域适应是计算机视觉的一个领域,我们的目标是在源数据集上训练一个神经网络,并确保在显著不同于源数据集的目标数据集上也有良好的准确性。为了更好地理解域适应和它的应用,让我们先看看它的一些用例。
我们有很多不同用途的标准数据集,比如GTSRB用于交通标志识别,LISA和LARA dataset用于交通信号灯检测,COCO用于目标检测和分割等。然而,如果你想让神经网络很好地完成你的任务,比如识别印度道路上的交通标志,那么你必须首先收集印度道路的所有类型的图像,然后为这些图像做标注,这是一项费时费力的任务。在这里我们可以使用域适应,因为我们可以在GTSRB(源数据集)上训练模型,并在我们的印度交通标志图像(目标数据集)上测试它。
在很多情况下,很难收集数据集,这些数据集具有训练鲁棒神经网络所需的所有变化和多样性。在这种情况下,在不同的计算机视觉算法的帮助下,我们可以生成具有我们需要的所有变化的大型合成数据集。然后在合成数据集(源数据集)上训练神经网络,并在真实数据集(目标数据集)上测试它。
为了更好地理解,我假设我们对目标数据集没有可用的标注,但这不是唯一的情况。
因此在域适应方面,我们的目标是在一个标签可用的数据集(源)上训练神经网络,并在另一个标签不可用的数据集(目标)上保证良好的性能。
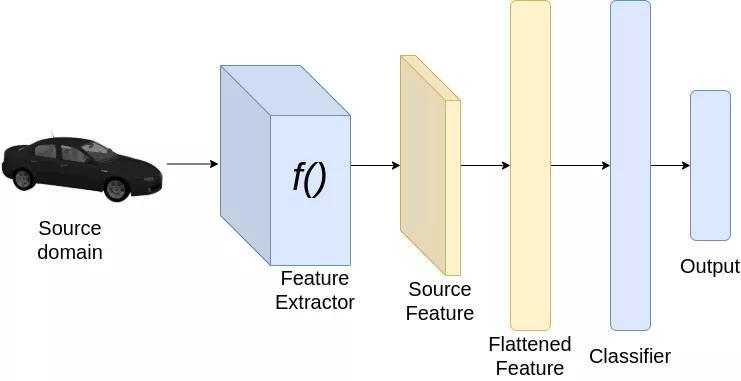
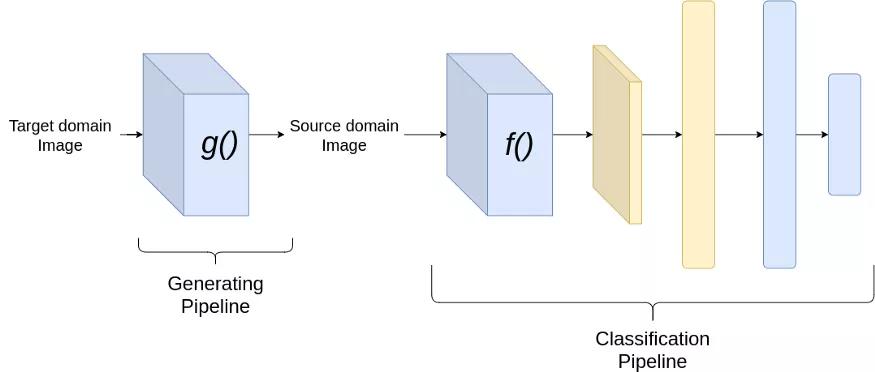
分类pipeline
现在让我们看看如何实现我们的目标。考虑以上图像分类的例子。为了从一个域适应到另一个域,我们希望我们的分类器能够很好地从源数据集和目标数据集中提取特征。由于我们已经在源数据集上训练了神经网络,分类器必须在源数据集上表现良好。然而,为了使分类器在目标数据集上表现良好,我们希望从源数据集和目标数据集提取的特征是相似的。因此,在训练时,我们加强特征提取,为源和目标域图像提取相似的特征。
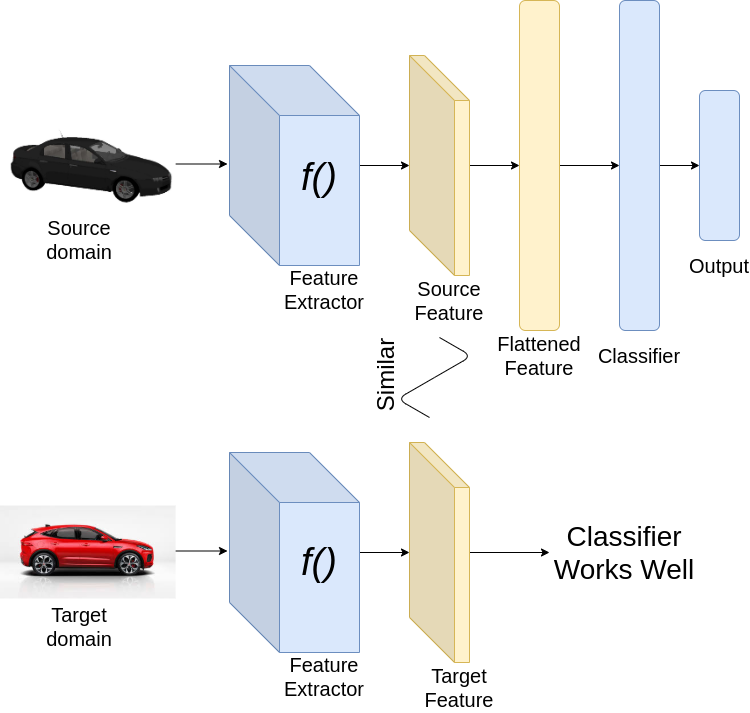
成功的域适应
基于目标域的域自适应类型
根据目标域提供的数据类型,域适应可分为以下几类:
- 监督 — 你已经标记了来自目标域的数据,目标域数据集的大小比源数据集小得多。
- 半监督 — 你既有目标域的标记数据也有未标记数据。
- 无监督的 — 你有很多目标域的未标记样本。
域适应技术
主要采用三种技术实现任意域适应算法。以下是域适应的三种技术:
- 基于分布的域适应
- 基于对抗性的域适应
- 基于重建的域适应
现在让我们逐个来看每种技术。
基于分布的域适应
基于散度的域适应原理是最小化源与目标分布之间的散度准则,从而得到域不变性特征。常用的分布准则有对比域描述、相关对齐、最大平均差异(MMD),Wasserstein等。为了更好地理解这个算法,让我们先看看一些不同的分布。
在最大平均差异(MMD)中,我们试图找出给定的两个样本是否属于相同的分布。我们将两个分布之间的距离定义为平均嵌入特征之间的距离。如果我们有两个在集合X上的分布P和Q。MMD通过一个特征映射来定义,: X→H,这里H再生核希尔伯特空间。MMD的公式如下:
为了更好地了解MMD,请查看以下描述:如果两个分布的矩相似,则它们是相似的。通过使用kernel,我可以对变量进行变换,从而计算出所有的矩(一阶,二阶,三阶等)。在潜在空间中,我可以计算出矩之间的差值并求其平均值。
在相关对齐中,我们尝试对源和目标域之间的相关(二阶统计量)进行对齐,而不是使用MMD中的线性变换对均值进行对齐。
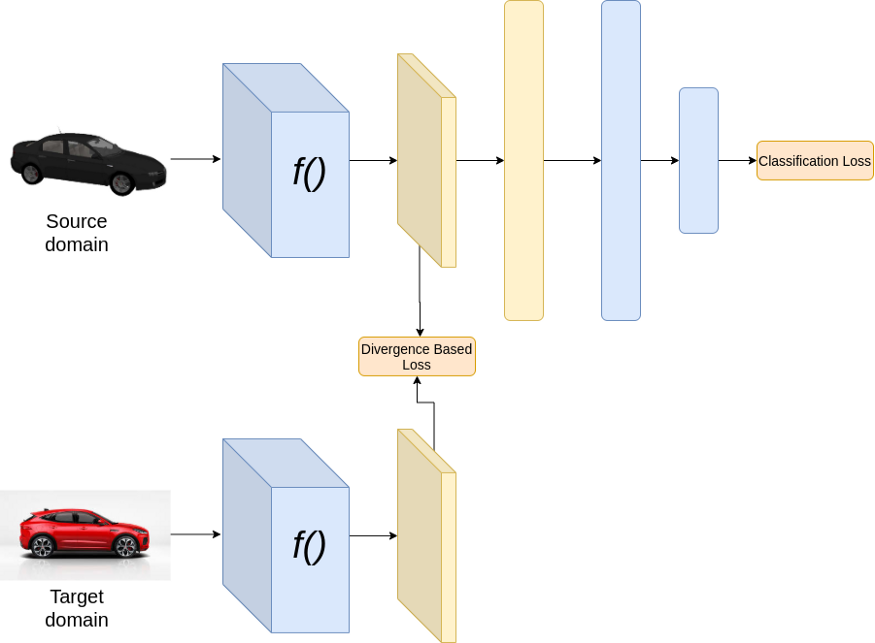
训练时
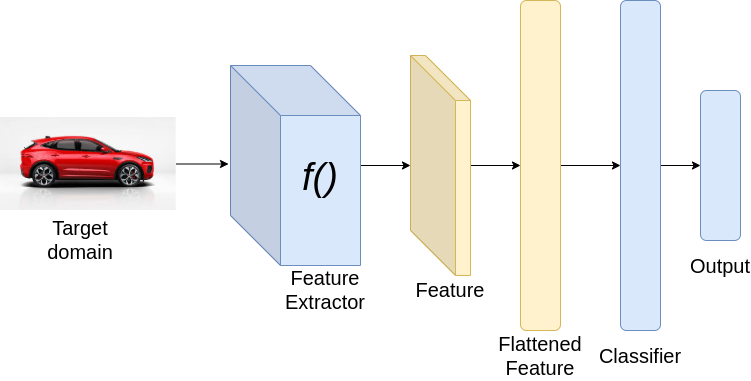
推理时
上面的结构假设源域和目标域有相同的类别。在上述架构中,在训练过程中,我们最小化了两种损失,分类损失和基于散度的损失。分类损失通过对特征提取器和分类器的权值进行更新,确保获得良好的分类性能。而散度损失则通过更新特征提取器的权值来保证源域和目标域的特征相似。在推理过程中,我们只需将目标域图像通过神经网络。
所有的分布通常是非参数而且是人工的数学公式,不是专门针对数据集或我们的问题的,如分类,目标检测,分割等。因此,这种基于分布的方法并不能很好地解决我们的问题。但是,如果分布可以通过数据集或问题来学习,那么它将比传统的预定义分布表现得更好。
基于对抗的域适应
为了实现基于对抗性的域适应,我们使用GANs。这里我们的生成器是简单的特征提取器,我们添加了新的判别器网络,学习区分源和目标域的特征。由于这是一个双人游戏,判别器帮助生成器产生的特征对于源和目标领域是不可区分的。由于我们有一个可学习的判别器网络,我们学习特定于我们的问题和数据集的特征提取,这可以帮助区分源和目标域,从而帮助生成器产生更鲁棒的特征,即,不能很容易区分的特征。
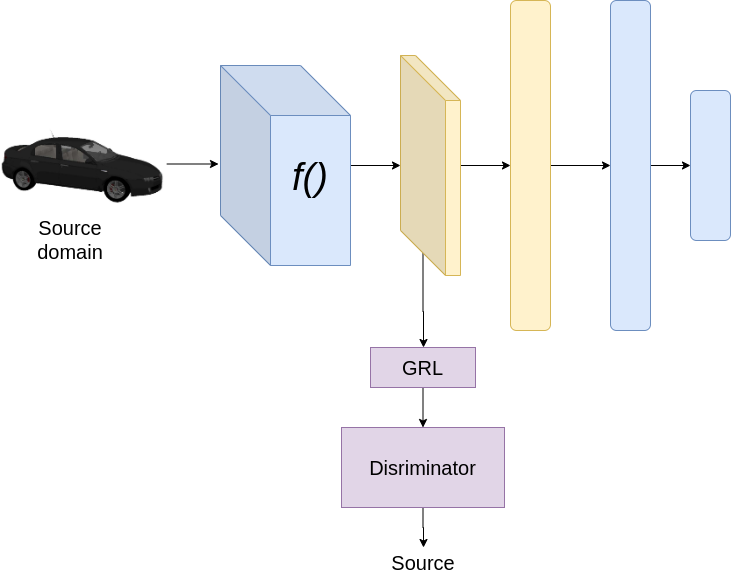
训练时,在源域上
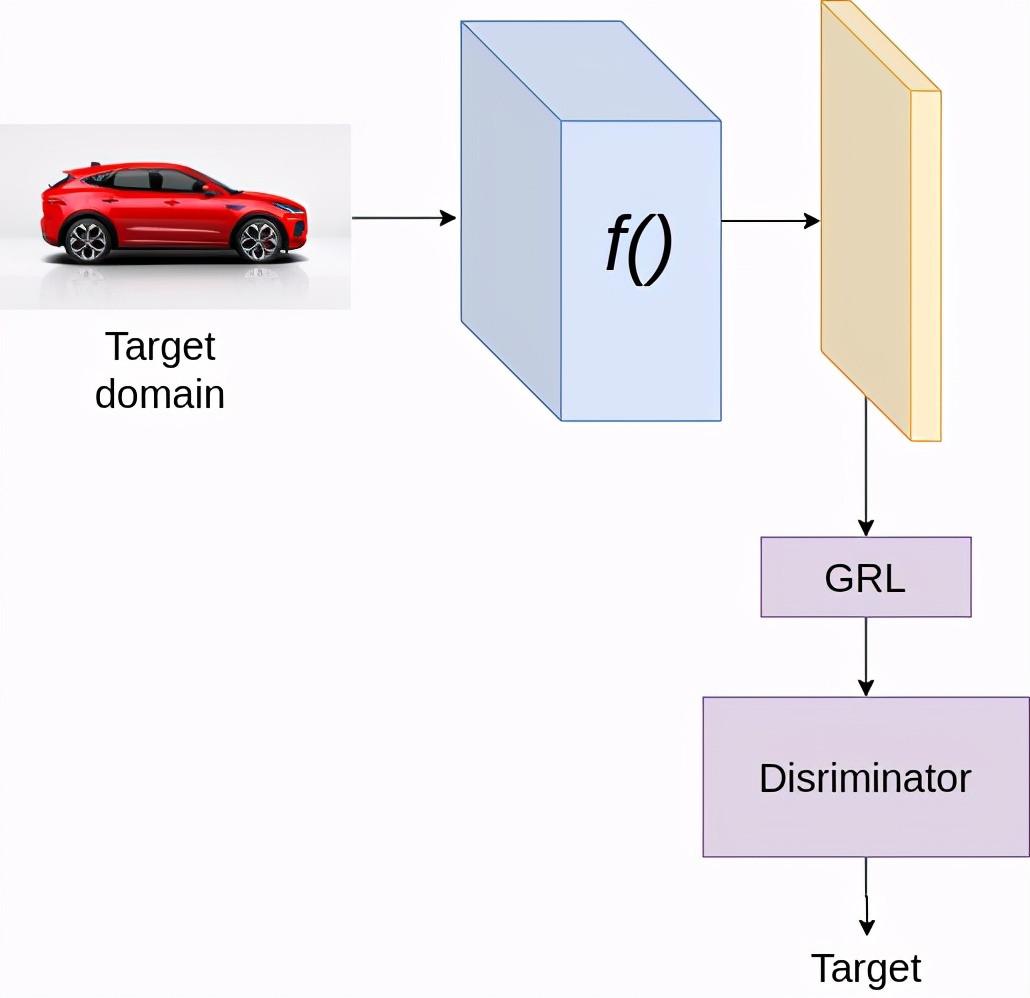
训练时,在目标域上
假设是分类问题,我们使用两种损失,分类损失和判别器损失。分类损失的目的已在前面说明。判别器损失有助于判别器正确地区分源域和目标域的特征。这里我们使用梯度反向层(GRL)来实现对抗性训练。GRL block是一个简单的block,它在反向传播时将梯度乘以-1或一个负值。在训练过程中,为了更新生成器,我们有来自两个方向的梯度,首先来自分类器,其次来自判别器。由于GRL的存在,判别的梯度乘以一个负值,导致训练生成器的效果与判别器相反。例如,如果优化判别器损失函数的计算梯度为2,那么我们使用-2(假设负值为-1)来更新生成器。通过这种方式,我们试图训练生成器,使其生成即使是判别器也无法区分源域和目标域的特征。GRL层在许多域适应的文献中都有广泛的应用。
基于重建的域适应
这是基于图像到图像的转换。一个简单的方法是学习从目标域图像到源域图像的转换,然后在源域上训练一个分类器。我们可以用这个想法引入多种方法。图像到图像转换的最简单模型可以是基于编码器-解码器的网络,并使用判别器强制编码器 — 解码器网络生成与源域相似的图像。
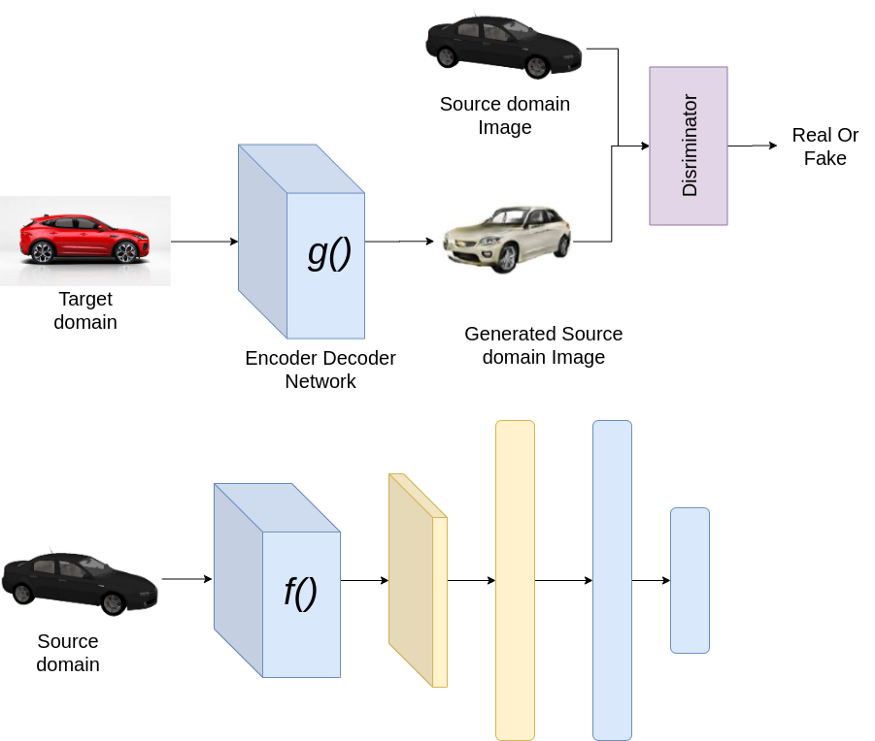
训练时
测试时
另一种方法是使用CycleGANs。在Cycle GAN中采用了基于两种编解码器的神经网络。一个用于将目标转换为源域,另一个用于将源转换为目标域。我们同时训练了生成两个域(源域和目标域)图像的GANs。为了保证一致性,引入了循环一致性损失。这可以确保从一个域转换到另一个域,然后再转换回来,得到与输入大致相同的图像。因此,两个配对网络的总损失和是判别器损失与循环一致性损失的和。
总结
我们已经看到了三种不同的技术,可以帮助我们实现或实施不同的域适应方法。它在图像分类、目标检测、分割等不同任务中都有很大的应用。在某些方面,我们可以说,这种方法类似于人类如何学习视觉识别不同的东西。我希望这个博客能让你了解我们是如何思考不同的域适应pipelines的。
英文原文:https://levelup.gitconnected.com/understanding-domain-adaptation-63b3bb89436f