












如您本文转载自公众号“读芯术”(ID:AI_Discovery)。
如您所知,数据科学和机器学习必须提供无穷无尽的信息和知识。 话虽如此,大多数公司都只测试少数核心思想。 这是因为这十个概念是更复杂的思想和概念的基础。
话虽如此,我们开始吧!
1. 有监督与无监督学习
您可能想知道为什么我什至不愿意将其放入,因为它是如此的基础。 但是,我认为重要的是,您必须真正了解两者之间的差异并能够传达差异:
监督学习涉及在已知目标变量的标记数据集上学习。
无监督学习用于从输入数据中得出推论和查找模式,而无需引用标记结果—没有目标变量。
既然您知道了两者之间的区别,那么您应该知道机器学习模型是有监督的还是无监督的,并且还应该知道给定的场景是需要监督学习算法还是无监督学习算法。
例如,如果我想预测客户是否已经购买了谷物,那么他们是否需要购买牛奶,这是否需要有监督或无监督的学习算法?
2. 偏差-偏差权衡
为了了解偏差-方差的权衡,您需要知道什么是偏差和方差。
偏差是由于模型的简化假设而导致的错误。 例如,使用简单的线性回归对病毒的指数增长进行建模将导致较高的偏差。
方差是指如果使用不同的训练数据,则预测值将更改的量。 换句话说,更加重视训练数据的模型将具有更大的方差。
现在,偏差方差折衷实质上表明在给定的机器学习模型中偏差量和方差之间存在反比关系。 这意味着,当您减少模型的偏差时,方差会增加,反之亦然。 但是,有一个最佳点,其中特定数量的偏差和方差导致总误差最小(请参见下文)。
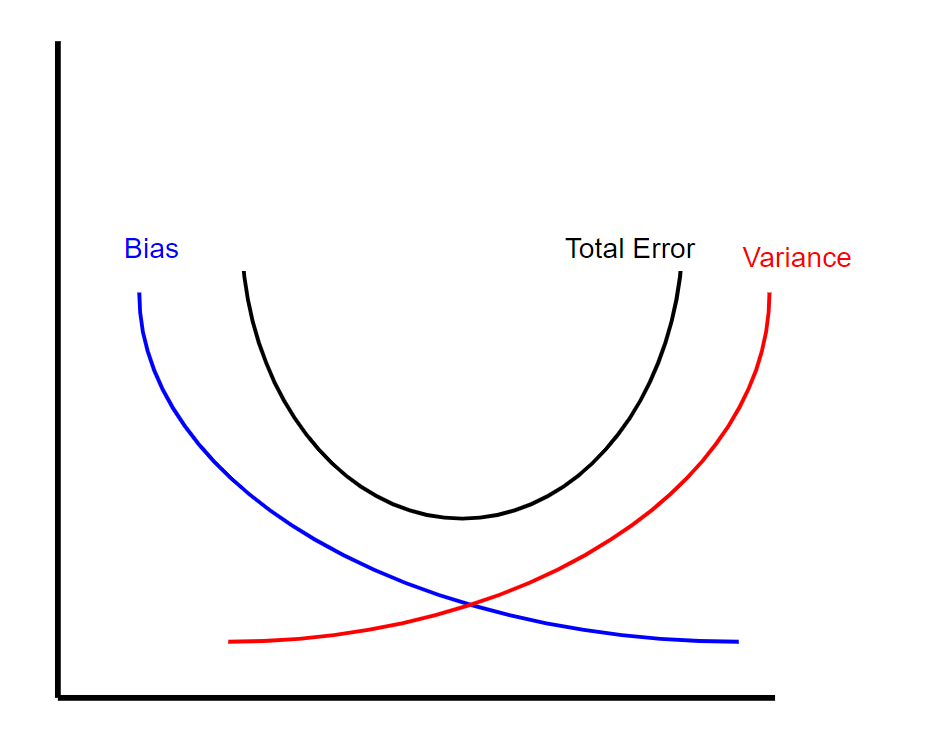
> Visual of bias variance tradeoff (created by author)
3. 正则化
最常见的正则化方法类型称为L1和L2。 L1和L2正则化都是用于减少训练数据过度拟合的方法。
L2正则化(也称为脊回归)可将残差平方加λ乘以斜率平方的总和最小化。 这个附加术语称为"岭回归罚分"。 这会增加模型的偏差,使训练数据的拟合度变差,但也会减少方差。
如果采用岭回归罚分并将其替换为斜率的绝对值,则将获得套索回归或L1正则化。
L2不那么健壮,但具有稳定的解决方案,并且始终是一个解决方案。 L1更健壮,但解决方案不稳定,可能有多个解决方案。
4. 交叉验证
交叉验证本质上是一种用于评估模型在新的独立数据集上的性能的技术。
交叉验证的最简单示例是将数据分为三类:训练数据,验证数据和测试数据,其中使用训练数据构建模型,验证数据调整超参数以及测试数据 评估您的最终模型。
这引出了下一点-机器学习模型的评估指标。
5. 评估指标
您可以选择多种度量来评估您的机器学习模型,最终选择哪种度量取决于问题的类型和模型的目标。
如果您正在评估回归模型,那么重要的指标包括:
- R平方:一种度量,它告诉您因变量的方差比例在多大程度上由自变量的方差解释。 用简单的话来说,虽然系数估计趋势,但R平方代表最佳拟合线周围的分散。
- 调整后的R平方:添加到模型中的每个其他自变量始终会增加R²值-因此,具有多个自变量的模型似乎更适合,即使不是。 因此,调整后的R 2补偿了每个附加的自变量,并且仅在每个给定变量使模型的改进超出概率范围时才增加。
- 平均绝对误差(MAE):绝对误差是预测值和实际值之间的差。 因此,平均绝对误差是绝对误差的平均值。
- 均方误差(MSE):均方误差或MSE与MAE相似,不同之处在于,您对预测值和实际值之间的平方差取平均值。
分类模型的指标包括:
- 真阴性:模型正确预测负面类别的结果。
- 误报(类型1错误):模型错误地预测正类的结果。
- 假阴性(类型2错误):模型错误地预测阴性类别的结果。
- 准确性:等于模型正确的预测分数。
- 回想一下:尝试回答"正确识别了实际阳性的比例是多少?"
- 精确度:尝试回答"阳性识别的正确比例是多少?"
- F1分数:衡量测试准确性的指标,它是准确性和召回率的谐和平均值。 它的最高分数为1(完美的准确性和查全率),最低分数为0。总体而言,它是模型准确性和健壮性的度量。
- AUC-ROC曲线是对分类问题的一种性能度量,它告诉我们模型能够区分多个类别。 较高的AUC表示模型更准确。
6. 降维
降维是减少数据集中要素数量的过程。 这一点很重要,主要是在您要减少模型中的方差(过度拟合)的情况下。
最流行的降维技术之一是主成分分析或PCA。 从最简单的意义上讲,PCA涉及将较高维度的数据(例如3个维度)投影到较小的空间(例如2个维度)。 这样会导致数据维度较低(2维而不是3维),同时将所有原始变量保留在模型中。
PCA通常用于压缩目的,以减少所需的内存并加快算法的速度,还用于可视化目的,从而使汇总数据更加容易。
7. 数据准备
数据准备是清除原始数据并将其转换为更可用状态的过程。 在采访中,可能会要求您列出整理数据集时要采取的一些步骤。
数据准备中一些最常见的步骤包括:
- 检查异常值并可能将其删除
- 估算缺失数据
- 编码分类数据
- 标准化或标准化您的数据
- 特征工程
- 通过对数据进行欠采样或过采样来处理数据不平衡
8. 自举采样
Bootstrap采样方法是一个非常简单的概念,并且是一些更高级的机器学习算法(例如AdaBoost和XGBoost)的构建块。
从技术上讲,自举采样方法是一种重采样方法,它使用随机采样进行替换。
别担心这听起来令人困惑,让我用一个图表来解释一下:
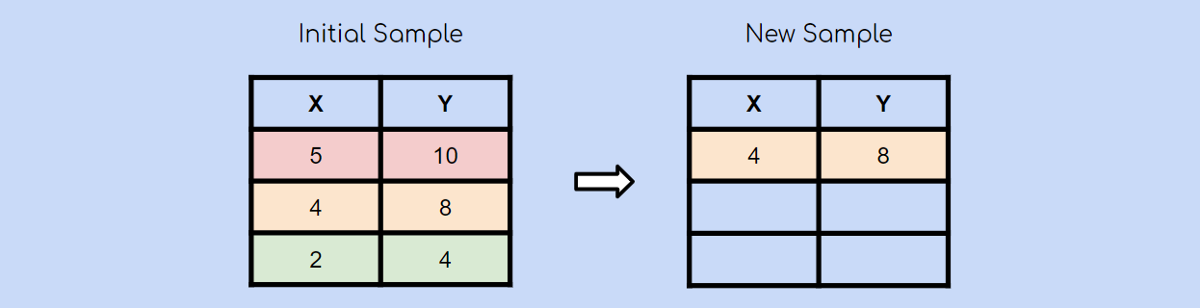
假设您有一个包含3个观测值的初始样本。 使用自举抽样方法,您还将创建一个包含3个观测值的新样本。 每个观察都有被选择的平等机会(1/3)。 在这种情况下,第二个观察值是随机选择的,它将是我们新样本中的第一个观察值。
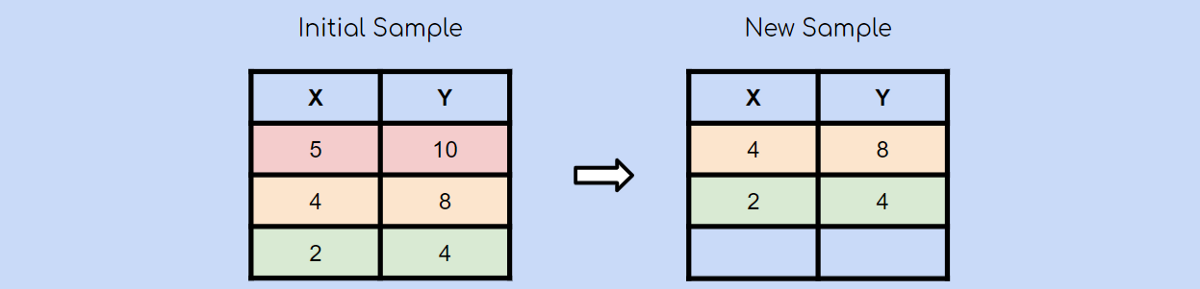
随机选择另一个观察值后,您选择了绿色观察值。
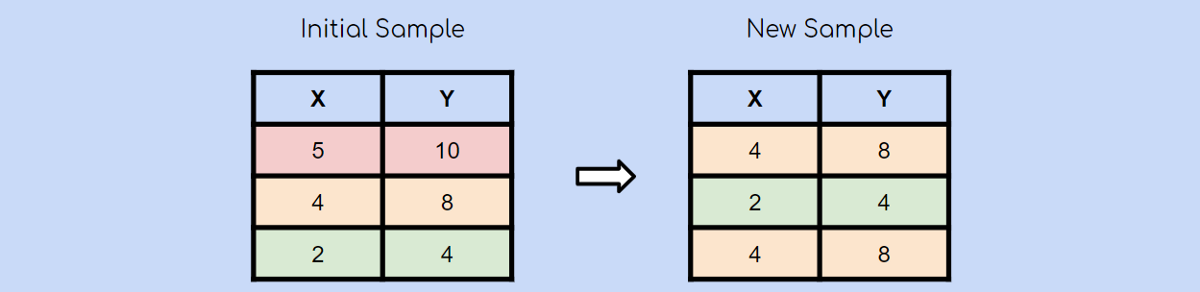
最后,再次随机选择黄色观察值。 请记住,引导抽样是使用随机抽样和替换抽样。 这意味着很有可能再次选择已经选择的观测值。
这就是自举采样的精髓!
9. 神经网络
尽管并不是每个数据科学工作都需要深度学习,但无疑需求在不断增长。 因此,对神经网络是什么以及它们如何工作有一个基本的了解可能是一个好主意。
从根本上说,神经网络本质上是数学方程式的网络。 它采用一个或多个输入变量,并通过方程式网络得出一个或多个输出变量。
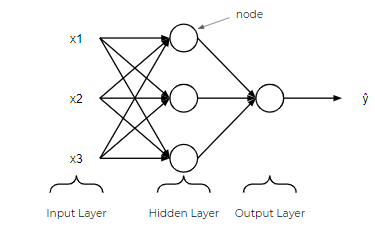
在神经网络中,有一个输入层,一个或多个隐藏层和一个输出层。 输入层由一个或多个表示为x1,x2,…,xn的特征变量(或输入变量或自变量)组成。 隐藏层由一个或多个隐藏节点或隐藏单元组成。 节点只是上图中的圆圈之一。 同样,输出变量由一个或多个输出单元组成。
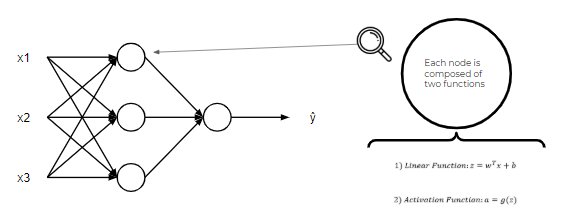
就像我在开始时说的那样,神经网络不过是方程网络。 神经网络中的每个节点都由两个函数组成,一个线性函数和一个激活函数。 在这里,事情可能会有些混乱,但是现在,将线性函数视为最合适的直线。 另外,将激活功能想像成一个电灯开关,它会导致数字介于1或0之间。
10. 集成学习,Bagging,Boosting
某些最佳的机器学习算法结合了这些术语,因此,您必须了解什么是集成学习,装袋和增强。
集成学习是一种结合使用多种学习算法的方法。 这样做的目的是,与单独使用单个算法相比,它可以实现更高的预测性能。
套袋,也称为引导程序聚合,是一个过程,其中使用原始数据集的自举样本来训练同一学习算法的多个模型。 然后,就像上面的随机森林示例一样,对所有模型的输出进行表决。
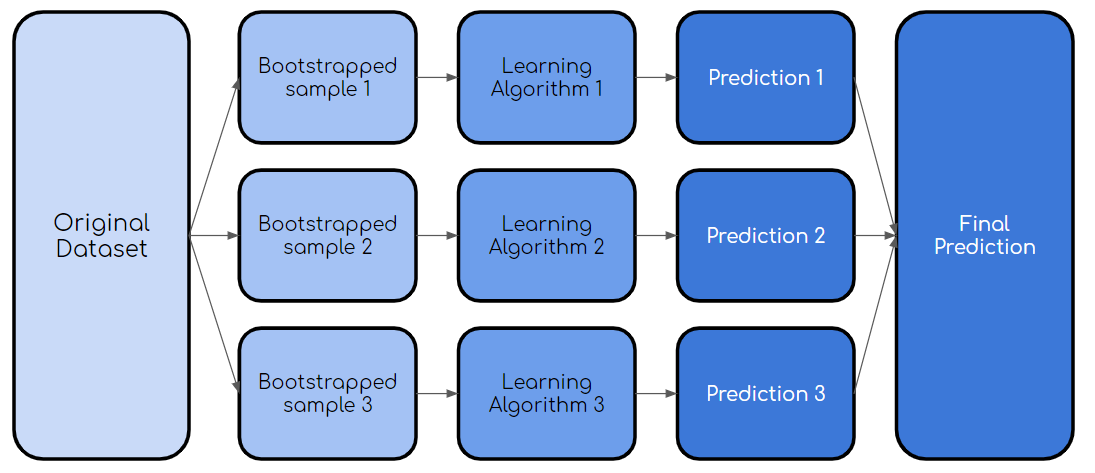
> Bagging Process (created by author)
Boosting是套袋的一种变体,其中每个单独的模型都按顺序构建,并在前一个模型上进行迭代。 具体而言,在以下模型中强调由先前模型错误分类的任何数据点。 这样做是为了提高模型的整体准确性。 这是一个使过程更有意义的图:
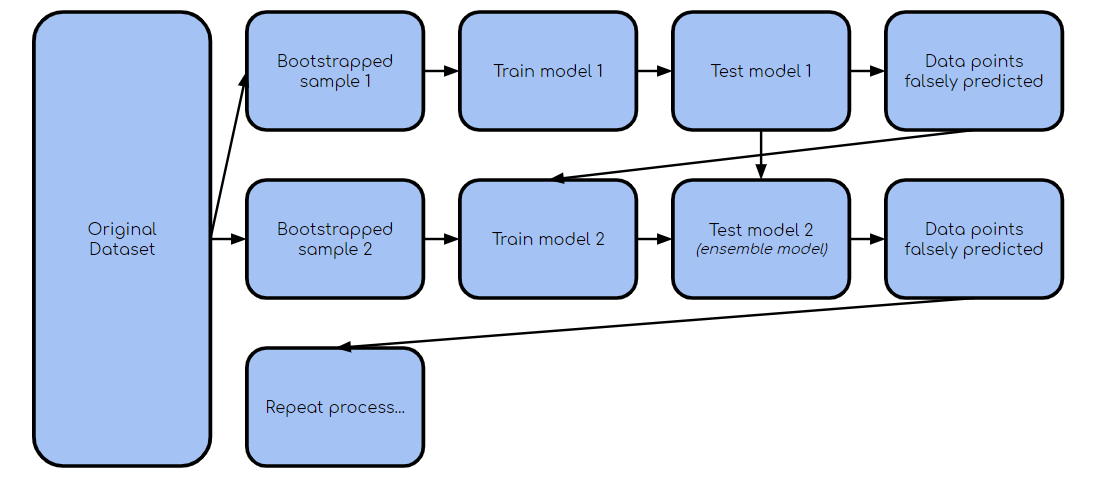
> boosting process (created by author)
一旦建立了第一个模型,除第二个自举样本外,还要获取错误分类/预测的点,以训练第二个模型。 然后,针对测试数据集使用集成模型(模型1和2),然后继续该过程。




















