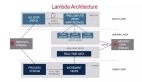
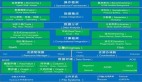
提到大数据,我们就离不开数据的收集整理,其中ETL是我们经常使用的用于构建数据仓库, 构建大数据的方法。
大数据处理阶段
此阶段的目标是使用单个模式来清理,规范化,处理和保存数据。最终结果是具有定义良好的架构的可信数据集。例如Spark之类的处理框架用于在机器集群中并行处理数据。在这里我们需要进行数据的验证,隔离掉不合法的数据,我们需要对不良数据进行筛选过滤。对于不规范的数据,我们需要有整理和清洁功能,我们要能够将一些低效的格式入json进行转换。同时我们可能还需要一些标准化的操作,比如对一些数值进行小数点位的精度转化。
大数据处理的最终目的就是创建一个可信数据集,然后下游系统可以依赖此数据源进行业务分析和数据计算。
对于大数据的处理,主要有下面的几个工具引擎。
Apache Hive
它是将SQL请求转换为MapReduce任务链的引擎。它主要实现的功能是对传入的SQL进行排序然后优化排序结果,最终得到高效率的请求结果。2018年它将MapReduce替换为Tez作为搜索引擎。它具有机器学习功能,并且在和其他流行的大数据框架进行集成。
Apache Spark
这是最著名的批处理框架。它是Hadoop生态系统的一部分,是一个托管集群,可提供强大的并性,有着精准的监控和出色的UI。它还支持流处理(结构化流)。基本上,Spark在内存中运行MapReduce作业,其性能是常规MapReduce性能的100倍。它与Hive集成以支持SQL,并可用于创建Hive表,视图或查询数据。它具有很多集成,支持多种格式,并且拥有庞大的社区。所有云提供商都支持它。它可以在YARN上运行作为Hadoop集群的一部分,还可以在Kubernetes和其他平台中使用。它具有许多的第三方库可以使用。
Apache Flink
第一个统一批处理和流传输的引擎,它可以用作像Kafka这样的微服务的主干。它可以作为Hadoop集群的一部分在YARN上运行,它还针对其他平台(如Kubernetes或Mesos)进行了优化。它非常快,并且提供实时流传输,使其成为针对低延迟流处理(尤其是有状态流)的一个比Spark更好的选择。它还具有用于SQL,机器学习等的库。它比Spark更快,是数据流的更好选择。
Apache Storm
是一个免费和开源的分布式实时计算系统,它专注于流传输,是Hadoop生态系统的托管解决方案部分。它具有可扩展性,容错性,可确保您的数据将得到处理,并且易于设置和操作。
Apache Samza
一个出色的有状态流处理引擎。Samza允许您构建有状态的应用程序,它可以从多个来源实时处理数据。它不仅可以在YARN集群上运行,也可以作为独立库单独运行。
Apache Beam
它本身不是引擎,而是将所有其他引擎结合在一起的统一编程模型的规范。它提供了可以与不同语言一起使用的编程模型,因此开发人员在处理大数据管道时不必学习新的语言。然后,它为可以在云或本地运行的处理步骤插入了不同的后端。Beam支持前面提到的所有引擎,您可以在它们之间轻松切换并在任何平台上运行它们:云,YARN,Mesos,Kubernetes。如果您要开始一个新项目,那么建议您从Beam开始,因为Beam是面向未来的。
Presto
Presto是一个开放源代码的分布式SQL查询引擎,适合于对各种大小,各种数据源进行交互式分析查询。
Presto是专为交互式分析而设计和编写的,当它的规模扩展到一定的规模的时候,它也可以实现商业数据仓库的处理速度。
Presto允许查询数据存在多个地方,包括Hive,Cassandra,关系数据库甚至专有数据存储。一个Presto查询可以合并来自多个来源的数据,从而可以在整个组织中进行分析。
Presto适用于期望响应时间从亚秒到数分钟不等的分析师。Presto打破了使用昂贵的商业解决方案进行快速分析或使用需要大量硬件的慢速“免费”解决方案之间的错误选择。
总结
处理引擎是当前在大数据词中使用的很著名的工具。作为大数据工程师,您将经常使用这些引擎。了解这些引擎的分布式特性并知道如何优化它们,保护它们并监视它们至关重要。
请记住,还有一些OLAP引擎提供了一种查询大量数据的单一解决方案,而无需编写复杂的转换,而是通过以一种特定的格式加载数据来提高查询的性能。
对于一个新项目,建议您研究Apache Beam,因为它在所有其他引擎的基础上提供了一个抽象,使您无需更改代码即可更改处理引擎。
对于流处理,特别是有状态流处理,请考虑Flink或Samza。对于批处理,请使用Spark。