灵魂拷问
- MQ消息的消费为什么有时候要求幂等性?
- 你们都说可以用版本号来解决幂等性消费?
- 什么才是消息幂等性消费的根本性问题?
随着系统的复杂性不断增加,多数系统都会引入MQ来进行解耦,其实从引入MQ的初衷来说,多数系统是为了解耦多个模块带来的复杂性,而有些“架构师”却说的:为了解决性能问题。。。当然我不排除MQ有流量削峰的作用,我只是说大部分系统引入MQ最初的初衷应该是系统解耦。
当一个大的单体系统逐渐被拆分为多个小系统,也就是所谓的微服务拆分之后,无论是微服务之间的通信,还是分布式事务,几乎都需要MQ的支持,这也充分体现了分布式系统中MQ的重要性。这个时候整个系统间的交互就类似于下图所示
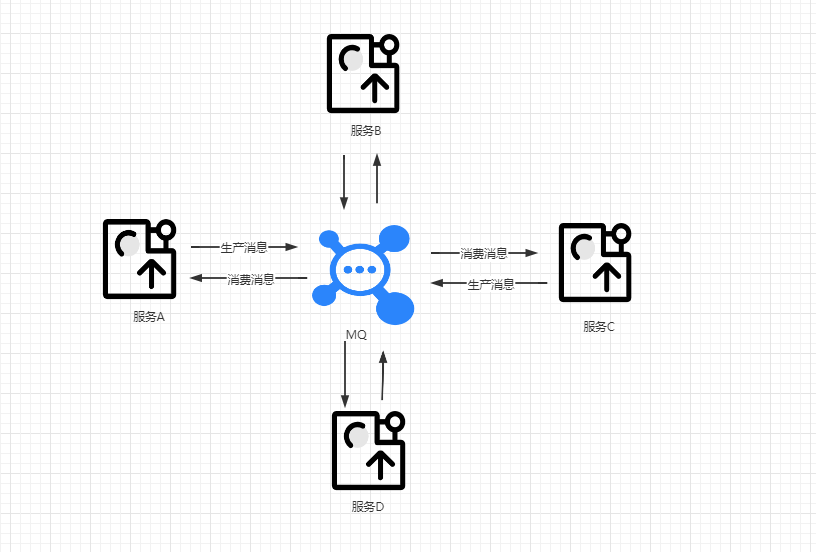
image
生产消息
既然引入了MQ这个组件,必然意味着同时存在消息的生产者和消费者,这也是典型的订阅模式。在消息数据的整个生命周期中,会依次经过生产者=》MQ=》消费者,三个主要部分。在生产者角度,消息的可靠投递是首要的任务,由于网络的不可靠性,所以消息理论上是不可能100%都投递成功的,针对这种情况,一般的解决方案就是消息重传。
当然重传机制并非无限制的重传,可以根据业务制定具体的重传策略,比如:可以设置最大重传次数为10次,而重传的时间间隔依次增加。这种方案虽然简单,但是带来的副作用就是消息重复投递的问题。
为什么需要幂等性消费
幂等是一个数学上的概念理论,它的意思是多次执行同一个操作和执行一次操作,最终得到的结果是相同的。
举一个业务不恰当但是很准确的栗子:你的女朋友出轨一次和出轨多次,对于你来说,结果其实是一样的:你被绿了。所以出轨一次和出轨多次的结果对于你来说是相同的。
对于MQ来说,退一万步讲,就算MQ的消息无重复投递的问题,在消费端的业务中,那些对于消息消费敏感的业务,我们在设计程序架构的时候也要把消息的幂等性消费考虑在其中,比如:用户购买商品赠送红包或者积分的业务场景,这样的场景对于消息的重复消费很敏感,如果程序处理不当,出现重复给用户送红包的情况,估计程序员又要背锅来祭天了。
幂等性其实很好做
任何业务场景接口的幂等性设计,都要找出幂等性产生的数据标识。
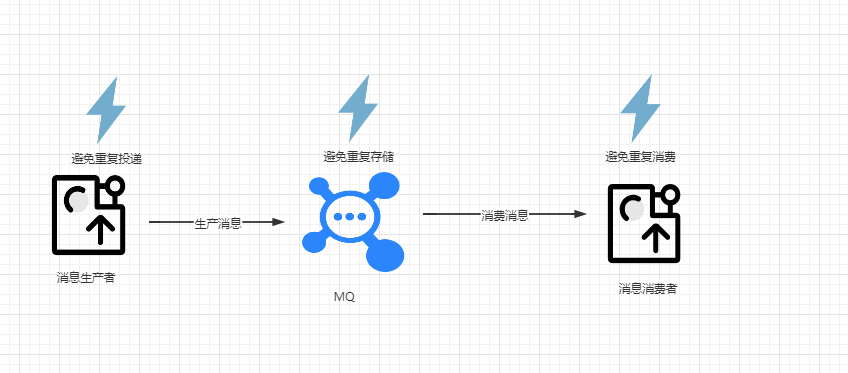
MQ消息的重复性问题,从消息的整个流转过程来看,大体上可以在两个方向来解决:
- 消息产生的时候避免投递重复性消息,既:消息生产者来保证消息唯一性
- MQ本身提供重复消息的过滤功能
- 消息被消费的时候避免被重复消费
image
在消息被消费之前的前半部分流程中,生产者可以利用唯一的消息id和ACK机制来做消息被重复投递的保证工作,但是这样会大大降低生产者业务的性能,一般情况下生产者都需要异步的来发送MQ消息,如果在发送的时候还需要检查消息是否被发送过,这无疑不是一个好的设计,而且你这样做的检查效果,只为命中很渺小的一部分数据,得不偿失,所以在生产者很少有人主动去做消息的重复投递检查工作。
至于在MQ的内部,有的MQ确实会提供幂等性的存储设计,比如Kafka引入了Producer ID(即PID)和Sequence Number。
- PID。每个新的Producer在初始化的时候会被分配一个唯一的PID,这个PID对用户是不可见的。
- Sequence Numbler。(对于每个PID,该Producer发送数据的每个都对应一个从0开始单调递增的Sequence Number。
Broker端在缓存中保存了这seqnumber,对于接收的每条消息,如果其序号比Broker缓存中序号大于1则接受它,否则将其丢弃。这样就可以实现了消息重复提交了。但是,只能保证单个Producer对于同一个的Exactly Once语义。不能保证同一个Producer一个topic不同的partion幂等。
然而这些都不是我们今天要说的重点,实际的业务中,消息的幂等性消费也更倾向于在消费端做,在消息的终点彻底解决问题,无论是在系统设计,还是在可扩展性上无疑都是最好的。
刚才也提到,消息既然要做到幂等性消费,必须要提供一个用于判断重复的标识,可以是自定义的消息ID,也可以是消息中几个字段联合起来的类似数据表中的主键,目前主流的做法是在生产方根据业务特点生成消息id,例如:给用户添加因为下单而赠送积分的消息id,就可以根据userid_orderId_积分数量来生成唯一的消息id。
有了唯一的消息id,消费者就可以把已经消费的消息id,本地存储下来用于过滤重复消息,当然如果数据量比较大的话,很早之前的历史数据完全可以删除或者转移到其他的备份表,毕竟同一个消息不可能过了很长时间再次被投递。以下是一个本地消息表的例子:
| 字段 | 说明 |
|---|---|
| MsgId | 消息id |
| CreateTime | 创建时间 |
| ... | 其他有用的业务字段 |
当消费新消息的时候,执行以下类似以下的sql语句,拿到消息是否已经消费过的结果来判断当前消息是否需要重复消费
select count(0) from table where MsgId='消息id'
当然,这里还会有问题,如果只有一个消费者进行消费,不会有任何问题,如果有多个消费者在并行的进行消费,在判断重复消息的时候你会需要锁来保证同样数据的顺序化,这个时候你可能需要分布式锁。
郑重提示
除了生成消息id这种方式之外,网上有很多文章指出可以利用版本号来解决幂等性问题,试问:这种方案又有多少人亲自实践过?今天我们就以给用户添加积分这个案例来庖丁解牛一下这个方案的做法:
- 用户的积分表中需要添加版本号(Version)字段
- 消息的生产者在消息投递中添加版本号字段
- 消费者根据消息的版本号来执行sql具体的sql类似:
- update user set amount=amount+10 ,version=version+1 where userid=100 and version=1
对于同一条消息的重复投递来说,这样做确实可以做到幂等性消费,毕竟程序利用数据库的锁机制来保证了一致性。那有什么问题呢?
消息的版本号问题
所有的分布式系统都面临着同样的问题,就是数据的一致性问题,MQ的消费场景也不例外。以上边用户加积分为案例,因为消息的生产者在投递消息的时候需要查询当前的版本号,类似于以下sql
- select version from table where userid=100
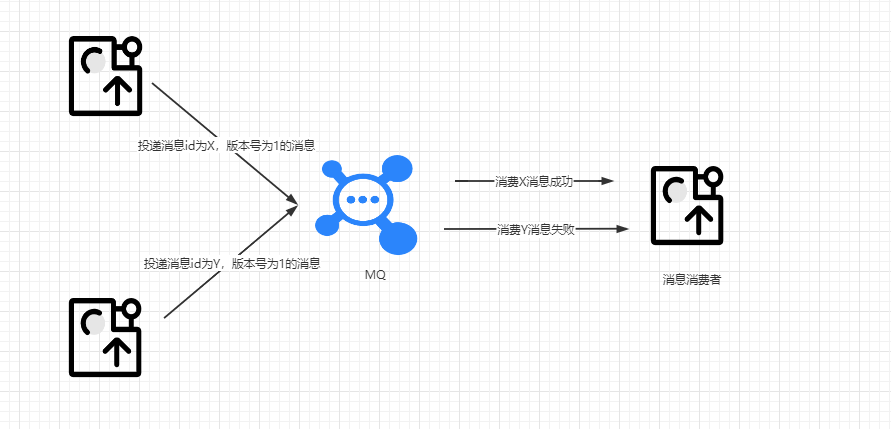
当查询到版本号信息自后,会把版本号作为消息体的一部分投递到MQ,那在并发的情况下会发生什么情况呢?假设当前的版本号为1:
线程A查询版本号为1,然后投递了版本号为1,消息id为x的消息,于此同时线程B也查询了当前用户版本,数值也为1,然后投递了消息id为Y的消息,这个时候消费端无论是先消费消息X还是消息Y,数据库的版本号都会增加,则导致了另外一个消息由于版本号的不符而消费失败。
image
本文转载自微信公众号「架构师修行之路」,可以通过以下二维码关注。转载本文请联系架构师修行之路公众号。