【51CTO.com原创稿件】想做营销活动,如何找到目标人群及用户特征?人群的筛选通常离不开用户画像。
图片来自 Pexels
用户画像就是根据用户特征、业务场景和用户行为等信息,构建一个标签化的用户模型。
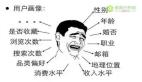
比如消费者用户画像分为属性和行为标签两类。这两类标签,一个是固定的,一个是可变的。
固定的属性标签基本就是买家的性别,年龄段,会员等级,消费水平,购买力等。而可变的行为标签基本包括买家的浏览,加购物车,购买等行为。
通过多年的建设,苏宁构建了完整的用户标签体系,覆盖零售、金融、体育等多个产业。
同时搭建了标签服务平台,通过开放丰富的标签数据能力,为广告、推荐等提供智能化的标签中台服务能力。
随着数据的日益增多,如何对 6 亿+用户千亿级别的标签数据进行秒级用户画像?
本文将带来用户画像技术的新发展和架构实践,介绍基于 ClickHouse 定制开发的标签平台,真正做到海量标签数据的快速导入和秒级用户画像查询分析,提供一整套从前期人群筛选到后期的营销策略优化的标签体系。
业务场景介绍
“双 11”到了,假设需要发放 1000 万张家电类优惠券,那我们首先需要根据标签筛选出符合条件的人群,人数大约为 1000 万左右,然后对选择的人群进行画像分析,看是否符合预期的特征。
如果人群符合特征,系统将一键生成进行营销的人群包(userid 列表),自动化发布和营销。
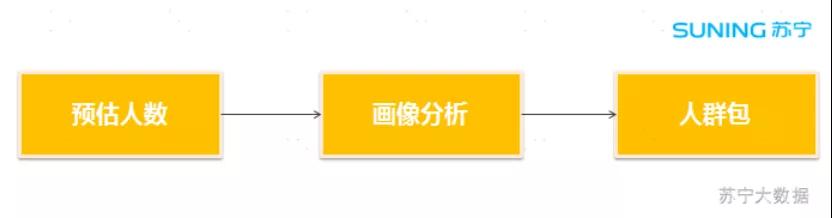
图 1:业务流程
预估人数
用户选择标签及标签之间的交并差关系,圈选出符合条件的人群,实时预估出人群的数量。
比如选择:
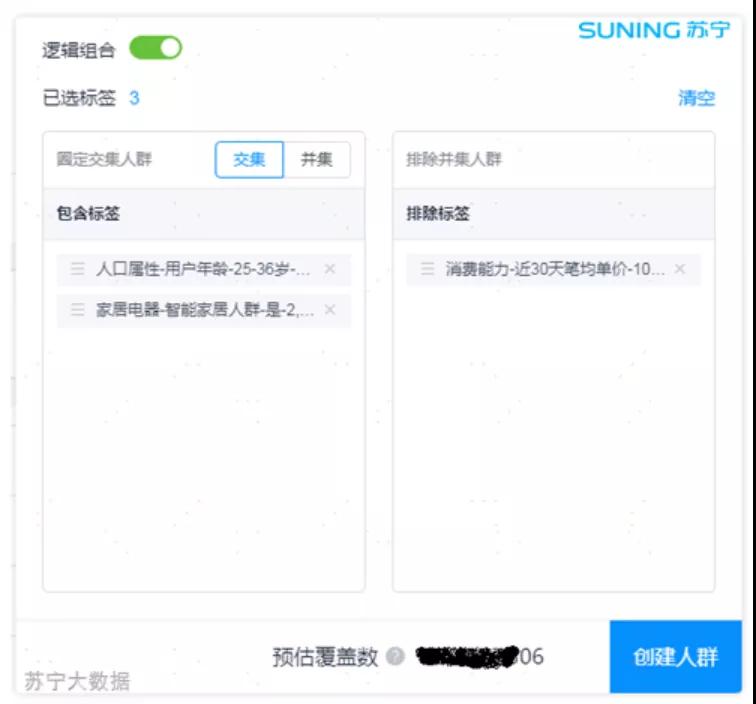
图 2:创建人群
上图的标签选择的含义为:“用户年龄范围为 25-36 岁”并且为“智能家居特征”的人群,排除最近 30 天消费小于 10 元的人群。
表示为集合运算的公式为:
- { {用户年龄 25-36} ∩ {智能家居人群} } - {30天消费小于10元}
技术难点有:
- 人群包的个数多。
- 每个人群包的用户基数较大。
- 系统实时输出计算结果,难度大。
画像分析
当筛选出用户数与规划的消费券的数量匹配时,需要对人群进行特征分析,看看人群是否符合特征要求。
用户画像表的结构举例如下:
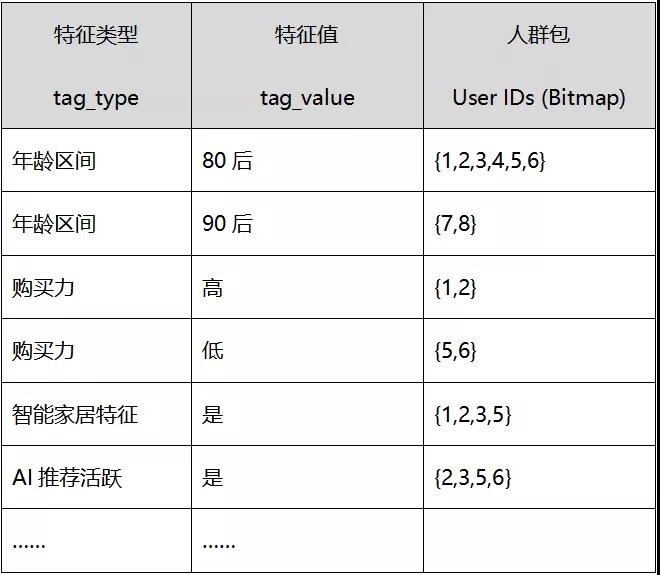
将筛选出的人群包与用户画像表进行关联,详细分析关联出的画像特征。也可以进一步对画像特征进行一些历史数据分析。
我们之前的解决方案是将用户标签存储在 ElasticSearch 的大宽表中的。大宽表的结构是:一个用户下挂一堆 tag 的表结构。
在向大宽表插入数据时,需要等待业务的数据都准备好后,才能跑关联表操作,然后将关联的结果插入到 ES。
经常遇到的情况是:某个业务方的任务延迟,导致插入 ES 的关联任务无法执行,运营人员无法及时使用最新的画像数据。
在 ES 中修改文档结构是比较重的操作,修改或者删除标签比较耗时,ES 的多维聚合性能比较差,ES 的 DSL 语法对研发人员不太友好,所以我们将标签存储引擎从 ES 替换为 ClickHouse。
ClickHouse 是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。凭借优异的查询性能,受到业界的青睐,各个大厂纷纷跟进大规模使用它。
苏宁大数据已将 ClickHouse 引入并改造,封装成丰富的 Bitmap 接口,用来支撑标签平台的存储及分析。
ClickHouse 集成 Bitmap
我们在 ClickHouse 中集成了 RoaringBitmap,实现了 Bitmap 计算功能集,并贡献给开源社区。
对 userid 进行位图方式的压缩存储,将人群包的交并差计算交给高效率的位图函数,这样既省空间又可以提高查询速度。
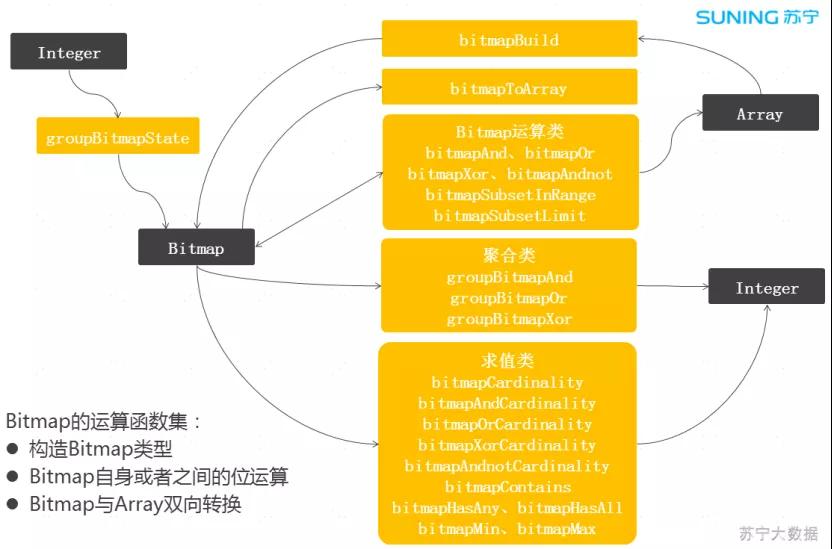
图 3:ClickHouse 集成 Bitmap
围绕 Bitmap 对象实现了一套完善的计算函数。Bitmap 对象有两种构建方式,一种是从聚合函数 groupBitmap 构建,另一种是从 Array 对象构建,也可以将 Bitmap 对象转换为 Array 对象。
ClickHouse 的 Array 类型有大量的函数集,这样可以更加方便的加工数据。
上图的中间部分是 Bitmap 的计算函数集,有位运算函数、聚合运算函数、求值类运算函数,比较丰富。
基于 ClickHouse 的新架构
架构介绍
架构图如下:
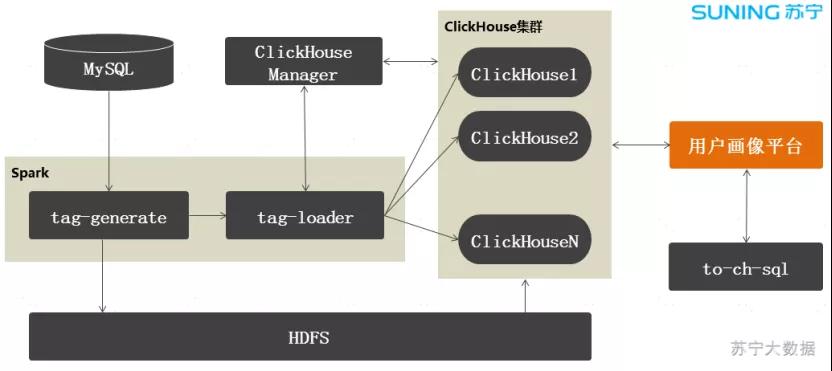
图 4:标签架构
ClickHouse Manager 是我们自研的 ClickHouse 管理平台,负责集群管理、元数据管理和节点负载协调。
Spark 任务负责标签数据的生成和导入,当某个业务方的任务跑完后,会立刻调用 tag-generate 生成标签数据文件,存放到 HDFS,然后在 ClickHouse 上执行从 HDFS 导入到 ClickHouse 的 SQL 语句,这样就完成了标签的生产工作。
标签生产是并发跑的,假设某个业务方的数据没有准备好,不影响其他业务的标签生产。
用户画像平台通过 Proxy 从 ClickHouse 集群查询标签数据。在查询前,需要将查询表达式转换为 SQL,我们对这块逻辑做了一个封装,提供一个通用的转换模块,叫做:to-ch-sql。
业务层基本上不用修改就可以查询 ClickHouse 了。
标签数据表的基本结构
相对于 ElasticSearch 的存储结构,我们将标签存储做了一个行转列存储。每个标签对应一个 Bitmap 对象。
Bitmap 对象中存储 userid 集合:
- CREATE TABLE ch_label_string
- (
- labelname String, --标签名称
- labelvalue String, --标签值
- uv AggregateFunction( groupBitmap, UInt64 ) --userid集合
- )
- ENGINE = AggregatingMergeTree()
- PARTITION BY labelname
- ORDER BY (labelname, labelvalue)
- SETTINGS index_granularity = 128;
uv 字段为 Bitmap 类型的字段,将整形的 userid 存入,每个 userid 用一个 bit 位表示。
主键索引(index_granularity)默认为 8192,修改为 128 或者其他数值,由于 Bitmap 占用的存储空间比较大,修改为小数值,以减少稀疏索引的读放大问题。
根据标签值的数据类型划分为四种类型的表:
- String
- Integer
- Double
- Date
标签名称作为 Partition。通过这样的设计,增加或者删除标签数据都比较方便,只需要修改 Partition 的数据就可以了。Partition 的管理有相应的 SQL 语句,操作比较方便。
Userid 分片存储
在标签数据导入时,按照 userid 分片导入,每台机器仅存储对应 userid 的标签数据。
每台机器分别导入分片后的标签数据,实现了数据并行导入。在我们的环境上单机导入性能在 150 万条/秒左右。
在根据标签筛选人群时,SQL 仅需要在单个 shard 上执行,中间结果不需要返回给查询节点。
在执行“预估人数”计算时,优势特别明显:每个 shard 仅需要返回符合条件的人数,在查询节点做 sum 操作,然后将 sum 结果返回给客户端。充分挖掘了 ClickHouse 分布式并行计算的能力。
查询流程
采用 with 语句进行计算出人群包的 Bitmap 对象,然后用 Bitmap 函数进行交并差的计算。
当需要计算的标签比较多时,标签查询的 SQL 比较复杂,将标签查询 SQL 包装到分布式代理表的 SQL 中,分布式代理表本身不存储数据,通过代理表标识到哪些节点上查询,分布式代理表所标识的节点上执行标签查询 SQL。
然后在分布式代理表上汇总查询结果。通过 ClickHouse 分布式表的自身特性,实现了标签查询的 colocate 机制。
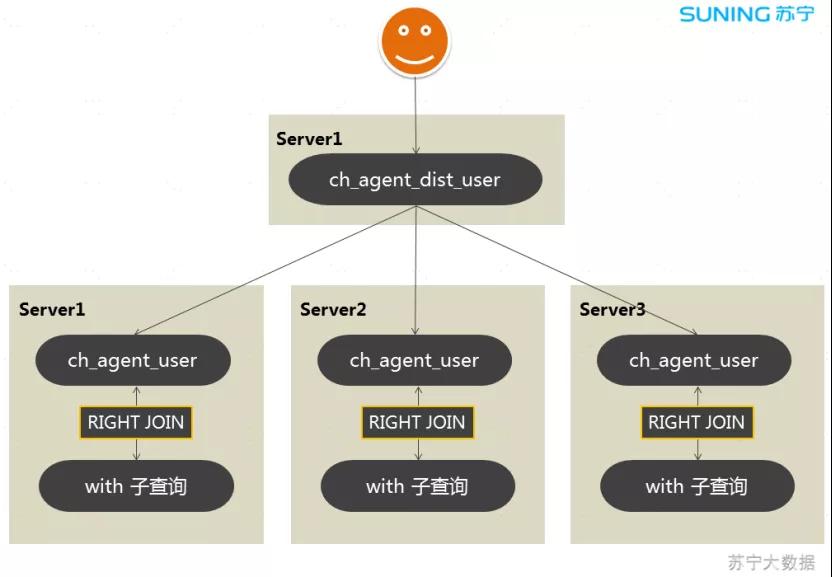
图 5:查询流程
示例 SQL 如下:
- -- 本地查询代理
- CREATE TABLE ch_agent_user
- (
- agentname String
- )
- ENGINE = MergeTree()
- PARTITION BY agentname
- ORDER BY (agentname)
- SETTINGS index_granularity = 8192;
- -- 分布式代理表
- CREATE TABLE ch_agent_dist_user AS ch_agent_user
- ENGINE = Distributed('cluster_test', 'test', 'ch_agent_user', cityHash64(agentname))
- -- 查询用户数
- SELECT sum(user_number) AS user_number
- FROM ch_agent_dist_user
- RIGHT JOIN
- (
- WITH
- (
- SELECT groupBitmapState(userid) AS users0
- FROM ch_label_string
- WHERE labelname = 'T'
- ) AS users0
- SELECT
- 'agent' AS agentname,
- bitmapCardinality(users0) AS user_number
- ) USING (agentname) settings enable_scalar_subquery_optimization = 0;
ch_agent_user 表本身不存储数据,当与 with 语句进行 right join 关联查询时,由于是右关联查询,查询结果以 with 语句的结果集为准。
各个节点的查询结果返回给查询节点,查询节点进行汇总计算。参数 enable_scalar_subquery_optimization = 0 表示 with 语句的查询结果不做优化,每个节点都需要执行。
默认情况,在 ClickHouse 中 with 语句的结果作为标量进行缓存,会将查询节点的标量分发到其他服务器,当发现已经存在标量时,就不会在本地节点执行 with 语句。
我们期望 with 语句在每个节点都执行,所以将这个参数设置为 0。
用户画像
用户画像对性能要求比较高,查询平均响应时间不能大于 5 秒。用户在界面上任意圈选人群,然后实时对圈选后的人群进行画像分析。
用户画像技术进行了三次架构重构:
①V1:大宽表模式
最早的方案是创建一张 userid 为主键的画像表,表的其他字段为画像的特征字段,将圈选的人群与画像表进行 in 操作,然后 group by 操作。
这种设计带来两个比较严重的问题:
- 当增加或者删除特征字段时,画像表的表结构需要修改。
- 当圈选的人群数量比较大时,涉及到大记录集的 group by 运算,性能差。
②V2:Bitmap 模式
将一个特征值下的 userid 集合做为 Bitmap 对象存储到一条记录中,一条记录的内容如下:

用户圈选的人群 Bitmap 对象与画像表的 Bitmap 对象进行与(AND)操作,返回圈选人群的画像信息。
通过这样设计,基本上满足了性能要求,平均时间小于 5 秒,但是一些大的人群包,画像的性能还是差,在 10 秒左右。
画像表的记录数据量不大,但画像表的 Bitmap 字段在计算时需要从磁盘上反序列化出来。有的 Bitmap 对象占用几百兆的空间,导致了性能的下降。
③V3:Join 表引擎模式
ClickHouse 的 Join 表引擎可以将数据常驻到内存。当插入数据时,数据先写入内存,然后刷到磁盘文件,系统重启时,自动把数据加载回内存。Join 表引擎可以说是常驻内存的带持久化功能的表。
我们把画像表的数据保存到 Join 表引擎,画像表的 Bitmap 字段就常驻内存了,当圈选的人群 Bitmap 对象进行与(AND)操作时,两个内存中已经加载的 Bitmap 对象之间的计算就非常快。
通过这次优化平均查询时间优化到 1 到 2 秒,千万级人群画像分析不超过 5 秒。
总结
通过 ClickHouse 集成 Bitmap 功能,以及 Join 表引擎的应用,对架构进行了一系列优化后,极大的提升了标签平台的数据分析能力。
新的架构主要有以下优势:
- 标签数据可以并行构建,加快标签数据生产速度。
- HDFS 文件并发导入 ClickHouse,加快标签数据的就绪速度。
- 查询请求平均响应时长在 2 秒以下,复杂查询在 5 秒以下。
- 支持标签数据准实时更新。
- 标签表达式和查询 SQL 对用户来说比较友好,提升系统的易维护性。
- 相对于 ElasticSearch 的配置,可以节约一半硬件资源。
未来规划:
- 目前 ClickHouse 采用 RoaringBitmap 的 32 位版本,准备增加 64 位版本。
- ClickHouse 查询的并发性较低,增加更加智能的 Cache 层。
- 支持 ClickHouse 数据文件离线生成,进一步提示标签的就绪速度。
参考:
- ClickHouse 官网:https://clickhouse.tech/
- ClickHouse 中文社区:http://www.clickhouse.com.cn/
- Bitmap PR:https://github.com/ClickHouse/ClickHouse/pull/4207
作者:杨兆辉
简介:苏宁科技集团大数据中心高级架构师,ClickHouse Contributor。在 OLAP 领域、大规模分布式计算领域有着深厚的技术积累,目前负责数据中台、标签平台相关的架构工作。
编辑:陶家龙
征稿:有投稿、寻求报道意向技术人请联络 editor@51cto.com
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】