













事实上,Python 多线程另一个很重要的话题叫,GIL(Global Interpreter Lock,即全局解释器锁)。
多线程不一定比单线程快
在Python中,可以通过多进程、多线程和多协程来实现多任务。难道多线程就一定比单线程快?
下面我用一段代码证明我自己得观点。
'''
@Author:Runsen
@微信公众号:Python之王
@博客:https://blog.csdn.net/weixin_44510615
@Date:2020/6/4
'''
import threading, time
def my_counter():
i = 0
for _ in range(100000000):
i = i+1
return True
def main1():
start_time = time.time()
for tid in range(2):
t = threading.Thread(target=my_counter)
t.start()
t.join() # 第一次循环的时候join方法引起主线程阻塞,但第二个线程并没有启动,所以两个线程是顺序执行的
print("单线程顺序执行total_time: {}".format(time.time() - start_time))
def main2():
thread_ary = {}
start_time = time.time()
for tid in range(2):
t = threading.Thread(target=my_counter)
t.start()
thread_ary[tid] = t
for i in range(2):
thread_ary[i].join() # 两个线程均已启动,所以两个线程是并发的
print("多线程执行total_time: {}".format(time.time() - start_time))
if __name__ == "__main__":
main1()
main2()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
运行结果
单线程顺序执行total_time: 17.754502773284912
多线程执行total_time: 20.01178550720215
- 1.
- 2.
我怕你说我乱得出来得结果,我还是截个图看清楚点

这时,我怀疑:我的机器出问题了吗?其实不是这样,本质上来说Python 的线程失效了,没有起到并行计算的作用。
Python 的线程,的确封装了底层的操作系统线程,在 Linux 系统里是 Pthread(全称为 POSIX Thread),而在 Windows 系统里是 Windows Thread。另外,Python 的线程,也完全受操作系统管理,比如协调何时执行、管理内存资源、管理中断等等。
GIL不是Python的特性
GIL 的概念用简单的一句话来解释,就是「任一时刻,无论线程多少,单一 CPython 解释器只能执行一条字节码」。这个定义需要注意的点:
首先需要明确的一点是「GIL并不是Python的特性」,它是在实现Python解析器(CPython)时所引入的一个概念。
C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。
Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。
「其他 Python 解释器不一定有 GIL」。例如 Jython (JVM) 和 IronPython (CLR) 没有 GIL,而 CPython,PyPy 有 GIL;
因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:「GIL并不是Python的特性,Python完全可以不依赖于GIL」
GIL本质就是一把互斥锁
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
可以肯定的一点是:保护不同的数据的安全,就应该加不同的锁。
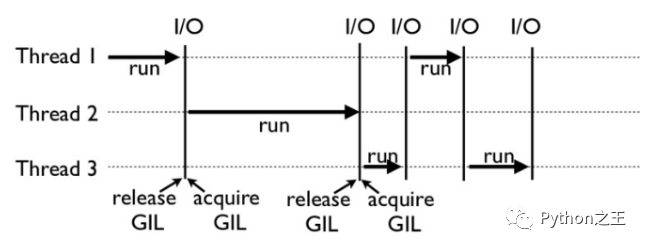
GIL 的工作原理:比如下面这张图,就是一个 GIL 在 Python 程序的工作示例。其中,Thread 1、2、3 轮流执行,每一个线程在开始执行时,都会锁住 GIL,以阻止别的线程执行;同样的,每一个线程执行完一段后,会释放 GIL,以允许别的线程开始利用资源。
计算密集型
计算密集型任务的特点是要进行大量的计算,消耗CPU资源
我们先来看一个简单的计算密集型示例:
'''
@Author:Runsen
@微信公众号:Python之王
@博客:https://blog.csdn.net/weixin_44510615
@Date:2020/6/4
'''
import time
COUNT = 50_000_000
def count_down():
global COUNT
while COUNT > 0:
COUNT -= 1
s = time.perf_counter()
count_down()
c = time.perf_counter() - s
print('time taken in seconds - >:', c)
time taken in seconds - >: 9.2957003
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
这个是单线程, 时间是9s, 下面我们用两个线程看看结果又如何:
'''
@Author:Runsen
@微信公众号:Python之王
@博客:https://blog.csdn.net/weixin_44510615
@Date:2020/6/4
'''
import time
from threading import Thread
COUNT = 50_000_000
def count_down():
global COUNT
while COUNT > 0:
COUNT -= 1
s = time.perf_counter()
t1 = Thread(target=count_down)
t2 = Thread(target=count_down)
t1.start()
t2.start()
t1.join()
t2.join()
c = time.perf_counter() - s
print('time taken in seconds - >:', c)
time taken in seconds - >: 17.110625
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
我们程序主要的操作就是在计算, CPU没有等待, 而改为多线程后, 增加了线程后, 在线程之间频繁的切换,增大了时间开销, 时间当然会增加了。
还有一种类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
「总结:对于io密集型工作(Python爬虫),多线程可以大幅提高代码效率。对CPU计算密集型(Python数据分析,机器学习,深度学习),多线程的效率可能比单线程还略低。所以,数据领域没有多线程提高效率之说,只有将CPU提升到GPU,TPU来提升计算能力。」





















