【51CTO.com快译】集成学习是功能强大的机器学习技术之一。集成学习通过使用多种机器学习模型来提高预测结果的可靠性和准确性。但是,使用多种机器学习模型如何使预测结果更准确?可以采用什么样的技术创建整体学习模型?以下将探讨解答这些问题,并研究使用集成模型的基本原理以及创建集成模型的主要方法。
什么是集成学习?
简而言之,集成学习是训练多个机器学习模型并将其输出组合在一起的过程。组织以不同的模型为基础,致力构建一个最优的预测模型。组合各种不同的机器学习模型可以提高整体模型的稳定性,从而获得更准确的预测结果。集成学习模型通常比单个模型更可靠,因此,它们经常在许多机器学习竞赛中获胜。
工程师可以使用多种技术来创建集成学习模型。而简单的集成学习技术包括平均不同模型的输出结果,同时还开发了更复杂的方法和算法,专门用于将许多基础学习者/模型的预测结果组合在一起。
为什么要使用集成训练方法?
出于多种原因,机器学习模型可能会彼此不同。不同的机器学习模型可以对总体数据的不同样本进行操作,可以使用不同的建模技术,并且使用不同的假设。
想象一下,如果你加入由不同专业人员组成的团队,那么肯定会有一些你知道和不知道的技术,假设你正在和其他成员一起讨论一个技术主题。他们也像你一样,只对自己的专业有所了解,而对其他专业技术一无所知。但是,如果最终能将这些技术知识组合在一起,将会对更多领域有更准确的猜测,这是集成学习的原理,也就是结合不同个体模型(团队成员)的预测以提高准确性,并最大程度地减少错误。
统计学家已经证明,当一群人被要求用一系列可能的答案来猜测一个给定问题的正确答案时,他们所有的答案都会形成一个概率分布。真正知道正确答案的人会自信地选择正确的答案,而选择错误答案的人会将他们的猜测分散到可能的错误答案范围内。例如玩一个猜迷游戏,如果你和两个朋友都知道正确的答案是A,那么你们三个人都会选A,而团队中其他三个不知道答案的人很可能会错误地猜测是B、C、D或E,其结果是A有三票,其他答案可能只有一到两票。
所有的模型都有一定的误差。一个模型的误差将不同于另一个模型产生的误差,因为模型本身由于上述原因而不同。当检查所有的错误时,它们不会聚集在某一个答案周围,而是广泛分布。不正确的猜测基本上分散在所有可能的错误答案上,并相互抵消。与此同时,来自不同模型的正确猜测将聚集在正确的答案周围。当使用集成训练方法时,可以找到更可靠的正确答案。
简单的集成训练方法
简单的集成训练方法通常只涉及统计集成技术的应用,例如确定一组预测的模式、平均值或加权平均值。
模型是指一组数字中出现频率最高的元素。为了得到这个模型,各个学习模型返回他们的预测,这些预测被认为是对最终预测的投票。通过计算预测的算术平均值(四舍五入到最接近的整数)来确定预测的平均值。最后,可以通过为用于创建预测的模型分配不同的权重来计算加权平均值,其中权重代表该模型的预测重要性。将类别预测的数值表示与权重(从0到1.0)相乘,然后将各个加权的预测相加在一起,并将其结果进行四舍五入,从而得出最接近的整数。
高级集成训练方法
现在有三种主要的高级集成训练技术,每种技术都旨在解决特定类型的机器学习问题。 “装袋”(Bagging)技术用于减少模型预测的方差,方差是指当基于相同的观察结果时预测的结果相差多少。使用“提升”(Boosting)技术来消除模型的偏差。最后,通常使用“堆叠”(Stacking)来改善预测结果。
集成学习方法通常可以分为两类:顺序集成方法和并行集成方法。
顺序集成方法的名称为“顺序”,因为基础学习器/模型是顺序生成的。在顺序集成方法的情况下,基本思想是利用基础学习者之间的依赖关系来获得更准确的预测。标签错误的示例将调整其权重,而标签正确的示例将保持相同的权重。在每次生成新的学习者时,权重都会改变,其准确性将会提高。
与顺序集成模型相反,并行集成方法将会并行生成基础学习器。在进行并行集成学习时,可以利用基础学习器具有独立性这一事实,因为可以通过平均每个学习器的预测值来降低总体错误率。
集成训练方法可以是同质的,也可以是异质的。大多数集成学习方法是同质的,这意味着它们使用单一类型的基本学习模型/算法。与其相反,异构集成使用不同的学习算法,使学习者多样化,以确保尽可能高的准确性。
集成学习算法的示例
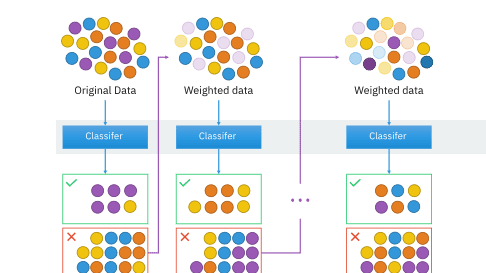
集成提升的可视化
顺序集成方法的示例包括AdaBoost、XGBoost和Gradient tree boosting。这些都是提升升模型。对于这些提升模型,目标是将表现欠佳的弱势学习者转变为功能强大的学习者。像AdaBoost和XGBoost这样的模型从许多弱势学习者开始,这些学习者的表现比随机猜测要好一些。随着训练的继续,将权重应用于数据并进行调整。在较早的培训中被学习者错误分类的实例将具有更大的权重。在为所需的训练回合次数重复此过程之后,通过加权和(对于回归任务)和加权投票(对于分类任务)将预测合并在一起。

装袋学习过程
并行集成模型的一个示例是随机森林分类器,并且随机森林也是装袋技术的一个示例。 “装袋”这个术语来自“引导聚合”。使用称为“自举抽样”的抽样技术从总数据集中抽取样本,基本学习者使用这些技术进行预测。对于分类任务,基本模型的输出使用投票进行聚合,而对于回归任务则将它们进行平均。随机森林使用单独的决策树作为基础学习者,并且集合中的每个决策树都是使用来自数据集的不同样本构建的。特征的随机子集也用于生成决策树。导致高度随机化的个体决策树,这些决策树全部组合在一起以提供可靠的预测。
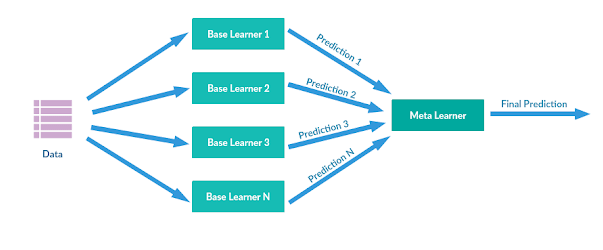
堆叠集成可视化
在堆叠集成技术方面,多元回归或分类模型通过更高级别的元模型组合在一起。较低级别的基本模型通过输入整个数据集进行训练。然后将基本模型的输出作为训练元模型的功能。堆叠集成模型在本质上通常是异质的。
原文章标题:What is Ensemble Learning?,作者:Daniel Nelson
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】