一、 预备知识
此案例实现功能:利用网络爬虫,爬取某地的天气,并打印和语音播报 。 要用到requests库,lxml库,pyttsx3库,没有的,可以先安装一下,都可以通过pip安装:
pip install requests
pip install lxml
pip install pyttsx3
- 1.
- 2.
- 3.
Requests库是个功能很强大的网络请求库,可以实现跟浏览器一样发送各种HTTP请求来获取网站的数据。
Lxml库是处理XML和HTML功能最丰富,最易于使用的库,通常用lxml库中的etree使HTML转化为文档。
Pyttsx3库是一个很简单的播放语音的库,你给它什么,它就读什么,当然别在意生硬的语气。 基本用法如下:
import pyttsx3
word = pyttsx3.init()
word.say('你好')
# 关键一句,没有这行代码,不会播放语音
word.runAndWait()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
码字不易废话两句:有需要学习资料的或者有技术问题交流可以私信小编发送“01”即可
爬虫是爬取网页的相关内容,了解HTML能够帮助你更好的理解网页的结构、内容等。 TCP/IP协议,HTTP协议这些知识了解一下就可以,能够让你了解在网络请求和网络传输上的基本原理,这次的小案例用不到。
二、 详细说一说
2.1. get请求目标网址
我们首先导入requests库,然后就用它来获取目标的网页,我们请求的是天气网站中的北京天气。
import requests
# 向目标url地址发送请求,返回一个response对象
req = requests.get('https://www.tianqi.com/beijing/')
# .text是response对象的网页html
print(req.text)
- 1.
- 2.
- 3.
- 4.
- 5.
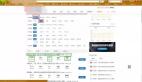
打印出的结果就是网站上显示的内容,浏览器就是通过这些内容“解析”出来我们看到的结构如下:
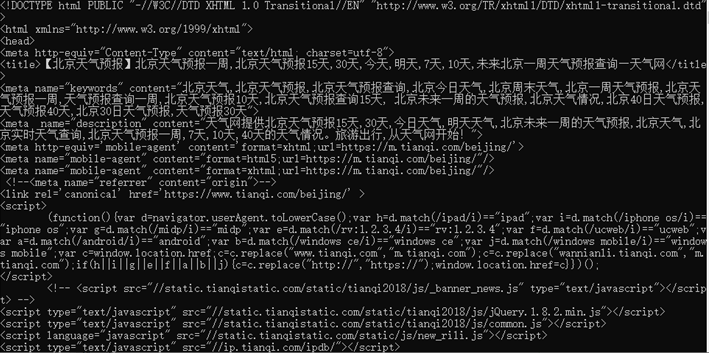
我们请求后的获得的数据
注意啦,小伙伴们有很大可能运行之后得不到网页代码,而是显示403,这是什么意思呢?
403错误是一种在网站访问过程中,常见的错误提示,表示资源不可用。服务器理解客户的请求,但拒绝处理它。
我们写的爬虫一般会默认告诉服务器,自己发送一个Python爬取请求,而很多的网站都会设置反爬虫的机制,不允许被爬虫访问的。
所以,我们想让目标服务器响应,那就把我们的爬虫进行一下伪装。此小案例就用常用的更改User-Agent字段进行伪装。
改一下之前的代码,将爬虫伪装成浏览器请求,这样就可以进行正常的访问了。
import requests
headers = {'content-type':'application/json', 'User-Agent':'Mozilla/5.0 (Xll; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'}
# 向目标url地址发送请求,返回一个response对象
req = requests.get('https://www.tianqi.com/beijing/',headers=headers)
# .text是response对象的网页html
print(req.text)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
User-Agent字段怎么来的呢?我们以Chrome浏览器为例子,先随便打开一个网页,按键盘的F12或在空白处点击鼠标右键选择“检查”;然后刷新网页,点击“Network”再点击“Doc”,点击Headers,在信息栏查看Request Headers的User-Agent字段,直接复制,咱们就可以用啦。
2.2. lxml.etree登场
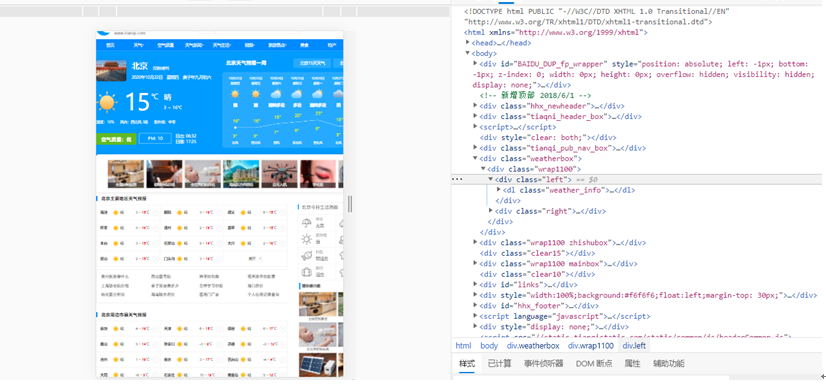
我们从网页请求获得的数据繁杂,其中只有一部分是我们真正想得到的数据,例如我们从天气的网站中查看北京的天气,只有下图中使我们想要得到的,我们如如何提取呢?这就要用到lxml.etree。
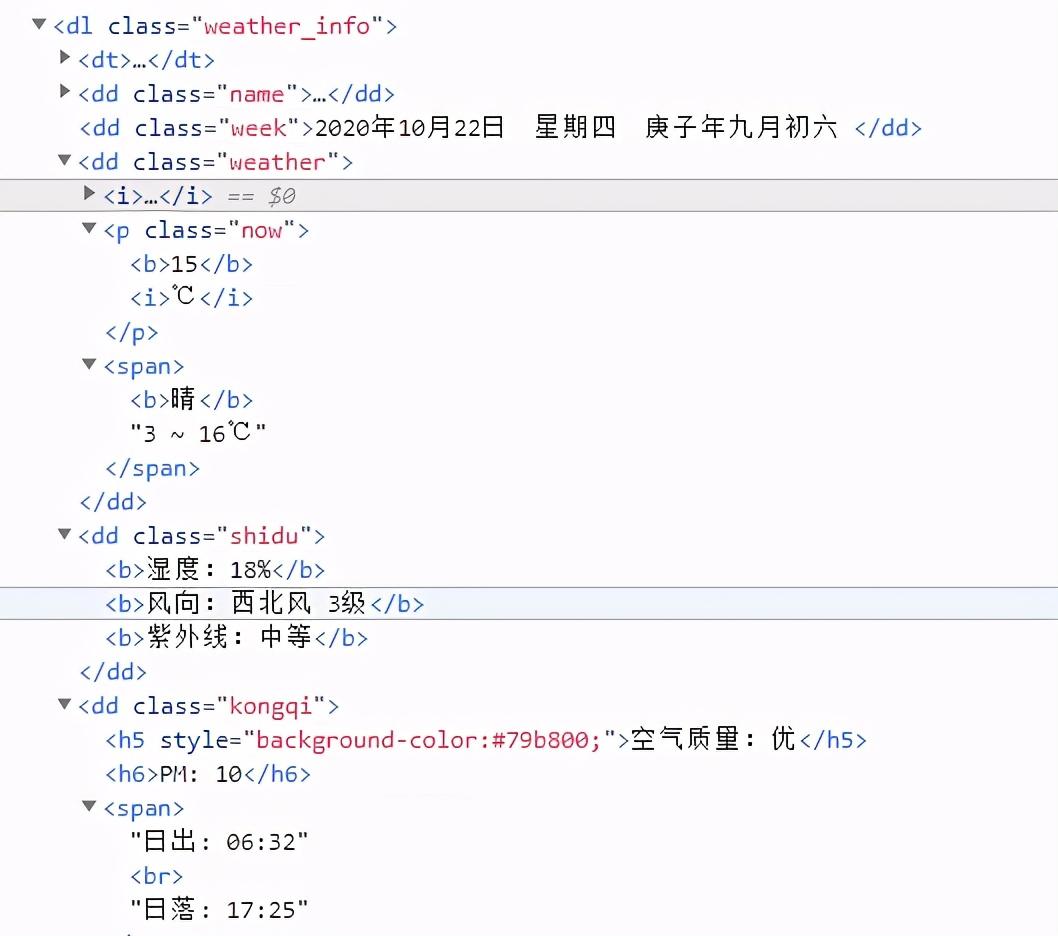
整个代码中只有一小部分我们想要的信息,我们发现想要的天气、温度啊都在“class='weather_info'”这一层级下,那这就好办了。我们在请求的代码的后面加上:
html_obj = etree.HTML(html)
html_data = html_obj.xpath("//d1[@class='weather_info']//text()")
- 1.
- 2.
我们print(html_data)一下看看提取是不是我们想要的数据。

发现连网页中换行符啊什么的也都提取出来了,还有,别忘了,提取出来的是列表哦。我们还要做一下处理。
word = "欢迎使用天气播报助手"
for data in html_data:
word += data
- 1.
- 2.
- 3.
- 4.
处理完我们打印一下看看,嗯,我们想要的都有了。不过还多了一个[切换城市],我们精益求精,最后把这个最后再去掉。

2.3. 把结果说出来
我们想要的数据都在word变量里啦,现在就让他读出来,用pyttsx3这个库,
ptt = pyttsx3.init()
ptt.say(word)
ptt.runAndWait()
- 1.
- 2.
- 3.
好的,现在都已完成。 我们一步一步都摸索过来,现在整合在一起,最后播放效果还是不错的,这是一次很美好的爬虫之旅,期待下次爬取!