将传统标签传播方法与简单模型相结合即在某些数据集上超过了当前最优 GNN 的性能,这是康奈尔大学与 Facebook 联合提出的一项研究。这种新方法不仅能媲美当前 SOTA GNN 的性能,而且参数量也少得多,运行时更是快了几个数量级。
图神经网络(GNN)是图学习方面的主要技术。但是我们对 GNN 成功的奥秘以及它们对于优秀性能是否必然知之甚少。近日,来自康奈尔大学和 Facebook 的一项研究提出了一种新方法,在很多标准直推式节点分类(transductive node classification)基准上,该方法超过或媲美当前最优 GNN 的性能。
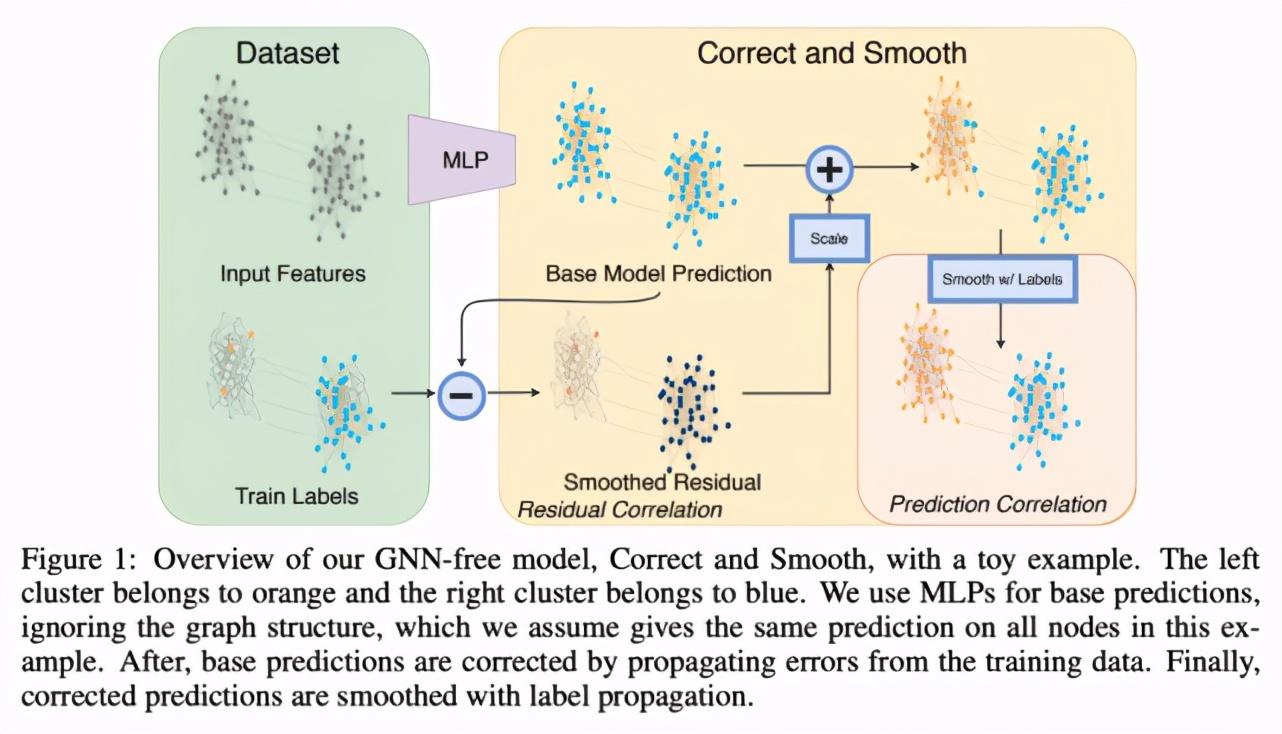
这一方法将忽略图结构的浅层模型与两项简单的后处理步骤相结合,后处理步利用标签结构中的关联性:(i) 「误差关联」:在训练数据中传播残差以纠正测试数据中的误差;(ii) 「预测关联」:平滑测试数据上的预测结果。研究人员将这一步骤称作 Correct and Smooth (C&S),后处理步骤通过对早期基于图的半监督学习方法中的标准标签传播(LP)技术进行简单修正来实现。
该方法在多个基准上超过或接近当前最优 GNN 的性能,而其参数量比后者小得多,运行时也快了几个数量级。例如,该方法在 OGB-Products 的性能超过 SOTA GNN,而其参数量是后者的 1/137,训练时间是后者的 1/100。该方法的性能表明,直接将标签信息纳入学习算法可以轻松实现显著的性能提升。这一方法还可以融入到大型 GNN 模型中。
图神经网络的缺陷
继神经网络在计算机视觉和自然语言处理领域的巨大成功之后,图神经网络被用来进行关系数据的预测。这些模型取得了很大进展,如 Open Graph Benchmark。新型 GNN 架构的许多设计思想是从语言模型(如注意力)或视觉模型(如深度卷积神经网络)中的新架构改编而来。但是,随着这些模型越来越复杂,理解其性能收益成为重要挑战,并且将这些模型扩展到大型数据集的难度有所增加。
新方法:标签信息 + 简单模型
而这篇论文研究了结合更简单的模型能够达到怎样的性能,并重点了解在图学习特别是在直推式节点分类中,有哪些提高性能的机会。
研究者提出了一个简单的 pipeline(参见图 1),它包含 3 个主要部分:
- 基础预测(base prediction),使用忽略图结构(如 MLP 或线性模型)的节点特征完成;
- 校正步骤,这一步将训练数据的不确定性传播到整个图上,以校正基础预测;
- 平滑图预测结果。
步骤 2 和 3 只是后处理步骤,它们使用经典方法进行基于图的半监督学习,即标签传播。
通过对这些经典 idea 进行改进和新的部署,该研究在多个节点分类任务上实现了 SOTA 性能,超过大型 GNN 模型。在该框架中,图结构不用于学习参数,而是用作后处理机制。这种简单性使模型参数和训练时间减少了几个数量级,并且可以轻松扩展到大型图中。此外,该方法还可以与 SOTA GNN 结合,实现一定程度的性能提升。
该方法性能提升的主要来源是直接使用标签进行预测。这并不是一个新想法,但很少用于 GNN。该研究发现,即使是简单的标签传播(忽略特征)也能在许多基准测试中取得出色的效果。这为结合以下两种预测能力来源提供了动力:一个来源于节点特征(忽略图结构),另一个来源于在预测中直接使用已知标签。
具体而言,该方法首先使用一个基于节点特征的基础预测器,它不依赖于任何图学习。然后,执行两种类型的标签传播 (LP):一种通过建模相关误差来校正基础预测;一种用来平滑最终预测。研究人员将这两种方法的结合称作 Correct and Smooth(C&S,参见图 1)。LP 只是后处理步骤,该 pipeline 并非端到端训练。此外,图只在后处理步骤中使用,在前处理步骤中用于增强特征,但不用于基础预测。这使得该方法相比标准 GNN 模型训练更快速,且具备可扩展性。
该研究还利用两种 LP 和节点特征的优势,将这些互补信号结合起来可以获得优秀的预测结果。
实验
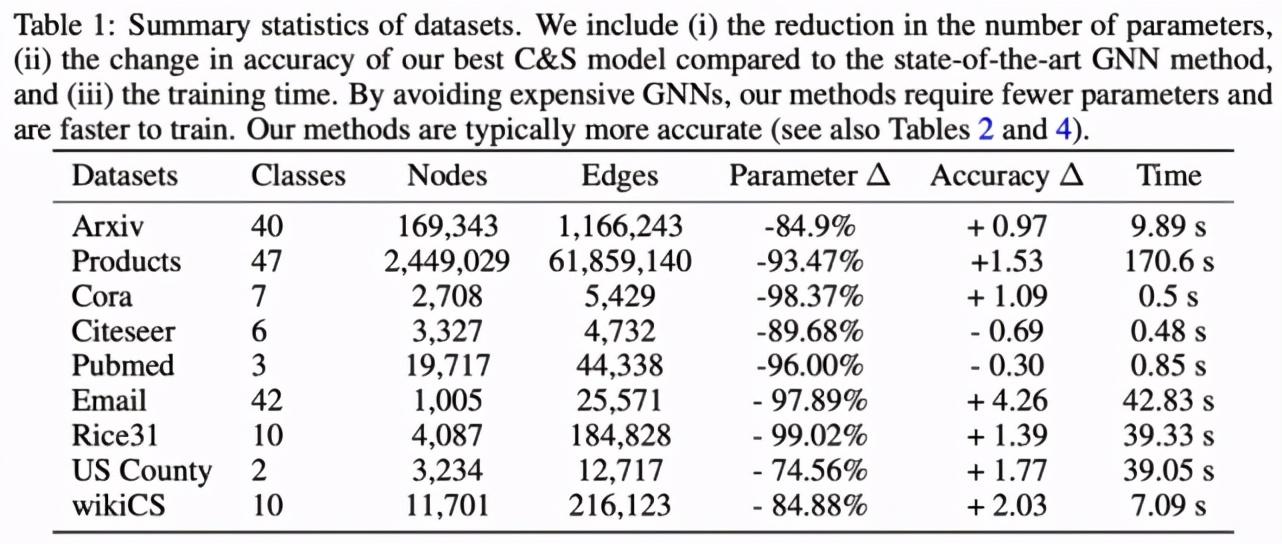
为了验证该方法的有效性,研究者使用了 Arxiv、Products、Cora、Citeseer、Pubmed、Email、Rice31、US County 和 wikiCS 九个数据集。
节点分类的初步结果
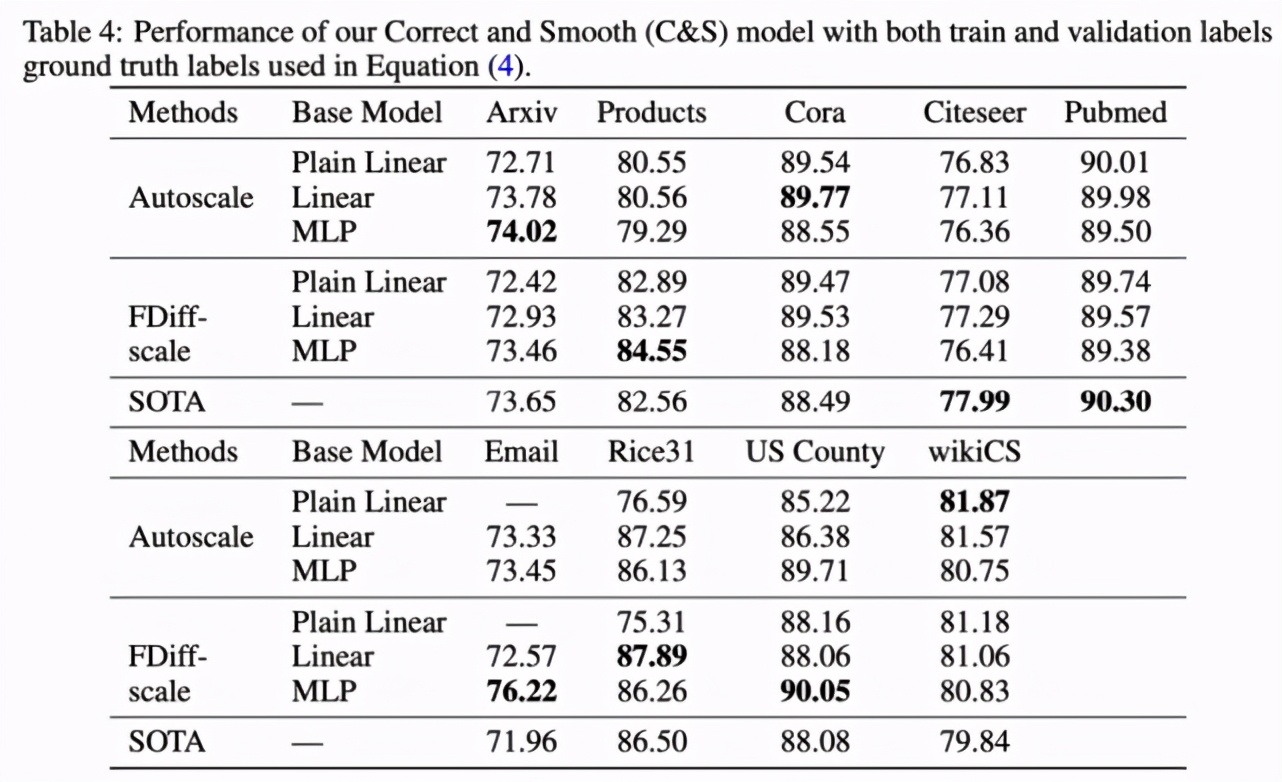
下表 2 给出了相关实验结果,研究者得出了以下几点重要发现。首先,利用本文提出的 C&S 模型,LP 后处理步骤会带来巨大增益(如在 Products 数据集上,MLP 的基础预测准确率由 63% 提升至 84%);其次,具有 C&S 框架的 Plain Linear 模型的性能在很多情况下优于 plain GCN,并且无可学习参数的方法 LP 的性能通常也媲美于 GCN。这些结果表明,通过简单使用特征在图中直接合并关联往往是更好的做法;最后,C&S 模型变体在 Products、Cora、Email、Rice31 和 US County 等 5 个数据集上的性能通常显著优于 SOTA。在其他数据集上,表现最佳的 C&S 模型与 SOTA 性能之间没有太大的差距。
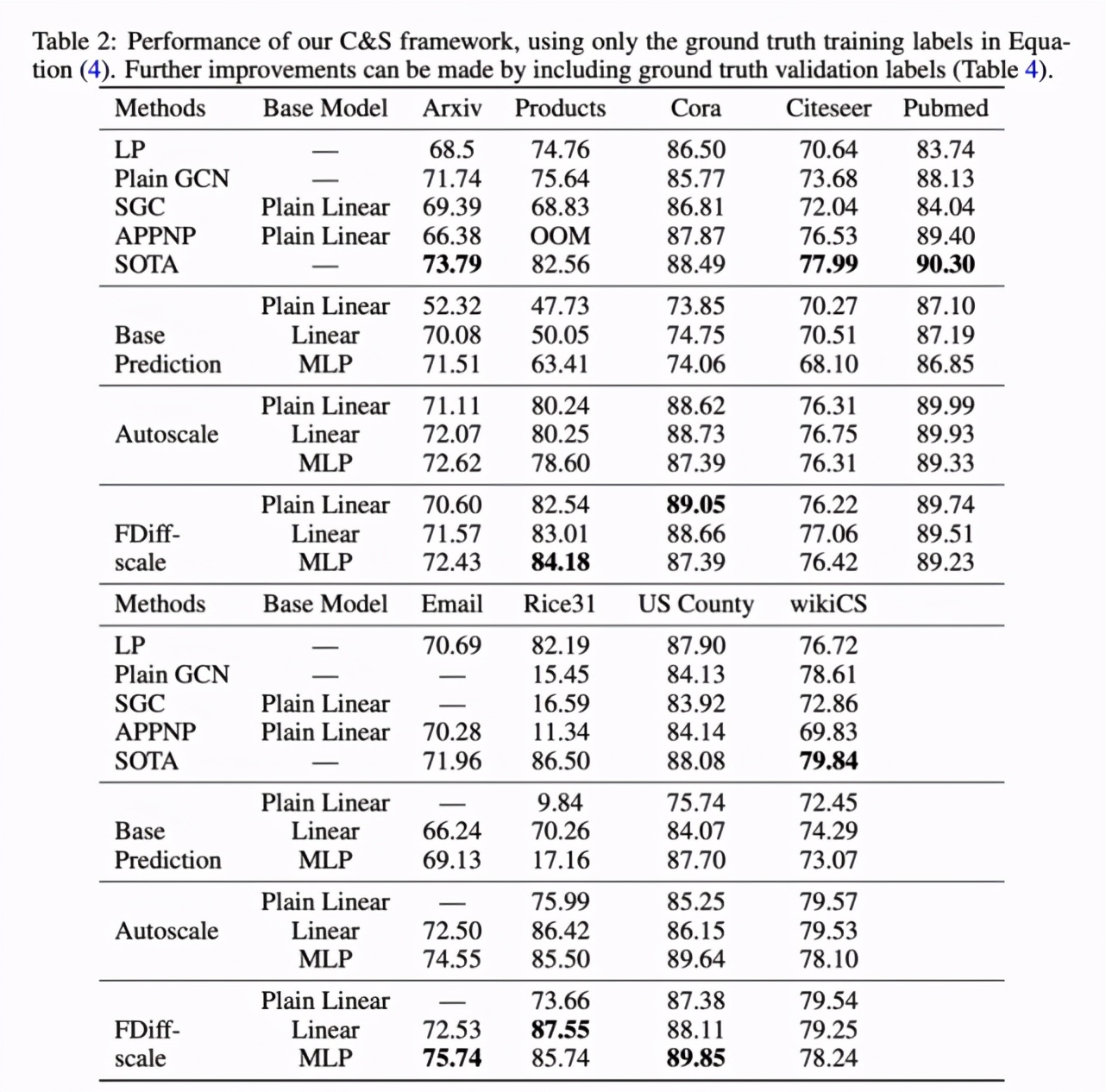
使用更多标签进一步提升性能
下表 4 展示了相关结果,强调了两点重要发现。其一,对于想要在很多数据集上实现良好性能的直推式节点分类实验而言,实际上并不需要规模大且训练成本高的 GNN 模型;其二,结合传统的标签传播方法和简单的基础预测器能够在这些任务上优于图神经网络。
更快的训练速度,性能超过现有 GNN
与 GNN 或其他 SOTA 解决方案相比,本文中的 C&S 模型需要的参数量往往要少得多。如下图 2 所示,研究者绘制了 OGB-Products 数据集上参数与性能(准确率)的变化曲线图。
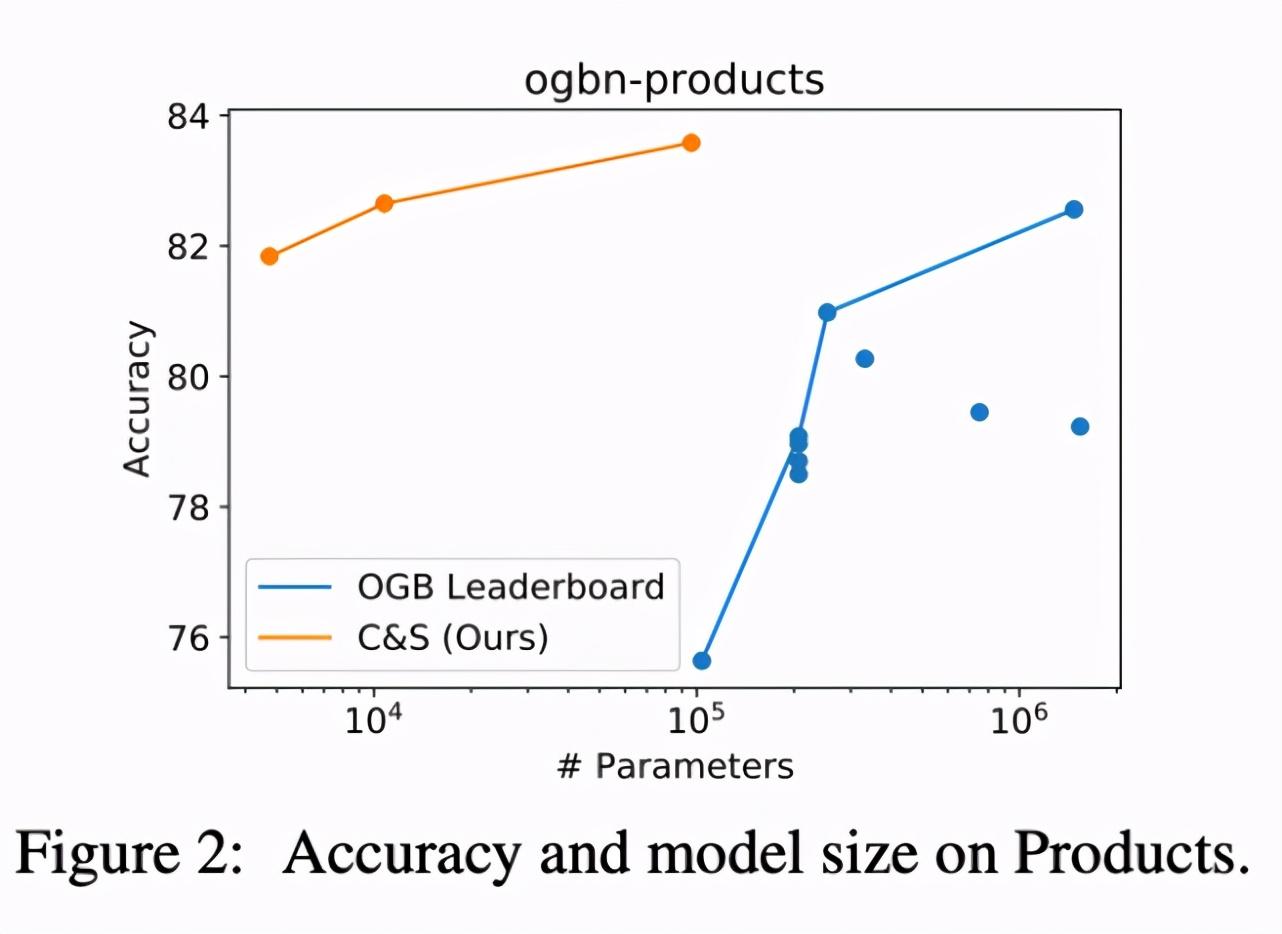
除了参数量变少之外,真正的增益之处在于训练速度更快了。由于研究者在基础预测中没有使用图结构,与其他模型相比,C&S 模型在保持准确率相当的同时往往实现了训练速度的数量级提升。
具体而言,与 OGB-Products 数据集上的 SOTA GNN 相比,具有线性基础预测器的 C&S 框架表现出更高的准确率,并且训练时长减至 1/100,参数量降至 1/137。
性能可视化
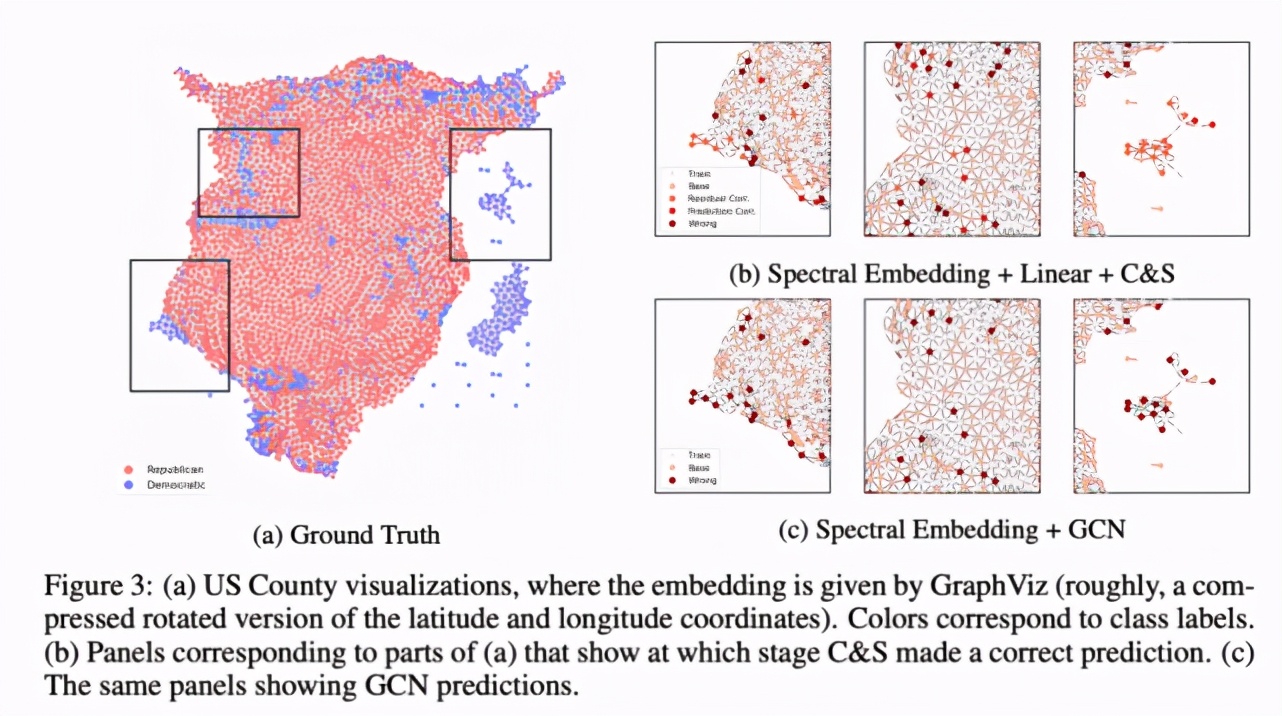
为了更好地理解 C&S 模型的性能,研究者将 US County 数据集上的预测结果进行了可视化操作,具体如下图 3 所示。正如预期的一样,对于相邻 county 提供相关信息的节点而言,残差关联往往会予以纠正。