Rust越来越受欢迎。因此,不管Rust是否对我们都具有战略意义,包括我自己在内的一组同事对其进行了为期半天的评估,以建立我们自己的观点。我们按照标准入门书进行了一些编码,查看了一些框架,并观看了“ Considering Rust”演示文稿。。总的结论大致是这样的:是的,一种不错的新编程语言,但是没有一个成熟的生态系统,也没有任何垃圾收集,对于我们的项目而言,这将是太麻烦和无用的。我的直觉与关于垃圾收集的评估不一致。因此,我做了一些进一步的挖掘和测试,并得出了当前的结论:Rust确实进行了垃圾收集,但是使用的是非常聪明的方式。
垃圾收集简史
当您查看Rust的网站并阅读介绍时,您会突然发现一个骄傲的声明,Rust没有垃圾收集器。如果您与我同龄,这会引起一些不好的回忆。有时候,您必须使用手动分配内存,malloc()然后稍后再释放它。如果过早释放它,则会遇到诸如无效的内存访问异常之类的攻击。如果忘记释放它,则会造成内存泄漏,从而使应用程序受阻。很少有人在第一次就做对。这根本没什么好玩的。
在研究Rust采取的方法之前,让我们简短地看看垃圾的实际含义。在Wikipedia中,有一个很好的定义:垃圾包括数据………在其上运行的程序在以后的任何计算中都不会使用。这意味着只有开发人员才能决定是否可以释放存储某些数据的内存段。但是,应用程序的运行时可以自动检测垃圾的子集。如果在某个时间点不再存在对内存段的引用,则程序将无法访问该段。并且,因此可以安全地删除它。
为了实际实现这种支持,运行时必须分析应用程序中的所有活动引用,并且必须检查所有已分配的内存引用(如果可以针对当前应用程序状态访问它们)。这是一项计算量很大的任务。在Java诞生的第一天,JVM突然冻结,不得不在相当长的时间内进行垃圾回收。如今,有很多用于垃圾收集的复杂算法,它们通常与应用程序同时运行。但是,计算复杂度仍然相同。
从好的方面来说,应用程序开发人员无需考虑手动释放内存段。永远不会有无效的内存访问异常。她仍然可以通过引用数据来创建内存泄漏,现在不再需要。(恕我直言,主要的示例是自写的缓存实现。老人的建议:切勿使用ehcache之类的方法。)但是,随着垃圾收集器的引入,内存泄漏的情况越来越少了。
Rust如何处理内存段
乍一看,Rust看起来很像C,尤其是其引用和取消引用。但是它具有处理内存的独特方法。每个内存段均由一个引用拥有。从开发人员的角度来看,始终只有一个变量拥有数据。如果此变量超出范围且不再可访问,则将所有权转移到其他变量或释放内存。
使用这种方法,不再需要计算所有数据的可达性。取而代之的是,每次关闭命名上下文时(例如,通过从函数调用返回),都会使用简单的算法来验证所用内存的可访问性。听起来好极了,以至于每个有经验的开发人员都可能立即想到一个问题:问题在哪里?
问题在于,开发人员必须照顾所有权。开发人员不必在整个应用程序中漫不经心地散布对数据的引用,而必须标记所有权。如果所有权没有明确定义,则编译器将打印错误并停止工作。
为了进行评估,与传统的垃圾收集器相比,该方法是否真的有用,我看到两个问题:
- 开发人员在开发时标记所有权有多难?如果她所有的精力都集中在与编译器进行斗争而不是解决域问题上,那么这种方法所带来的好处远不止于帮助。
- 与传统的垃圾收集器相比,Rust解决方案的速度快多少?如果收益不大,那为什么还要打扰呢?
为了回答这两个问题,我在Rust和Kotlin中执行了一项任务。该任务对于企业环境而言是典型的,会产生大量垃圾。第一个问题是根据我的个人经验和观点回答的,第二个是通过具体测量得出的。
任务:处理数据库
我选择的任务是模拟典型的以数据库为中心的任务,计算所有员工的平均收入。每个员工都被加载到内存中,并且平均值会循环计算。我知道您绝对不应在现实生活中这样做,因为数据库可以自己更快地完成此任务。但是,首先,我看到这种情况在现实生活中经常发生,其次,对于某些NoSQL数据库,您必须在应用程序中执行此操作,其次,这只是一些代码,用于创建大量需要收集的垃圾。
我选择了JVM上的Kotlin作为基于垃圾收集的编程语言的代表。JVM具有高度优化的垃圾收集器,如果您习惯Kotlin,则使用Java就像在石器时代工作一样。
您可以在GitHub上找到代码:https://github.com/akquinet/GcRustVsJvm
用Kotlin处理
计算得出一系列员工,总结他们的薪水,计算员工数量,最后除以这些数字:
- fun computeAverageIncomeOfAllEmployees(
- employees : Sequence<Employee>
- ) : Double
- {
- val (nrOfEmployees, sumOfSalaries) = employees
- .fold(Pair(0L, 0L),
- { (counter, sum), employee ->
- Pair(counter + 1, sum + employee.salary)
- })
- return sumOfSalaries.toDouble() /
- nrOfEmployees.toDouble()
- }
这里没什么令人兴奋的。(您可能会注意到一种函数式编程风格。这是因为我非常喜欢函数式编程。但这不是本文的主题。)垃圾是在创建雇员时创建的。我在这里创建随机雇员,以避免使用真实的数据库。但是,如果您使用JPA,则将具有相同数量的对象创建。
- fun lookupAllEmployees(
- numberOfAllEmployees : Long
- ): Sequence<Employee>
- {
- return (1L..numberOfAllEmployees)
- .asSequence()
- .map { createRandomEmployee() }
- }
随机对象的创建也非常简单。字符串是从字符列表创建的charPool。
- fun createRandomEmployee(): Employee =
- Employee(
- createRandomStringOf80Chars(),
- createRandomStringOf80Chars(),
- ... // code cut Out
- )
- fun createRandomStringOf80Chars() =
- (1..80)
- .map { nextInt(0, charPool.size) }
- .map(charPool::get)
- .joinToString("")
Rust版本的一个小惊喜是我必须如何处理前面提到的字符列表。因为只需要一个单例,所以将其存储在一个伴随对象中。这里是它的轮廓:
- class EmployeeServices {
- companion object {
- private val charPool: List<Char>
- = ('a'..'z') + ('A'..'Z') + ('0'..'9')
- fun lookupAllEmployees(...) ...
- fun createRandomEmployee(): Employee ...
- fun computeAverageIncomeOfAllEmployees(...) ...
- }
- }
现在,以Rust方式处理
我偶然发现的第一件事是,将这个单例字符列表放在何处。Rust支持直接嵌入二进制文件中的静态数据和可以由编译器内联的常量数据。两种选择仅支持一小部分表达式来计算单例的值。我计算允许的字符池的解决方案是这样的:
- let char_pool = ('a'..'z').collect::>();
由于向量的计算基于类型推断,因此无法将其指定为常量或静态。我目前的理解是,Rust的惯用方法是添加功能需要处理的所有对象作为参数。因此,用于计算Rust中平均工资的主要调用如下所示:
- let average =
- compute_average_income_of_all_employees(
- lookup_all_employees(
- nr_of_employees, &char_pool,
- ) );
通过这种方法,所有依赖项都变得清晰了。具有C经验的开发人员会立即认识到地址运算符&,该运算符将内存地址作为指针返回,并且是高效且可能无法维护的代码的基础。当我的许多同事与Rust一起玩时,这种基于C的负面体验被投射到Rust。
我认为这是不公平的。C的&运算符设计带来的问题是,始终存在不可预测的副作用,因为应用程序的每个部分都可以存储指向存储块的指针。另外,每个部分都可以释放内存,从而可能导致所有其他部分引发异常。
在Rust中,&操作员的工作方式有所不同。每个数据始终由一个变量拥有。如果使用&此所有权创建了对数据的引用,则该所有权将转移到引用范围内。只有所有者可以访问数据。如果所有者超出范围,则可以释放数据。
在我们的示例中,char_pool使用&运算符将的所有权转移到函数的参数。当该函数返回时,所有权将归还给变量char_pool。因此,它是一种类似于C的地址运算符,但它增加了所有权的概念,从而使代码更简洁。
Rust中的域逻辑
Rust的主要功能看起来与Kotlin差不多。由于隐含的数字类型,例如f6464位浮点数,因此感觉有点基本。但是,这是您很快就会习惯的事情。
- fn compute_average_income_of_all_employees(
- employees: impl Iterator<Item=Employee>
- ) -> f64
- {
- let (num_of_employees, sum_of_salaries) =
- employees.fold(
- (0u64, 0u64),
- |(counter, sum), employee| {
- return (counter + 1,
- sum + employee.salary);
- });
- return (sum_of_salaries as f64) /
- (num_of_employees as f64);
- }
恕我直言,这是一个很好的例子,可以证明Rust是一种非常现代的干净编程语言,并且对函数式编程风格提供了很好的支持。
在Rust中创建垃圾
现在让我们看一下程序的一部分,其中创建了许多对象,以后需要收集这些对象:
- fn lookup_all_employees<'a>(
- number_of_all_employees: u64,
- char_pool: &'a Vec<char>
- ) -> impl Iterator<Item=Employee> + 'a
- {
- return
- (0..number_of_all_employees)
- .map(move | _ | {
- return create_random_employee(char_pool);
- })
- .into_iter();
- }
乍一看,这看起来很像Kotlin。它使用相同的功能样式在循环中创建随机雇员。返回类型是Iterator,类似于Kotlin中的序列,它是一个延迟计算的列表。
从第二个角度看,这些类型看起来很奇怪。这到底是'a什么?解决了懒惰评估的问题。由于Rust编译器无法知道何时实际评估返回值,并且返回值取决于借入的引用,因此现在存在确定何时char_pool可以释放借入值的问题。的'a注释指定的寿命char_pool必须至少只要是作为返回值的寿命。
对于习惯了经典垃圾回收的开发人员来说,这是一个新概念。在Rust中,她有时必须明确指定对象的生存期。垃圾收集器进行所有清理时不需要的东西。
第三,您可以发现move关键字。它强制闭包获取其使用的所有变量的所有权。由于char_pool(再次),这是必要的。Map是延迟执行的,因此,从编译器的角度来看,闭包可能会超出变量的寿命char_pool。因此,关闭必须拥有它的所有权。
其余代码非常简单。这些结构是根据随机创建的字符串创建的:
- fn create_random_employee(
- char_pool: &Vec<char>
- ) -> Employee
- {
- return Employee {
- first_name:
- create_random_string_of_80_chars(char_pool),
- last_name:
- create_random_string_of_80_chars(char_pool),
- address: Address
- { // cut out .. },
- salary: 1000,
- };
- }
- fn create_random_string_of_80_chars(
- char_pool: &Vec<char>
- ) -> String
- {
- return (0..80)
- .map(|_| {
- char_pool[
- rand::thread_rng()
- .gen_range(0,
- char_pool.len())]
- })
- .into_iter().collect();
- }
那么,Rust有多难?
实施这个微小的测试程序非常复杂。Rust是一种现代的编程语言,使开发人员能够快速干净地维护代码。但是,它的内存管理概念直接体现在语言的所有元素中,这是开发人员必须理解的。
工具支持很好,恕我直言。大多数时候,您只需要执行编译器告诉您的操作即可。但是有时您必须实际决定要如何处理数据。
现在,值得吗?
即使听起来有些令人信服,但我还是非常乐于做一些测量,看看现实是否也令人信服。因此,我为四个不同的输入大小运行了Rust和Kotlin应用程序,测量了时间,并将结果放在对数比例图中:
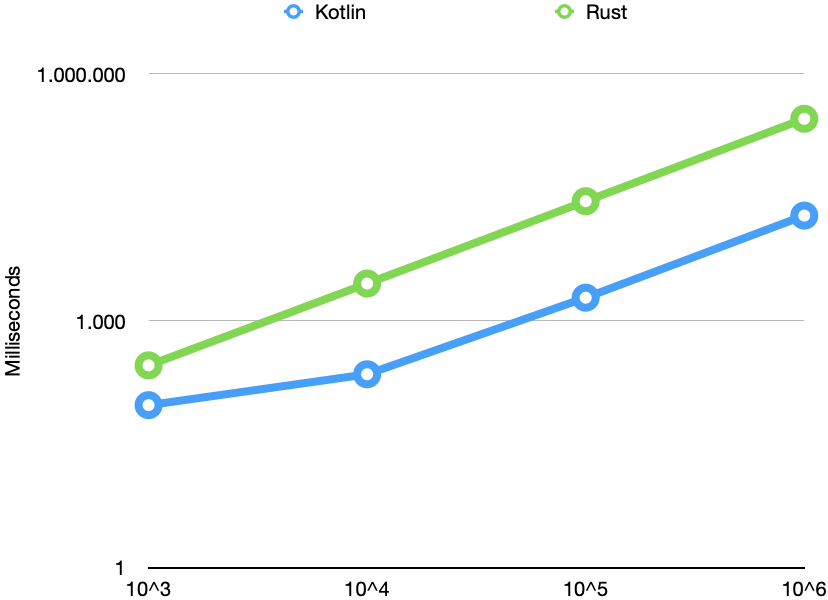
看着这些数字,我长了很长的脸。锈总是较慢;对于10 ^ 6个元素,一个非常糟糕的因子是11。这不可能。我检查了代码,没有发现错误。然后,我检查了优化情况,并发现了--release从dev模式切换到的标志prod。现在,结果看起来好多了:
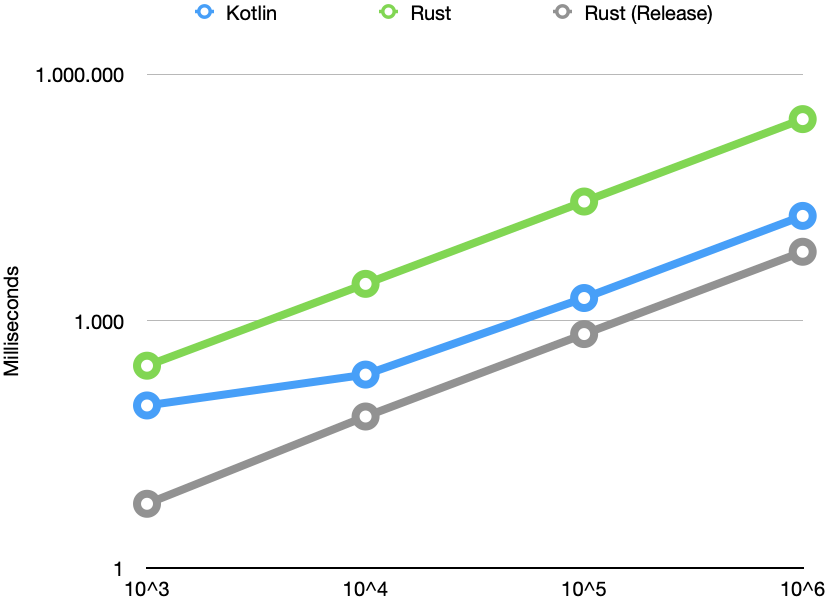
这样好多了。现在,Rust总是比Kotlin快,并提供线性性能。在Kotlin上,我们看到了较长时间运行的代码的典型性能改进,这可能是由于及时编译引起的。从10 ^ 4的输入大小来看,Rust大约比Kotlin快3倍。考虑到JVM的成熟以及过去几十年在基础架构上投入的资源,这是非常令人印象深刻的(Java的第一版于1995年发布)。
对于我来说,令人惊讶的是与生产配置文件相比,开发配置文件的速度要慢得多。40的系数是如此之大,以至于您永远都不应将开发配置文件用于发行。
结论
Rust是一种现代编程语言,具有您如今已习惯的所有舒适性。它具有一种新的内存处理方法,这给开发人员带来了一点额外负担,同时还提供了出色的性能。
而且,要回答标题的最初问题,您不必手动处理Rust中的垃圾。此垃圾收集由运行时系统完成,但现在不再称为垃圾收集器。