对于数据恢复来说,现在其实缺少一些有效的使用场景来更好的体现业务价值,于是我们就重新考虑了下现有的备份支持能力。
备份体系的支持能力
|
粒度 |
备份类型 |
备份模式 |
|
实例 |
全量备份 |
物理备份 |
|
实例 |
增量备份 |
物理备份 |
|
实例 |
日志备份 |
独立服务 |
|
数据库 |
对象备份 |
物理备份 |
其实对象层面的数据恢复能力是很重要的,而且对于业务侧有很多种使用方式。整体的数据恢复流程如下:
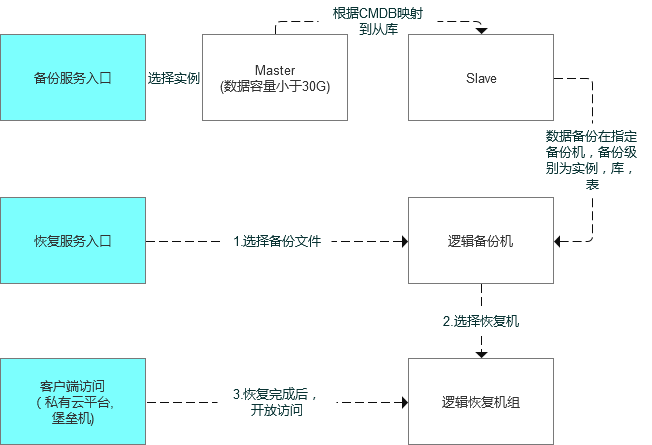
如何规划和设计逻辑备份恢复体系,经过部分讨论,我做了如下的初版设计。
1.数据备份
其中逻辑备份恢复主要面向两个维度:
实例级别:实现表结构,表结构+数据 备份
库/表级别:实现表结构,表结构+数据 备份
目前的逻辑备份恢复的支持范围:
1)数据库主从拓扑关系的实例,逻辑备份操作根据拓扑关系需要在相应的从库端执行
2)单实例节点,逻辑备份操作在单实例节点执行,需要评估备份容量和负载等信息
目前不支持基于中间件MyCAT的节点
对于输入为域名或者Master IP的信息,需要通过拓扑关系转化为相应的从库或者单实例的IP信息
对于库表文件的备份,可以设定如下的规则:
1)单表数据量小于5000万或者表容量在10G以内的表,可以支持逻辑备份,此外需要相应的提示,尽可能避免此类操作
2)选择备份的数据库容量在30G以内,此外需要相应的提示避免此类操作
需要后端提供相应的库,表 存储容量/数据量相关的元数据信息(估算容量即可,不需要精确值),目前可以通过生命周期管理中的数据库基线和数据表基线元数据支持
对于备份时长的评估,目前可以提供如下的递增区间:
1)备份容量在500M以内,显示预计完成时间在5分钟以内
2)备份容量在2G以内,显示完成时间在10分钟以内
3)备份容量在10G以内,显示完成时间在20分钟以内
4)备份容量在30G以内,显示完成时间在30分钟以内
在备份完成后,可以提供相应的即时通讯提示告知业务侧备份操作已完成
备份生成的文件需要在指定的备份机存储,按照如下的目录规则进行存放
备份机BASE目录:/data/logical_backup/
备份机中实例的备份目录:
- [Slave_IP]_[port]/[YYYYmmdd]/
相应的备份文件命名规则:
- [Slave_IP]_[port]_[db_name]_[YYYYmmdd]_[hhmiss]_[username].sql
数据备份后需要生成相应的配置文件,数据格式为JSON,在数据恢复时可以进行相应数据格式的解析和显示。
备份文件的保留周期目前暂定为7天,需要在备份时有相应的提示。
2.数据恢复
数据恢复是业务自助发起,而且相关的数据恢复资源具有使用时限,目前暂定为2天,2天后相应的数据和权限会进行相应的回收,会有相应的资源回收提示,同时需要在使用中进行相关提示。
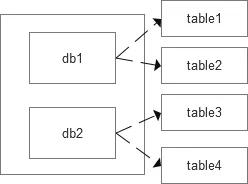
数据恢复粒度基于备份数据文件中指定的对象(数据库,表)粒度,如业务同学A备份了表db1.table1,db1.table2,则不能仅恢复db1.table1,恢复工作会直接恢复db1.table1,db1.table2
数据恢复文件的选择需要考虑相关的权限,如业务同学A备份了表db1.table1,db1.table2,业务同学B备份了表db2.table3,db2.table4,则在选择备份文件中,应该彼此不可见。
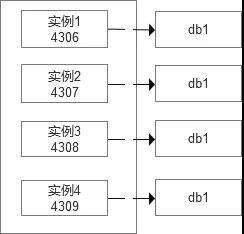
如果对于同一个数据库需要进行多次数据恢复,则可以根据服务器的资源配比进行动态的调配,比如一个数据恢复服务器中有4个实例,端口分别是4306-4309,业务同学在使用中可以相应的恢复4次,在实际使用中需要根据使用的频率和情况进行资源的扩展,后续应该为一个数据恢复服务器组
在数据恢复中,需要恢复到哪一个实例,由后端提供相应的调度逻辑进分配
对于数据恢复后的使用,可以提供一体化服务,由业务侧使用客户端工具如workbench进行连接和使用,权限开通的部分,需要根据用户的域名信息得到办公机的IP地址,进行相关数据库权限的开通,开通后有对应的即时通讯提示。
数据库层的权限开通,如果数据库用户已经存在,则进行相应的权限补充,如果数据库用户不存在,则需要在指定的实例中创建用户,并分配相应的权限
整个备份数据的使用,需要考虑到便利性和安全性,可以和安全部进行对接,进行部分工作的评估和考量。
备份和恢复的相关操作和历史记录,需要统一存储和管理
对于数据恢复的相关日志,为了便于后续管理和跟踪,需要在恢复记录中记录备份文件的路径
本文转载自微信公众号「杨建荣的学习笔记」,可以通过以下二维码关注。转载本文请联系杨建荣的学习笔记公众号。