












本文要介绍的是 2019 年 SOSP 期刊中的论文 —— KVell: the Design and Implementation of a Fast Persistent Key-Value Store[^1],该论文实现的 KVell 是为现代 SSD 开发的键值存储系统,与使用 LSM 树(Log-structured merge-tree)或者 B 树的主流键值存储不同,KVell 为了充分利用新设备的性能并降低 CPU 的开销使用了完全不同的设计。
作为软件工程师,我们直接与硬件打交道的概率其实很少,大多数时间都会通过操作系统以和 POSIX 间接操作不同的硬件。虽然看起来过去 10 年磁盘等存储硬件的演变与更新非常缓慢,但是实际上:
- 磁盘远比 10 年前要快得多;
- 磁盘的随机和顺序 I/O 性能差距变小;
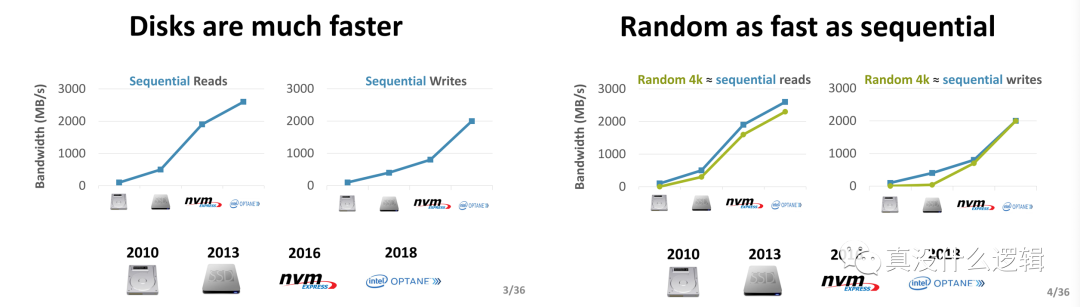
图 1 - 磁盘的演进[^2]
磁盘性能和特性的演进使得在过去很多键值存储成立的设计变得无效,例如:随机 I/O 的速度远远慢于顺序 I/O,很多数据库为了减少随机 I/O 的次数会使用特定的数据结构并牺牲一些 CPU 计算资源,但是在最新的硬件上已经没有太多的必要了。
KVell 的论文中不止提到了目前主流键值存储在新存储设备上各种问题,还给出了最新的设计原则、实现方式以及对性能的评估。我们在这里不会面面俱到的介绍论文中全部的内容,主要会分析主流键值存储的问题以及最新的设计原则,其余的内容各位读者可以在论文中自行探索。
实现问题
目前的大多数的键值存储系统都会使用 LSM 树或者 B 树作为主要的数据结构存储数据,这两种不同的数据结构适合用于不同类型的工作负载:
LSM 树:适合写密集型的负载;
B 树:适合读密集型的负载;
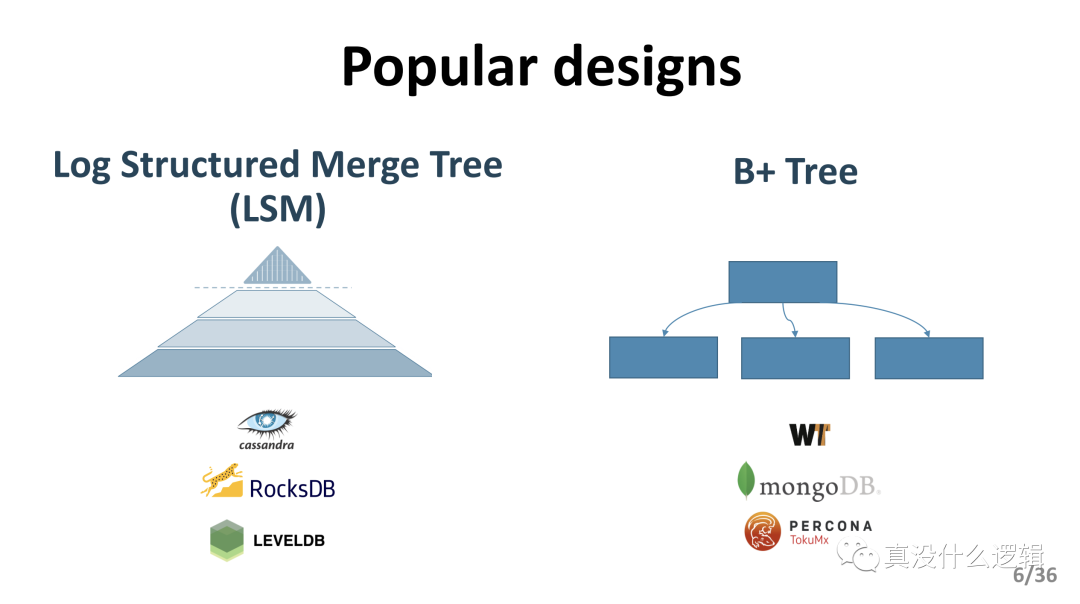
图 2 - LSM 和 B 树
RocksDB 和 Cassandra 等数据库都使用 LSM 树,而 MongoDB 以及其他的数据库都会使用 B 树和它的变种。虽然这两者设计在过去都有着优异的表现,不过这两种设计在 NVMe SSD 这种较新的硬件上表现地并不好,CPU 成为了瓶颈并导致严重的性能波动。
LSM 树
LSM 树是为写密集型负载特别优化的数据结构,在 LSM 树中,我们使用内存缓存接收所有的写操作并将变更批量写入磁盘,内存缓存中的数据会被后台线程合并到持久存储里的树形结构中。
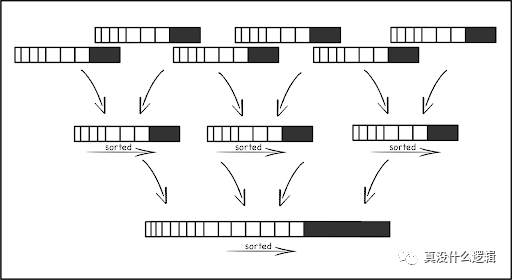
图 3 - LSM 树
磁盘中的数据结构包含多个层级,每个层级都会包含多个不可变的、排序后的文件,同一个层级中文件的键范围也不会有重叠。为了保证上述特性,LSM 引入了 CPU 和 I/O 密集的操作 — 压缩,如上图所示,压缩会将多个低层级的文件合并成更高层级的文件,保证键值对的顺序并删掉其中重复的键。这也使得 CPU 在新的存储设备上已经成为 LSM 树的主要瓶颈,这种设计让我们在旧设备上花费 CPU 时间保证数据的顺序并降低扫描操作顺序访问磁盘时的延迟。
除了 CPU 成为瓶颈之外,使用 LSM 树的键值存储的负载在数据压缩时会受到显著的影响,论文中的数据表示 RocksDB 在压缩期间的性能可能会降低一个数量级,虽然有一些技术可以缓解数据压缩的影响,但是这些方法在高端的 SSD 上却并不适用。
B 树
B+ 树只在叶节点存储键值对数据,内部的节点只包含用于路由的键,每个叶节点都包含一组排序后的键值对,所有的叶节点会组成方便扫描的链表。最先进的 B+ 树为了实现优异的性能都会依赖缓存,大多数的写操作也都会先写入提交日志再写入缓存,当缓存中的数据被驱逐时,B+ 树中的信息才会被更新。
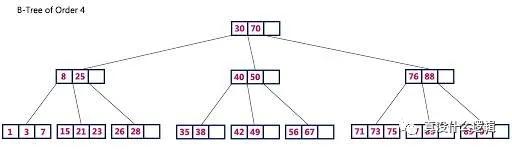
图 4 - B 树
B+ 树中有两种操作可以持久化其中的数据,也就是检查点(Checkpoint)和驱逐(Eviction);其中,前者是按照固定频率触发的,当日志的大小达到了特定的阈值后才会触发,这样可以保证提交日志的大小在固定范围内,而驱逐会从缓存向树中写入脏数据,它也会在缓存达到特定阈值时触发写入。
这种设计更容易受到同步(Synchronization)额外开销的影响,论文在测试中发现只有 18% 的时间用于处理客户端的请求,而其他时间都用于不同的等待,内核中 75% 的时间都在等待 futex 和 yield 等函数调用。
当内存中数据的驱逐不能快速完成时,B 树的性能也会受到影响,论文中的数据表示 WiredTiger 的吞吐量会在延迟期间从 120 Kops/s 降低到 8.5Kops/s,这种巨大的影响持续几秒钟的时间才会恢复。
设计原则
为了利用新存储设备的特性并减少键值存储的 CPU 开销,我们在现代 SSD 上开发的 KVell 会遵循如下所示的设计原则提高键值存储的性能:
- 不共享数据:所有的数据结构都分片存储在不同的 CPU 上,所有的 CPU 也就不需要在执行计算时同步数据;
- 磁盘中的数据不排序、内存中的索引排序:在磁盘上存储未经排序的数据,避免昂贵的重排操作;
- 减少系统调用、而不是顺序 I/O:因为现代 SSD 上的随机 I/O 和顺序 I/O 有着相似的性能,所以减少批处理 I/O 能够降低 CPU 的额外开销;
- 不需要提交日志:不在内存中缓存数据的更新,避免不必要的 I/O 操作;
不共享数据
在多线程的软件系统中,稍微有常识的人都知道不同线程之间同步数据会对性能带来比较大的影响,让多个线程之间不共享数据就可以避免上述的同步开销,减少线程等待带来的性能损失。
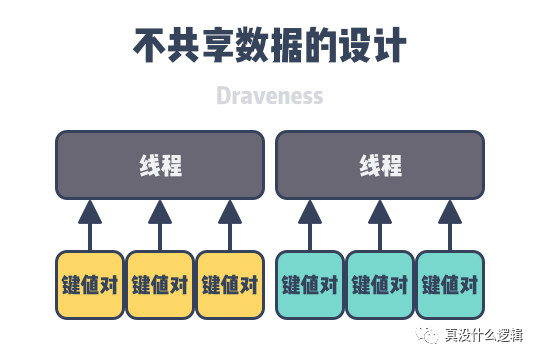
图 5 - 不共享数据的设计
为了实现这一目标,KVell 的每个线程都会处理一组特定键的操作并维护这些键相关的私有数据结构:
- 轻量级的、内存中的 B 树索引 — 存储了键在持久存储的位置;
- I/O 队列 — 负责从持久存储中快速读取或者写入数据;
- 空闲列表 — 内存中的用于存储键值对的硬盘块;
- 页面缓存 — 使用内部的页面缓存,不依赖于操作系统;
键值存储的大多数操作都只是对单个键的增删改查,这些操作都不需要多线程之间的数据同步,只有遍历键值的扫描才需要不同线程之间同步内存中的 B 树索引。
磁盘不排序
因为 KVell 不会在磁盘上按照顺序排序数据,所以键值对在磁盘中初始位置就是它的最终位置,这种不排序的方式不仅可以减少插入项目的额外开销,而且可以消除磁盘维护操作带来的 CPU 开销。
无序的键值对虽然可以降低写操作的开销,但是也会影响扫描时的性能,不过根据论文中的测试,扫描的操作在遇到中等大小的负载以及大键值对时不会被明显地影响,所以这个结果在多数情况下是可以接受的。
减少系统调用
在 KVell 中,所有的操作都会在磁盘中执行随机的读写,所以它不会浪费 CPU 时间将随机 I/O 转换成顺序 I/O。与 LSM 键值对类似,KVell 会将 I/O 请求批量转发给磁盘,它的主要目的是减少系统调用的次数,即 CPU 的额外开销。有效地键值存储应该向磁盘发出足够的请求保证磁盘拥有足够的工作,但是不应该发出过多的工作影响磁盘的性能并带来较高的延迟。
移除提交日志
KVell 不会依赖提交日志决定数据是否被系统持久化,它只会在更新写入到磁盘的最终位置时确认更新,一旦更新被工作线程提交,它会在下一批 I/O 请求中处理。提交日志的作用其实是将随机 I/O 变成顺序 I/O,解决崩溃带来的一致性影响,但是因为今天的随机 I/O 与顺序 I/O 已经有着类似的性能,所以提交日志在键值存储中已经失去了过去的作用,移除提交日志可以减少磁盘带宽的占用。
总结
KVell 作为基于最新硬件的键值存储系统,它在特定场景下有着非常优异的性能表现,论文中给出了它与主流的键值存储在不同负载下的吞吐量对比,其中 YCSB A、YCSB B、YCSB C 和 YCSDN E 分别是写密集型、读密集型、只读和扫描密集型地任务,从中我们可以看出,在除了扫描密集型地任务之外的其他负载中,KVell 的表现都远好于 RocksDB 等主流键值存储:
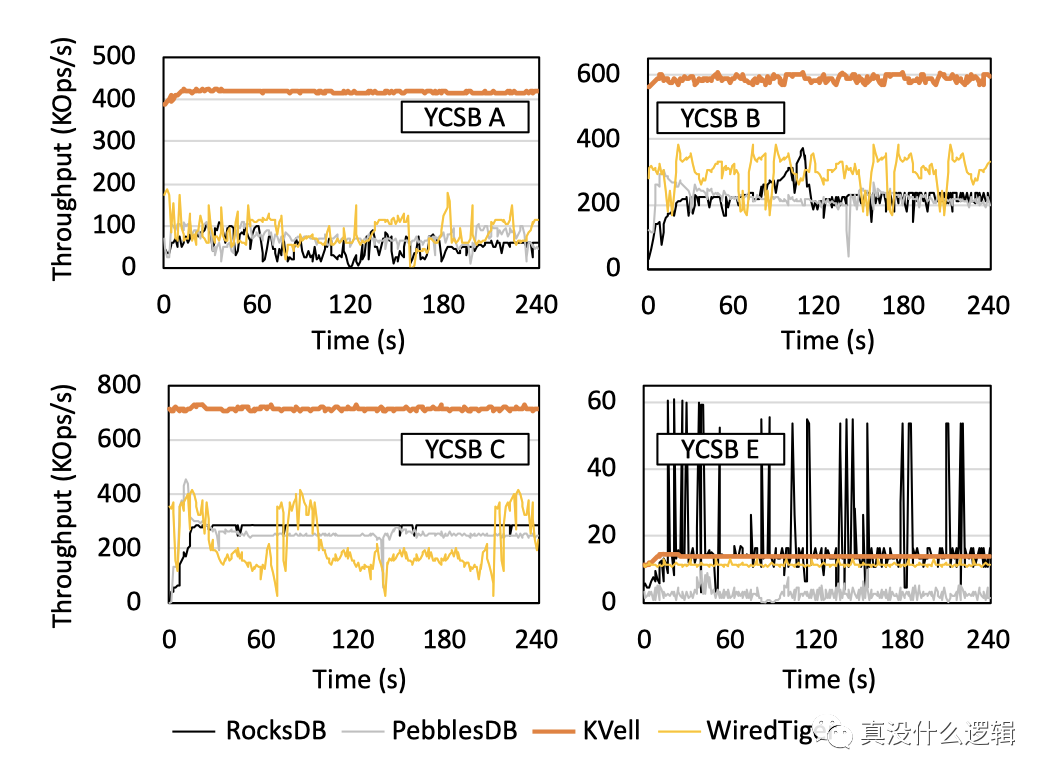
图 6 - KVell 吞吐量对比
作为软件工程师,虽然说操作系统为我们提供了操作硬件的标准接口,使得我们不用于硬件直接接触,可以将更多的精力放到软件上,但是我们仍然要时刻牢记硬件对软件系统的诸多影响和限制并用发展的眼光看待硬件的进步,也只有软硬件结合才能带来极致的性能。
本文转载自微信公众号「真没什么逻辑」,可以通过以下二维码关注。转载本文请联系真没什么逻辑公众号。
















