1. 简介
我们在利用pandas开展数据分析时,应尽量避免过于「碎片化」的组织代码,尤其是创建出过多不必要的「中间变量」,既浪费了「内存」,又带来了关于变量命名的麻烦,更不利于整体分析过程代码的可读性,因此以流水线方式组织代码非常有必要。
图1
而在以前我撰写的一些文章中,为大家介绍过pandas中的eval()和query()这两个帮助我们链式书写代码,搭建数据分析工作流的实用API,再加上下面要介绍的pipe(),我们就可以将任意pandas代码完美组织成流水线形式。
2. 在pandas中灵活利用pipe()pipe()
顾名思义,就是专门用于对Series和DataFrame操作进行流水线(pipeline)改造的API,其作用是将嵌套的函数调用过程改造为「链式」过程,其第一个参数func传入作用于对应Series或DataFrame的函数。
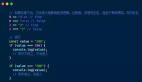
具体来说pipe()有两种使用方式,「第一种方式」下,传入函数对应的第一个位置上的参数必须是目标Series或DataFrame,其他相关的参数使用常规的「键值对」方式传入即可,就像下面的例子一样,我们自编函数对「泰坦尼克数据集」进行一些基础的特征工程处理:
import pandas as pd
train = pd.read_csv('train.csv')
def do_something(data, dummy_columns):
'''
自编示例函数
'''
data = (
pd
# 对指定列生成哑变量
.get_dummies(data, # 先删除data中指定列
columns=dummy_columns,
drop_first=True)
)
return data
# 链式流水线
(
train
# 将Pclass列转换为字符型以便之后的哑变量处理
.eval('PclassPclass=Pclass.astype("str")', engine='python')
# 删除指定列
.drop(columns=['PassengerId', 'Name', 'Cabin', 'Ticket'])
# 利用pipe以链式的方式调用自编函数
.pipe(do_something,
dummy_columns=['Pclass', 'Sex', 'Embarked'])
# 删除含有缺失值的行
.dropna()
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
可以看到,在紧接着drop()下一步的pipe()中,我们将自编函数作为其第一个参数传入,从而将一系列操作巧妙地嵌入到链式过程中。
「第二种使用方式」适合目标Series和DataFrame不为传入函数第一个参数的情况,譬如下面的例子中我们假设目标输入数据为第二个参数data2,则pipe()的第一个参数应以(函数名, '参数名称')的格式传入:
def do_something(data1, data2, axis):
'''
自编示例函数
'''
data = (
pd
.concat([data1, data2], axisaxis=axis)
)
return data
# pipe()第二种使用方式
(
train
.pipe((do_something, 'data2'), data1=train, axis=0)
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
在这样的设计下我们可以避免很多函数嵌套调用方式,随心所欲地优化我们的代码~