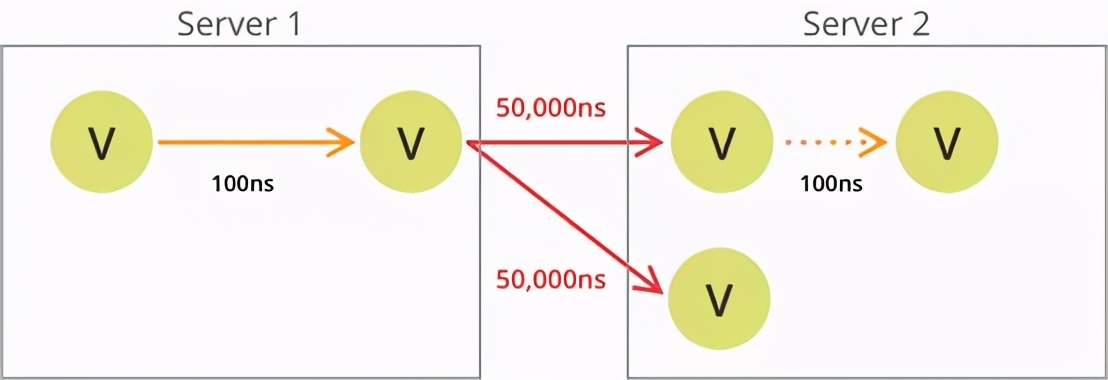
这种情况下,遍历可能从数据库服务器1开始,点击具有指向存储在 DB Server 2上的顶点边缘的节点,从而通过网络进行查找网络跃点。考虑到更多实际中的情况,在单个遍历查询中,实际上是存在多个跃点的。
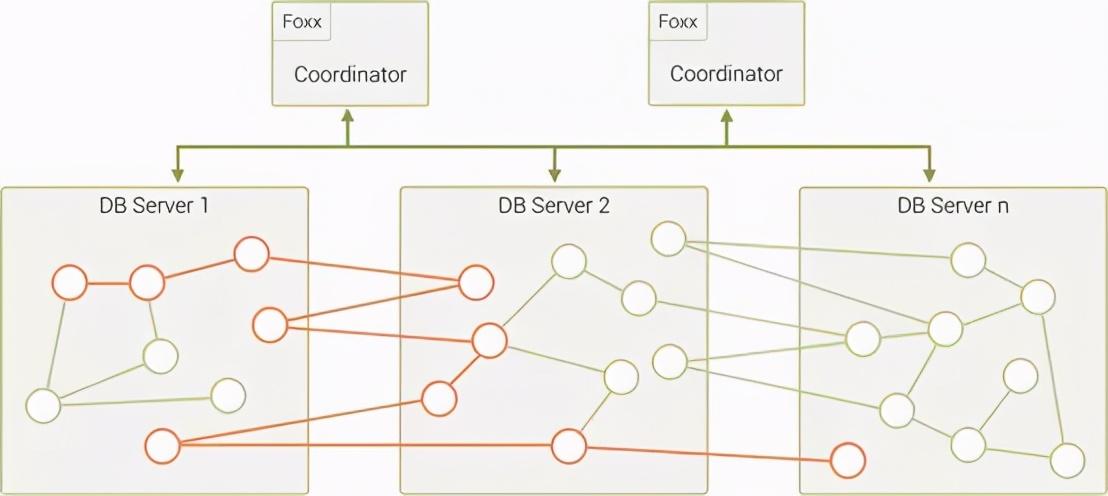
在诈骗检测、IT网络管理,甚至现代企业识别和访问管理案例中,可能会涉及到分配图形数据,同时还需要以低于秒的性能执行查询功能。而查询执行期间产生的大量网络跃点可能会使之失败,付出高昂的缩放代价。
更智能的解决方法
大多数情况下,如果对数据有一些了解,你就可以更智能地来分片图形(客户 ID、区域等)。其他时候,也可以使用分布式图形分析,通过使用社区检测算法(例如ArangoDB的Pregel 套件)生成此域知识,从而进行计算。
例如,诈骗检测就需要分析财务交易以确定诈骗套路。在过去,骗子利用某些国家或地区的银行来洗钱。我们可以使用此领域知识作为图形数据集的分片密钥,并在 DB 服务器1上分配在此区域执行的所有财务事务,并在其他服务器上分配处理其他事务。
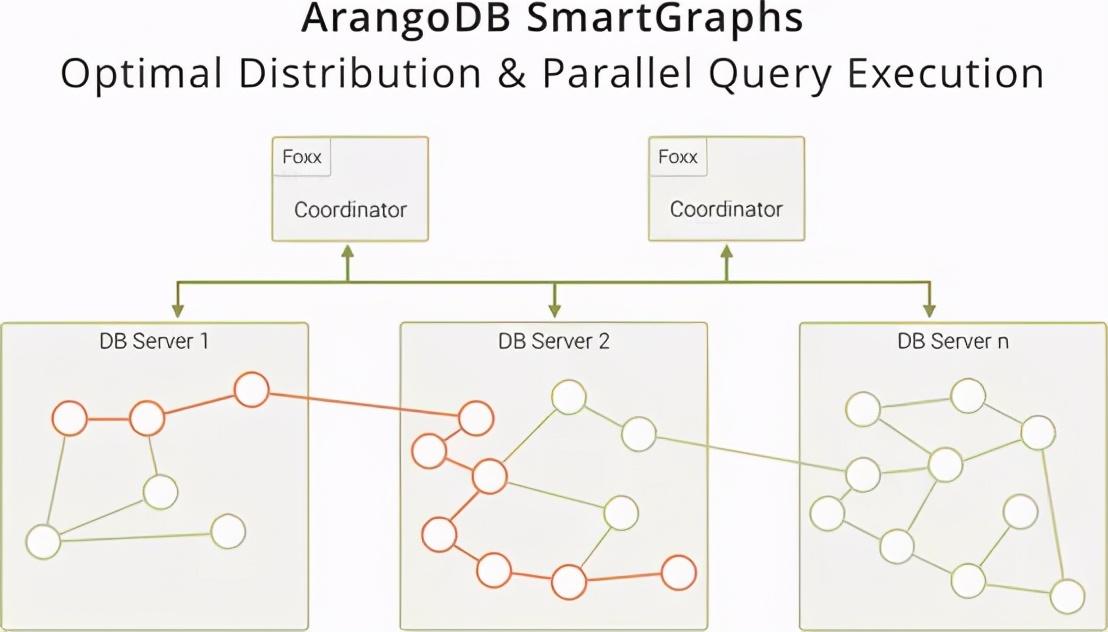
而现在,使用ArangoDB的SmartGraph功能,本地就能阻止洗钱或查询其他图形的请求,避免或至少大幅度降低了查询期间所产生的网络跃点。这究竟是如何做到的?
ArangoDB中的查询引擎能够记忆遍历所需的数据存储位置,并向每个数据库服务器的查询引擎发送请求,然后在本地处理请求。之后,每个数据库服务器上结果的差异会被合并到协调器并发送到客户端。对于层次分明的图形,还可以利用不相交的智能图来优化查询。
对于解决数据缩放问题的呼声越来越高,而图形技术对于回答此类复杂的问题也愈发重要。
笔者可以肯定地说,图形数据库在垂直方向上扩展是可行的,在ArangoDB中,水平扩展也能实现。当然,在有些极端不常见的情况下,中心节点索引和SmartGraphs也都无能为力。



















