Github 搜: "ggerganov/kbd-audio"
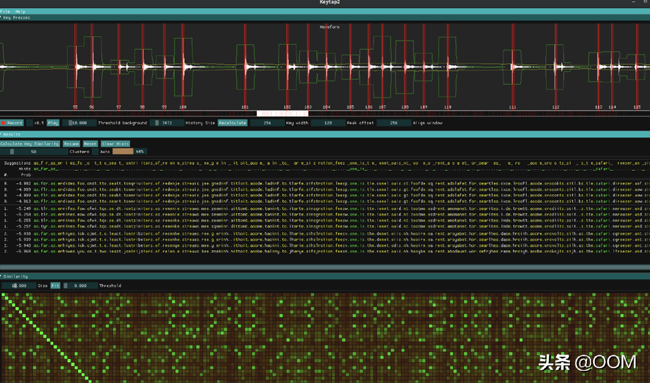
该项目的原理
主要目标是利用按键盘按键作为副声道产生的声音,以便猜测所键入文本的内容。为此,该算法将包含音频记录的训练集以及在该记录期间键入的相应键作为输入。使用此数据,算法可 了解不同按键的声音是什么,然后尝试仅使用捕获的音频来识别声音。从某种意义上讲,该训练集是针对特定的设置的-键盘,麦克风和二者之间的相对位置。更改这些因素中的任何一个都会使该方法无效。另外,当前的实现可以实时进行预测。
实施中涉及的主要步骤如下:
- 收集培训数据
- 创建预测模型(学习步骤)
- 按键检测
- 预测检测到的按键的按键
收集培训数据
在当前的实现中,击键之间的声音被简单地丢弃。在实际按下之前和之后,我们仅将音频保持在75-100毫秒之内。这有点棘手,因为按键和程序捕获的事件之间似乎存在随机延迟-最有可能涉及硬件和软件因素。
例如,这是在键盘上按字母“ g”的完整音频波形如下所示:
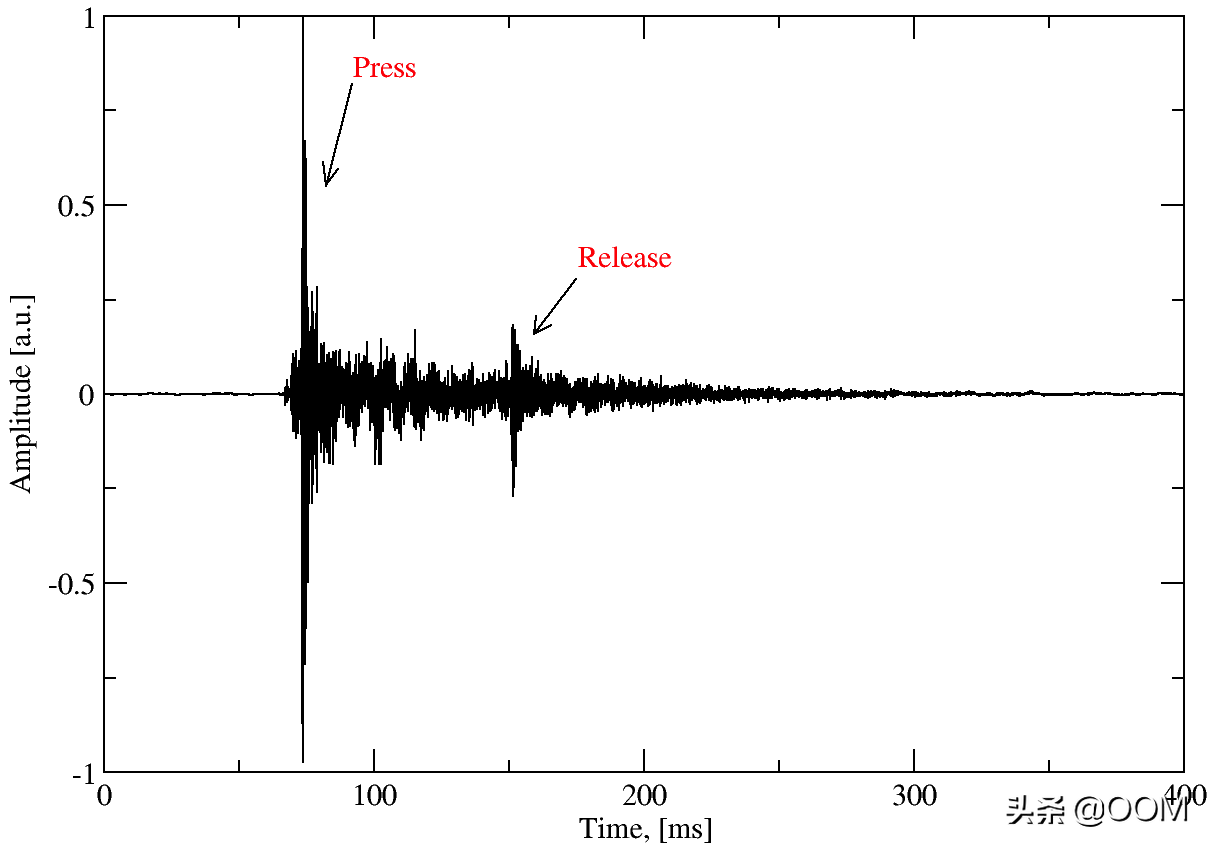
从图中可以看出,在压力峰值之后不久还有一个附加的释放峰值。Keytap只是忽略发布峰值。这里可能有可能提取其他信息,但是为了简单起见,数据被丢弃。最后,此键的训练数据如下所示:
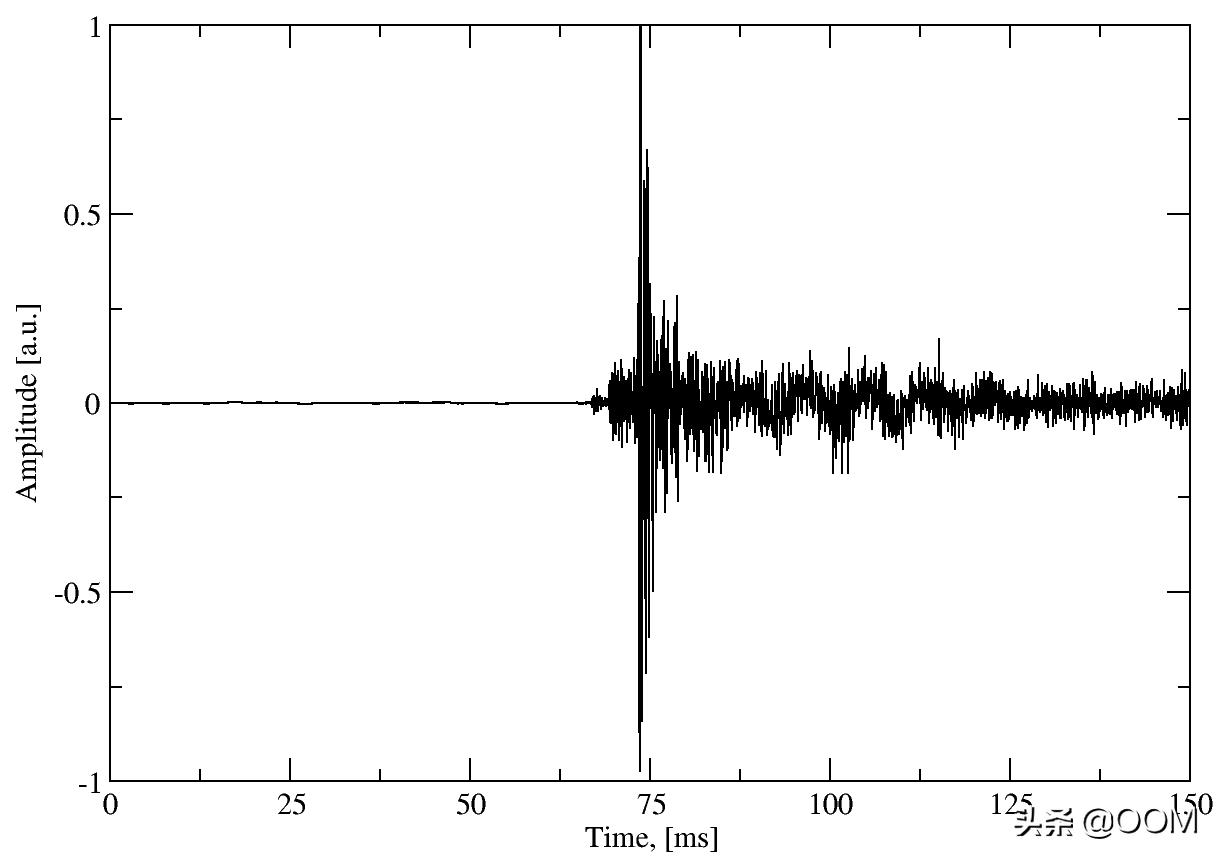
显然,75 ms的窗口对键入速度施加了一定的限制-如果在此时间段内击键重叠,则会混入不同键的训练数据。
另一个观察结果是,某个键的可用训练波形越多-越好。组合多个波形有助于减轻环境噪声。此外,根据用户按下按键的方式,各个按键的听起来可能略有不同,因此可能会捕获各种按键可能发出的声音。
创建预测模型
人们可以在这里获得很大的创造力-机器学习,人工智能,神经网络等。Keytap 使用非常简单的方法。对于每个培训密钥,我们执行3个步骤:
- 对齐收集的波形的峰值。这有助于避免在检测到按键事件之前进行随机的时间延迟(前面已说明)。
- 基于相似性度量的波形更精细的对齐。有时,峰值并不是最好的指标,因此我们使用更精确的方法。
- 对齐波形的简单加权平均。权重由相似性度量标准定义。
我们不希望直接应用步骤2,因为相似度指标的计算可能会占用大量CPU资源。因此,步骤1有效地缩小了对齐窗口的范围并减少了计算量。
在第3步之后,我们为每个键最终得到一个平均波形。稍后将其与实时捕获的数据进行比较,并用于预测最可能的密钥。
按键过程中使用的相似性指标是互相关(CC):
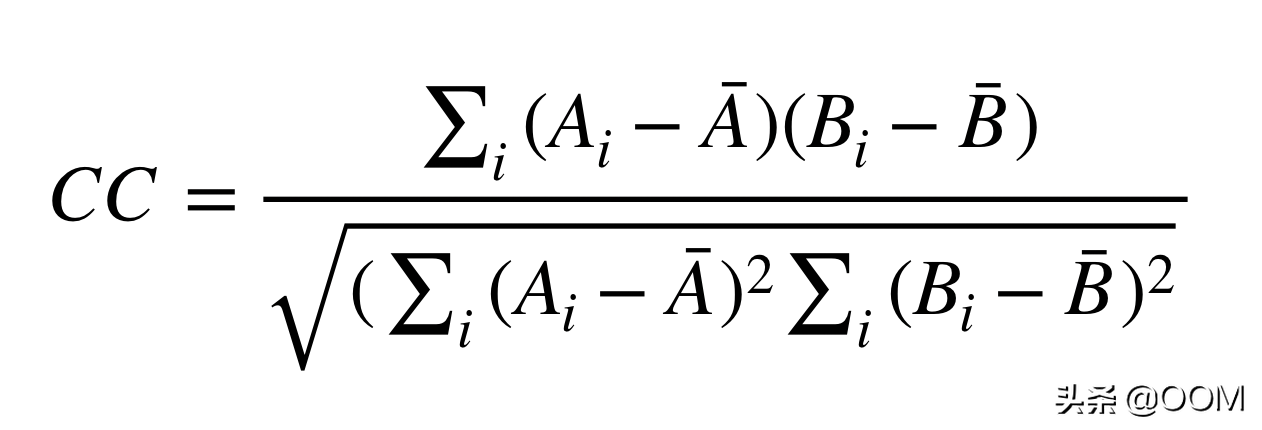
在此,Ai和Bi是被比较的两个波形的波形样本。较高的CC值对应于多个相似的波形。也可以使用其他相似性度量。
按键之间间隔的时间信息可能会集成到预测模型中。到目前为止,我已经避免了这样的方法,因为它们很难实施。
按键检测
Keytap使用相对简单的阈值技术来检测原始音频中的按键事件。显然,我们希望用户按下按键时会出现一个巨大的峰值,所以这就是我们想要的。该阈值是自适应的-它相对于过去几百毫秒的平均样本强度而言。
这种方法绝对不是完美的,我希望我知道如何做出更可靠的方法来检测新闻事件。我也不喜欢与当前阈值处理技术相关联的free参数。
预测检测到的按键的按键
一旦识别出潜在的按键事件,我们就可以确定波形中峰值的位置,并计算该部分波形与训练数据中所有平均波形的相似性度量。我们允许在峰周围有一个小的对齐窗口(如前所述)。我们期望最高相似性度量将对应于所键入的密钥。
一些观察
我注意到,当算法无法检测到正确的密钥时,它仍会预测附近的密钥。邻近,因为它位于真钥匙旁边。为此,我可以想到2种解释:
- 键盘上的附近按键会发出类似的声音
- 在这种方法中,按键相对于麦克风的位置对于预测非常重要
我认为选项1不太可能。
另一个观察结果是,与非机械键盘相比,机械键盘更容易受到此类攻击。
按键2
我很确定可以实现一种根本不需要收集训练数据的预测方法。假设用户以某种已知语言(例如英语)键入文本,则与该语言的N-gram有关的统计信息与检测到的按键的相似性度量结合起来足以检测出正在键入的文本。实际上,它归结为打破替代密码。
Keytap2是尝试演示这种攻击的一种尝试。我仍在努力-我停留在根据其CC对按键进行聚类的部分。但是我认为至少我已经准备好了替代密码破解部分。在实际工作时会尝试提供更多详细信息。