Milvus是一个开源项目,可以为开源人工智能生态系统提供数据服务功能。人们需要了解如何从中受益。
在谈到开源人工智能项目时,人们通常会想到Google TensorFlow、PyTorch等模型框架项目,由于模型框架是训练人工智能模型的关键组成部分,因此这些项目通常最受关注。但是人工智能并不是一种单一的技术,而是一个复杂的技术领域,涉及多个子领域和许多不同的组成部分。
向人工智能转型的转折点
一般而言,技术升级的转折点是其回报远远超出成本。当将其应用于人工智能转型时,它将涉及一些基本因素,其中包括模型(算法)、模型推断和数据服务。
在谈论模型时,人们需要了解利用人工智能技术的期望值。如果希望采用人工智能技术来击败和取代人类,例如采用人工智能驱动的对话机器人取代所有的客户支持专家,那么对人工智能模型的需求将相当高,并且在短期内无法实现。
如果企业想让客户支持专家从单调繁琐的日常工作中解脱出来,这意味着计划利用人工智能技术提高人类的生产力和能力,那么现在的模型在许多情况下都能实现。
这听起来令人鼓舞。但是关于模型的激烈争论是,尽管一些模型可供使用,但却没有一个最佳的模型。那些雇佣人工智能科学家拥有这些技术发展水平(SOTA)模型的公司。如果只使用公共模型,那么会失去竞争优势吗?人们对此感到困惑,因为他们认为效率更高的模型会带来更高的业务价值,但这种想法可能是错误的。在大多数情况下,模型有效性与商业价值之间的关系既不是线性的,也不是单调递增的。这一函数的图形如下所示。
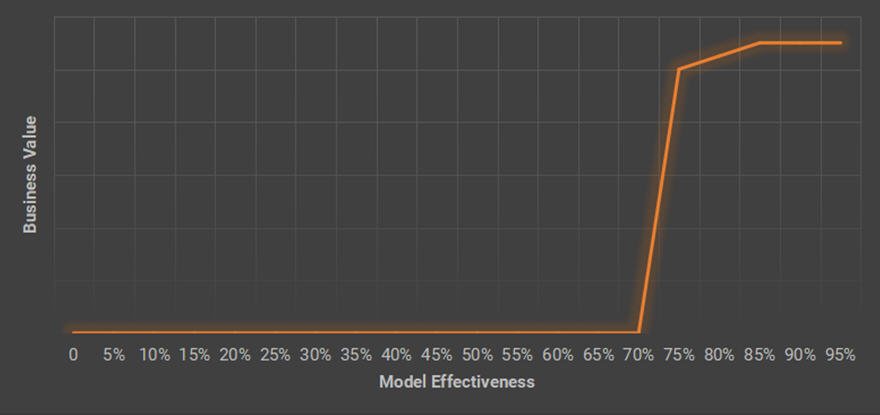
这是一个分段函数。在第一阶段,在该模型在应用程序场景中实现实用之前,没有任何业务价值。在第二阶段,尽管理论上更好的模型应该具有更好的性能(响应时间和有效性等),但在实际场景中它可能并不那么明显。以下进行一下了解。
在医生确认患者是否患有肺部感染之前,需要对其肺部进行CT检查,将生成约300张CT图像。而经验丰富的医生将不得不花费5~15分钟来研究这些CT图像。在通常情况下,如果治疗的患者数量不多不会有什么问题。但是,在极端情况下(例如持续蔓延的冠状病毒疫情),患者数量激增将让医生不堪重负。
一个好消息是,数据科学家致力通过计算机视觉技术帮助医生。他们训练的模型可以在几秒钟内处理成百上千的CT图像并提供诊断建议。因此,医生只需花费1分钟的时间就可以查看模型生成的结果。因此,在采用机器学习技术之前,医生平均需要花费10分钟的时间才能查看一次CT扫描生成的结果,而现在大约需要1分钟。生产率提高了近90%。
如果有一个更快的模型,只需要3秒钟就可以生成结果,那会怎么样?如果有一个更有效的模型可以将准确度从80%提高到90%会怎么样?医生检查的结果会更少吗?其答案是否定的,这是因为该模型中,如果十分之一将会出错,但并不知道哪个是错误的,医生必须审查所有结果。因此不会节省更多的诊断时间。
此外,为了降低模型推理服务的成本,有时需要牺牲模型有效性。例如一个拥有5500万张商标图片的商业智能平台提供商,该公司希望提供一项服务,允许用户搜索这些商标的所有者。用户通过上传商标图像作为输入查询而不是给出关键字来执行搜索。
其背后的技术是计算机视觉,例如VGG模型。如果企业在后端服务器上运行模型推理,则必须分配和预留数据中心的硬件资源。另一个选择是部署一个规模更小的模型,这样企业就可以把模型推理放在边缘计算设备上(大多数情况下是智能手机)。它肯定会降低像GPU这样昂贵的模型推理硬件的成本。这是另一个例子,SOTA模型不可能在所有场景中都具有竞争力。
人们已经处在人工智能转型的转折点。接下来的问题是,如何走过这一转折点,并采用人工智能技术来增强业务能力。
可用模型是先决条件。但是,如果只具有模型,也无法轻松开发人工智能程序。像传统应用程序一样,数据服务始终是至关重要的部分。可以看到,它已成为当今采用人工智能的重要组成部分。这就是为什么启动开源项目Milvus来加速采用人工智能的原因。
采用人工智能的数据挑战
一些企业尝试通过人工智能技术处理的大多数数据都是非结构化的,因此期望Milvus项目为非结构化数据服务提供坚实的基础。
人们通常将数据分为结构化数据、半结构化数据、非结构化数据这三种。结构化数据包括数字、日期、字符串等。半结构化数据通常包括特定格式的文本信息,例如各种计算机系统日志。非结构化数据包括图片、视频、语音、自然语言和任何其他不能由计算机直接处理的数据。
据估计,非结构化数据至少占数字数据世界的80%。例如,人们可能每天与其家人、朋友或同事发送和接收数kB的短信。但即使只在移动设备上拍一张照片,例如采用具有1200万像素的摄像头iPhone 11,一张照片高达几兆字节。那么如果拍摄720p分辨率的视频呢?
一些企业开发了关系数据库、大数据等技术来高效地处理结构化数据。而半结构化数据可以通过基于文本的搜索引擎Lucene、Solr、Elastic search等进行处理,但是对于大量的非结构化数据,在以往并没有有效的分析方法。直到深度学习技术在近年来兴起,非结构化数据处理技术得到了快速的发展。
非结构化数据服务
嵌入是深度学习的一个术语,是指通过模型将非结构化数据转换为特征向量。由于特征向量是数字数组,因此很容易由计算机处理。因此,非结构化数据的分析可以转换为矢量计算。
一个最普遍的论点是特征向量似乎是非结构化数据处理的中间结果。那么是否有必要建立通用的矢量相似度搜索引擎?是否应将其包括在模型中?
专家认为,特征向量不仅仅是中间结果。它是深度学习场景中非结构化数据的知识表示。这也称为特征学习。
另一个论点是,由于特征向量还包含数值,为什么不对现有的数据处理平台(例如数据库)或计算框架(例如Spark)执行向量计算。
确切地说,向量由数字列表组成。这导致矢量计算和数值运算之间的两个重大区别。
- 首先,向量和数字最频繁的运算是不同的。对于数字来说,加减乘除是最常见的运算。但是对于向量,最常见的要求是计算相似度。人们会看到,在这里给出了计算欧几里德距离的公式,向量的计算比普通的数值计算要高得多。
- 其次,数据的索引组织不同。在两个数字之间,可以互相比较数值。这样就可以像B树那样根据算法来创建数字索引。但是在两个向量之间,无法进行比较。只能计算它们之间的相似性。因此矢量索引通常是基于近似最近邻神经网络算法。
由于这些显著的差异,传统的数据库和大数据技术很难满足矢量分析的要求。他们支持的算法和他们关注的场景都是不同的。