












本文转载自微信公众号「小明菜市场」,作者小明菜市场。转载本文请联系小明菜市场公众号。
前言
很长时间,Java都是一个相当受欢迎的企业编程语言,其框架丰富,生态完善。Java拥有庞大的开发者社区,尽管深度学习应用不断推进和演化,但是相关的深度学习框架对于Java来说相当的稀少,现如今,主要模型都是Python编译和训练,对于Java开发者来说,如果想要学习深度学习,就需要接受一门新的语言的洗礼。为了减少Java开发者学习深度学习的成本,AWS构建了一个Deep Java Library(DJL),一个为Java开发者定制的开源深度学习框架,其为开发者对接主流深度学习框架,提供了一个接口。
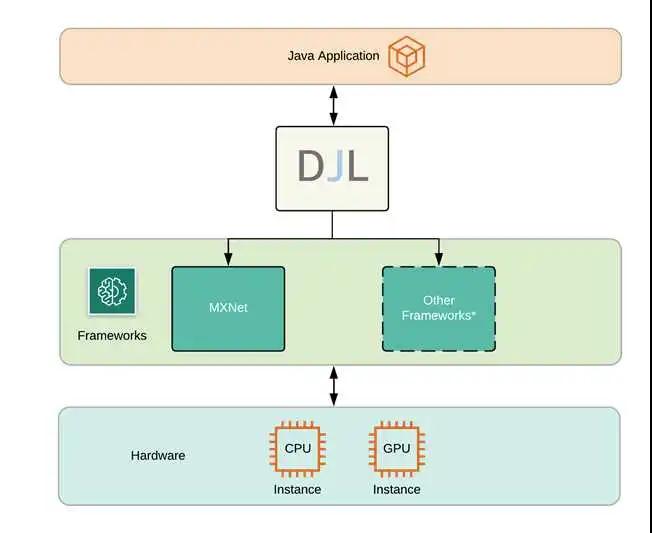
什么是深度学习
在开始之前,先了解机器学习和深度学习基础概念。机器学习是一个利用统计学知识,把数据输入到计算机中进行训练并完成特定目标任务的过程,这种归纳学习方法可以让计算机学习一些特征并进行一系列复杂的任务,比如识别照片中的物体。深度学习是机器学习的一个分支,主要侧重于对于人工神经网络的开发,人工神经网络是通过研究人脑如何学习和实现目标的过程中,归纳出的一套计算逻辑。通过模拟部分人脑神经间信息传递的过程,从而实现各种复杂的任务,深度学习中的深度来源于会在人工神经网络中编制出,构建出许多层,从而进一步对数据信息进行更为深层次的传导。
训练 MNIST 手写数字识别
项目配置
利用 gradle 配置引入依赖包,用DJL的api包和basicdataset包来构建神经网络和数据集,这个案例,使用 MXNet作为深度学习引擎,所以引入mxnet-engine和mxnet-native-auto两个包,依赖如下
- plugins {
- id 'java'
- }
- repositories {
- jcenter()
- }
- dependencies {
- implementation platform("ai.djl:bom:0.8.0")
- implementation "ai.djl:api"
- implementation "ai.djl:basicdataset"
- // MXNet
- runtimeOnly "ai.djl.mxnet:mxnet-engine"
- runtimeOnly "ai.djl.mxnet:mxnet-native-auto"
- }
NDArry 和 NDManager
NDArray 是 DJL 存储数据结构和数学运算的基本结构,一个NDArry表达了一个定长的多维数组,NDArry的使用方法,类似于Python的numpy.ndarry。NDManager是NDArry的管理者,其负责管理NDArry的产生和回收过程,这样可以帮助我们更好的对Java内存进行优化,每一个NDArry都会由一个NDManager创造出来,同时他们会在NDManager关闭时一同关闭,
Model
在 DJL 中,训练和推理都是从 Model class 开始构建的,我们在这里主要训练过程中的构建方法,下面我们为 Model 创建一个新的目标,因为 Model 也是继承了 AutoClosable 结构体,用一个 try block实现。
- try (Model model = Model.newInstance()) {
- ...
- // 主体训练代码
- ...
- }
准备数据
MNIST 数据库包含大量的手写数字的图,通常用来训练图像处理系统,DJL已经把MNIST的数据收集到了 basicdataset 数据里,每个 MNIST 的图的大小是 28 * 28, 如果有自己的数据集,同样可以使用同理来收集数据。
数据集导入教程 http://docs.djl.ai/docs/development/how_to_use_dataset.html#how-to-create-your-own-dataset
- int batchSize = 32; // 批大小
- Mnist trainingDataset = Mnist.builder()
- .optUsage(Usage.TRAIN) // 训练集
- .setSampling(batchSize, true)
- .build();
- Mnist validationDataset = Mnist.builder()
- .optUsage(Usage.TEST) // 验证集
- .setSampling(batchSize, true)
- .build();
这段代码分别制作了训练和验证集,同时我们也随机的排列了数据集从而更好的训练,除了这些配置以外,也可以对图片进行进一步的设置,例如设置图片大小,归一化处理。
制作 model 建立 block
当数据集准备就绪以后,就可以构建神经网络,在DJL 中,神经网络是由 Block 代码块构成的,一个Block是一个具备多种神经网络特性的结构,他们可以代表一个操作神经网络的一部分,甚至一个完整的神经网络,然后 block 就可以顺序的执行或者并行。同时 block 本身也可以带参数和子block,这种嵌套结构可以快速的帮助更新一个可维护的神经网络,在训练过程中,每个block附带参数也会实时更新,同时也会更新其子 block。当我们构建这些 block 的过程中,最简单的方式就是把他们一个一个嵌套起来,直接使用准备好的 DJL的 Block 种类,我们就可以快速制作各种神经网络。
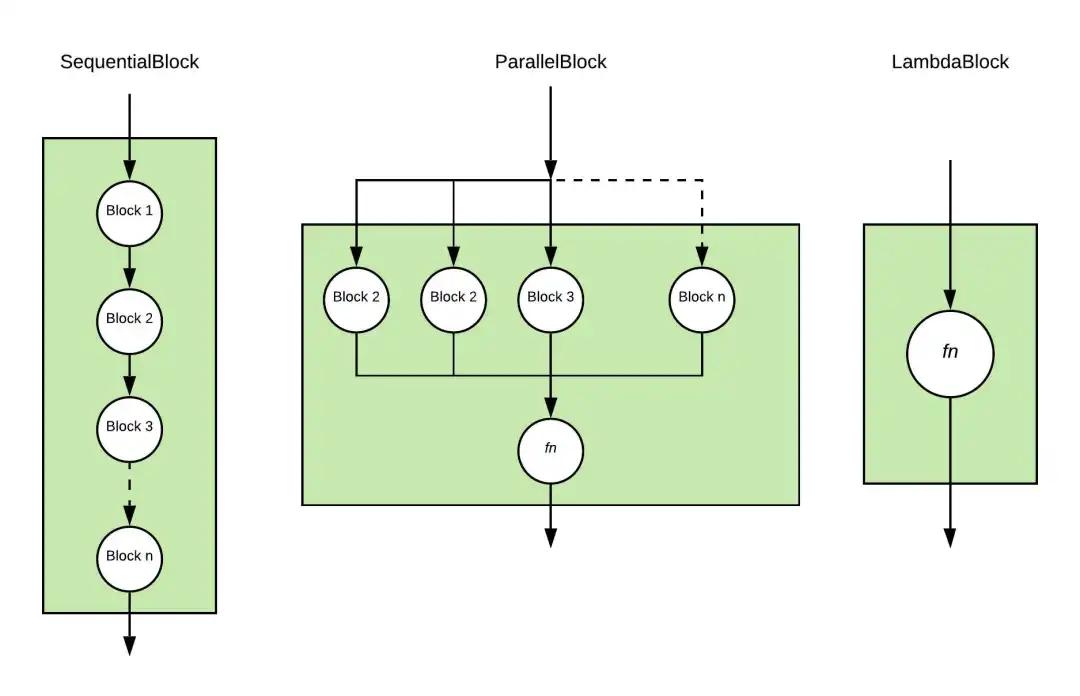
block 变体
根据几种基本的神经网络工作模式,我们提供几种Block的变体,
- SequentialBlock 是为了输出作为下一个block的输入继续执行到底。
- parallelblock 是用于将一个输入并行输入到每一个子block中,同时也将输出结果根据特定的合并方程合并起来。
- lambdablock 是帮助用户进行快速操作的一个block,其中不具备任何参数,所以在训练的过程中没有任何部分在训练过程中更新。
构建多层感知机 MLP 神经网络
我们构建一个简单的多层感知机神经网络,多层感知机是一个简单的前向型神经网络,只包含几个全连接层,构建这个网路可以直接使用 sequentialblock
- int input = 28 * 28; // 输入层大小
- int output = 10; // 输出层大小
- int[] hidden = new int[] {128, 64}; // 隐藏层大小
- SequentialBlock sequentialBlock = new SequentialBlock();
- sequentialBlock.add(Blocks.batchFlattenBlock(input));
- for (int hiddenSize : hidden) {
- // 全连接层
- sequentialBlock.add(Linear.builder().setUnits(hiddenSize).build());
- // 激活函数
- sequentialBlock.add(activation);
- }
- sequentialBlock.add(Linear.builder().setUnits(output).build());
可以使用直接提供好的 MLP Block
- Block block = new Mlp(
- Mnist.IMAGE_HEIGHT * Mnist.IMAGE_WIDTH,
- Mnist.NUM_CLASSES,
- new int[] {128, 64});
训练
使用如下几个步骤,
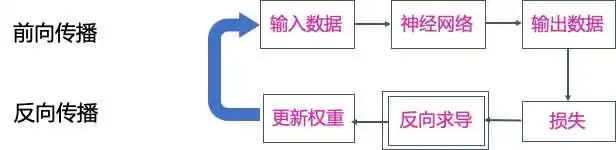
完成一个训练过程初始化:我们会对每一个Block的参数进行初始化,初始化每个参数的函数都是由设定的 initializer决定的。前向传播:这一步把输入数据在神经网络中逐层传递,然后产生输出数据。计算损失:我们会根据特定的损失函数 loss 来计算输出和标记结果的偏差。反向传播:在这一步中,利用损失反向求导计算出每一个参数的梯度。更新权重,会根据选择的优化器,更新每一个在 Block 上的参数的值。
精简
DJL 利用了 Trainer 结构体精简了整个过程,开发者只需要创建Trainer 并指定对应的initializer,loss,optimizer即可,这些参数都是由TrainingConfig设定,来看参数的设置。TrainingListener 训练过程设定的监听器,可以实时反馈每个阶段的训练结果,这些结果可以用于记录训练过程或者帮助 debug 神经网络训练过程中遇到的问题。用户可以定制自己的 TrainingListener 来训练过程进行监听
- DefaultTrainingConfig config = new DefaultTrainingConfig(Loss.softmaxCrossEntropyLoss())
- .addEvaluator(new Accuracy())
- .addTrainingListeners(TrainingListener.Defaults.logging());
- try (Trainer trainer = model.newTrainer(config)){
- // 训练代码
- }
训练产生以后,可以定义输入的 Shape,之后可以调用 git函数进行训练,结果会保存在本地目录下
- /*
- * MNIST 包含 28x28 灰度图片并导入成 28 * 28 NDArray。
- * 第一个维度是批大小, 在这里我们设置批大小为 1 用于初始化。
- */
- Shape inputShape = new Shape(1, Mnist.IMAGE_HEIGHT * Mnist.IMAGE_WIDTH);
- int numEpoch = 5;
- String outputDir = "/build/model";
- // 用输入初始化 trainer
- trainer.initialize(inputShape);
- TrainingUtils.fit(trainer, numEpoch, trainingSet, validateSet, outputDir, "mlp");
输出的结果图
- [INFO ] - Downloading libmxnet.dylib ...
- [INFO ] - Training on: cpu().
- [INFO ] - Load MXNet Engine Version 1.7.0 in 0.131 ms.
- Training: 100% |████████████████████████████████████████| Accuracy: 0.93, SoftmaxCrossEntropyLoss: 0.24, speed: 1235.20 items/sec
- Validating: 100% |████████████████████████████████████████|
- [INFO ] - Epoch 1 finished.
- [INFO ] - Train: Accuracy: 0.93, SoftmaxCrossEntropyLoss: 0.24
- [INFO ] - Validate: Accuracy: 0.95, SoftmaxCrossEntropyLoss: 0.14
- Training: 100% |████████████████████████████████████████| Accuracy: 0.97, SoftmaxCrossEntropyLoss: 0.10, speed: 2851.06 items/sec
- Validating: 100% |████████████████████████████████████████|
- [INFO ] - Epoch 2 finished.NG [1m 41s]
- [INFO ] - Train: Accuracy: 0.97, SoftmaxCrossEntropyLoss: 0.10
- [INFO ] - Validate: Accuracy: 0.97, SoftmaxCrossEntropyLoss: 0.09
- [INFO ] - train P50: 12.756 ms, P90: 21.044 ms
- [INFO ] - forward P50: 0.375 ms, P90: 0.607 ms
- [INFO ] - training-metrics P50: 0.021 ms, P90: 0.034 ms
- [INFO ] - backward P50: 0.608 ms, P90: 0.973 ms
- [INFO ] - step P50: 0.543 ms, P90: 0.869 ms
- [INFO ] - epoch P50: 35.989 s, P90: 35.989 s
训练结束以后,就可以对模型进行识别了和使用了。
关于作者
我是小小,一个生于二线城市活在一线城市的小小,本期结束,我们下期再见。




















