还有一个月,下个月微软.NET 5将会正式发布,在大家都关注新型语言。不知道有对.NET 5有没有什么期待。

日前官方发布了一些针对.net 5特性说明的,其中gRPC性能上的表现令人瞩目。在不同gRPC服务器实现的社区运行基准测试中,.NET的QPS超越C++和Go,排在Rust之后夺得亚军。
gRPC是现代的开源远程过程调用框架。gRPC有许多令人兴奋的功能:实时流传输,端到端代码生成以及强大的跨平台支持。
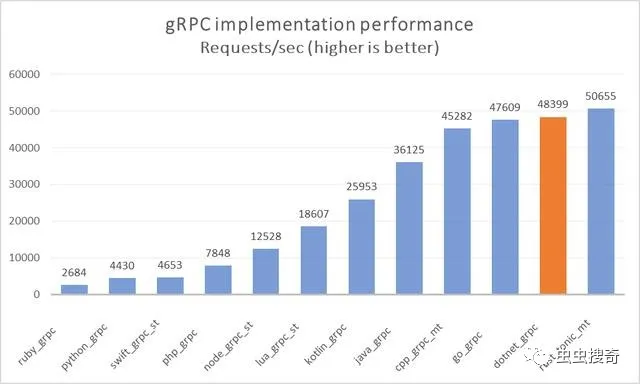
结果基于.NET 5中完成的工作。基准测试表明.NET 5服务器性能比.NET Core 3.1快60%。.NET 5客户端性能比.NET Core 3.1快230%。
本文我们就一起来学习下.NET 5究竟使用什么黑魔法能让性能如此大幅度的提高。
减少内存分配
去年,Microsoft给CNCF提供了.NET的gRPC的新实现。该框架建立在Kestrel和HttpClient之上的,gRPC成为.NET生态系统的一流成员。
gRPC使用HTTP/2作为其基础协议。当涉及到性能时,快速的HTTP/2实现是最重要的因素。.NET的gRPC服务器基于Kestrel建立,Kestrel是用C#编写的HTTP服务器,其设计中关注立足于性能,在TechEmpower基准测试中的性能最高的选手之一。而gRPC会自动从Kestrel的许多性能改进中受益。但是,.NET 5中进行了许多HTTP/2特定的优化。
减少内存分配是首先优化的部分。减少每个HTTP/2请求内存分配,就能减少垃圾回收(GC)的时间。
下面是请求超过10w个gRPC请求时候的性能分析器:
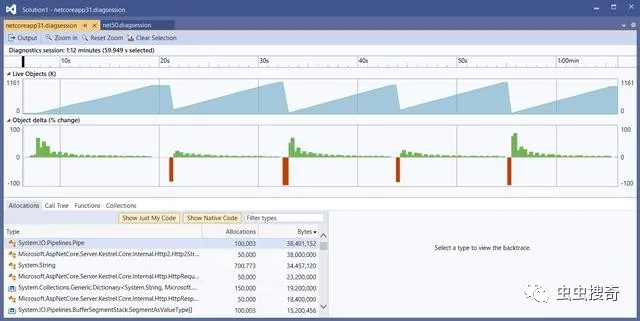
活动对象图的锯齿形图案表示内存在建立,然后进行了垃圾回收。每个请求大约要分配3.9KB。
通过在HTTP / 2连接中添加了连接池,每个请求的内存分配减少了一半。它可支持对内部类型(如Http2Stream和)和公共可访问类型(如HttpContext和HttpRequest)请求重用。
合并流后,可以进行一系列优化:
- 重用输入和输出Pipe实例。
- 重用已知的标头字符串值。与头重用有关,添加HTTP/伪装头作为已知头。String分配使用倒数第三字节。
- 重用了一些较小的按请求对象。
- 当服务器处于负载状态时,连接池非常有用,但是也需要释放不再使用的内存。如果最近5秒钟内HTTP请求没有使用,则从连接池中删除该流。
还有许多较小的减少内存分配的方法:
- 删除Kestrel的HTTP/2流控制中的分配。
- 每当触发流控制时,可重置的ManualResetValueTaskSourceCore
类型将替换分配新对象。 - 验证HTTP请求路径时,将数组分配替换为stackalloc。
- 消除了一些与日志记录有关的意外分配。
- 如果任务已经完成,避免分配。
- 最后通过特殊的Task
content-length 0字节保存字符串分配。
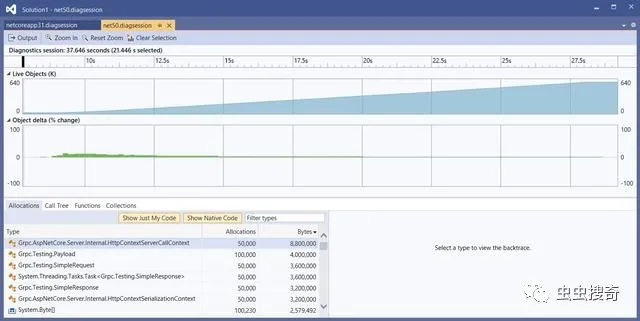
经过优化后,.NET 5中的每个请求内存分配只有330B,减少了92%。优化后锯齿图案不再出现。这样在服务器处理10w个gRPC调用时,垃圾收集也不再会运行。
从Kestrel中读取HTTP标头
HTTP/2连接支持通过TCP Socket的并发请求,这个功能称为多路复用。它允许HTTP/2有效利用连接,但是一次只能处理一个连接上的一个请求的标头。HTTP/2的HPack标头压缩是有状态的,并且取决于顺序。处理HTTP/2标头是一个瓶颈,因此要尽可能快。
优化的性能HPackDecoder。解码器是一个状态机,可读取传入的HTTP/ 2 HEADER帧。状态机允许Kestrel在帧到达时对其进行解码,但是解码器在解析每个字节之后检查状态。另一个问题是语义值,标头名称和值被复制了多次。该PR的优化包括:
- 加强解析循环。例如,如果刚刚解析了标头名称,则该值必须在后面。无需检查状态机即可确定下一个状态。
- 跳过所有语义解析。HPack中的文字具有长度前缀。如果知道接下来的100个字节是语义,则无需检查每个字节。标记语义的位置并在其末尾继续解析。
- 避免复制语义字节。以前,原义字节在传递给Kestrel之前总是复制到中间数组。在大多数情况下,这不是必需的,而是可以对原始缓冲区进行切片,然后将ReadOnlySpan
传递给Kestrel。
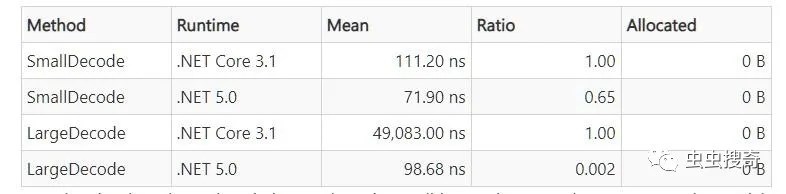
这些更改一起显着减少了解析标头所需的时间。标头大小几乎不再成了影响因素。解码器标记值的开始和结束位置,然后切片该范围。
- [Benchmark]
- public void SmallDecode() =>
- _decoder.Decode(_smallHeader, endHeaders: true, handler: _noOpHandler);
- [Benchmark]
- public void LargeDecode() =>
- _decoder.Decode(_largeHeader, endHeaders: true, handler: _noOpHandler);
结果:
标头解码后,Kestrel需要对其进行验证和处理。例如,特殊的HTTP/2标头:path和:method需要设置到HttpRequest.Path和HttpRequest.Method上,而其他标头需要转换为字符串并添加到HttpRequest.Headers集合中。
Kestrel具有已知请求标头的概念。已知标头是对常见请求标头的选择,这些请求标头已针对快速设置和获取进行了优化。为将HPack静态表头设置为已知头添加了一条甚至更快的路径。HPack静态表给出了61点共同的报头的名称和值可被发送,而不是全名的数ID。具有静态表ID的标头可以使用优化的路径绕过某些验证,并可以根据其ID快速在集合中进行设置。为具有名称和值的静态表ID添加了额外的优化。
添加HPack响应压缩
在.NET 5之前,Kestrel支持读取请求中的HPack压缩标头,但不压缩响应标头。响应头压缩的明显优势是网络使用量减少,但同时也具有性能优势。为压缩的标头写入几个位比将标头的全名和值编码并写入字节更快。
添加了初始HPack静态压缩。静态压缩非常简单:如果标头位于HPack静态表中,则编写ID来标识标头,而不是较长的名称。
动态HPack标头压缩更加复杂,但也带来了更大的收益。在动态表中跟踪响应头的名称和值,并分别为其分配一个ID。写入响应的标题后,服务器将检查表中是否包含标题名称和值。如果匹配,则写入ID。如果没有,则写入完整的标头,并将其添加到表中以进行下一个响应。动态表有最大大小,因此向其添加标题可能会以先进先出的顺序逐出其他标题。
添加了动态HPack头压缩。为了快速搜索头,动态表使用基本哈希表对头条目进行分组。为了跟踪顺序并清理除旧的标头,会维护一个链接列表。为了避免分配,已删除的条目将被合并并重新使用。
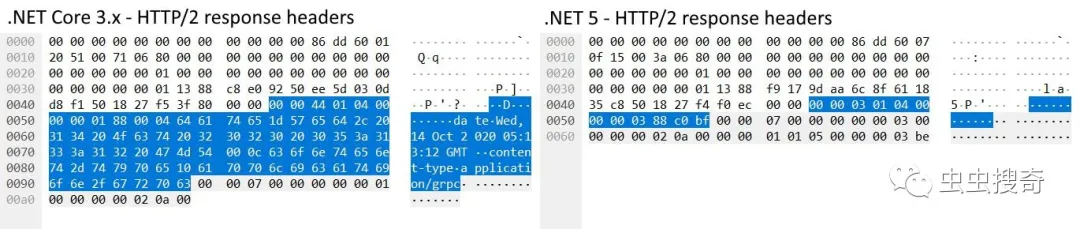
使用Wireshark抓包,可以看到示例中gRPC调用的标头压缩对响应大小的影响。.NET Core 3.x写入77 B,而.NET 5仅为12B。
Protobuf消息序列化
.NET的gRPC使用Google.Protobuf包作为消息的默认序列化程序。Protobuf是一种有效的二进制序列化格式。Google.Protobuf是为提高性能而设计的,它使用代码生成而不是反射来序列化.NET对象。可以向其中添加一些现代的.NET API和功能,以减少分配并提高效率。
Google.Protobuf最大的改进是现代.NET IO类型的支持:Span
优化对Google.Protobuf缓冲区序列化的支持。这是迄今为止最大,最复杂的变化。Protobuf读写使用添加到C#和.NET Core的许多面向性能的功能和API:
Span
stackalloc用于创建基于堆栈的数组。stackalloc是在需要较小缓冲区时避免分配的有用工具。
增加MemoryMarshal.GetReference(),Unsafe.ReadUnaligned()和Unsafe.WriteUnaligned()等低级方法,可以实现在原始类型和字节之间直接转换。
BinaryPrimitives具有用于在.NET基本类型和字节之间进行有效转换的辅助方法。例如,BinaryPrimitives.ReadUInt64读取小数字节并返回无符号的64位数字。LittleEndianBinaryPrimitive提供的方法经过了最优化,并使用了向量化。
关于现代C#和.NET的一大优点是可以在不牺牲内存安全性的情况下编写快速,高效,低级的库。在性能方面,可以极大的压榨你的服务器:
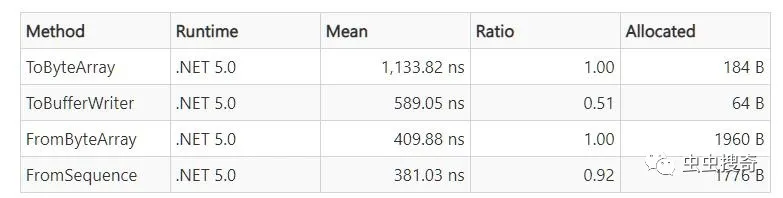
- private TestMessage _testMessage = CreateMessage();
- private ReadOnlySequence<byte> _testData = CreateData();
- private IBufferWriter<byte> _bufferWriter = CreateWriter();
- [Benchmark]
- public IMessage ToByteArray() =>
- _testMessage.ToByteArray();
- [Benchmark]
- public IMessage ToBufferWriter() =>
- _testMessage.WriteTo(_bufferWriter);
- [Benchmark]
- public IMessage FromByteArray() =>
- TestMessage.Parser.ParseFrom(CreateBytes());
- [Benchmark]
- public IMessage FromSequence() =>
- TestMessage.Parser.ParseFrom(_testData);
给Google.Protobuf添加对缓冲区序列化的支持只是第一步。要使用gRPC for .NET,需要更多工作才能利用新功能:
向Grpc.Core.Api中的gRPC序列化抽象层添加了ReadOnlySequence
API。
更新gRPC代码生成,以将Google.Protobuf中的更改粘贴到Grpc.Core.Api。
更新了.NET的gRPC,以使用Grpc.Core.Api中的新序列化抽象。这段代码是Kestrel和gRPC之间的集成。由于Kestrel的IO建立在System.IO.Pipelines之上,因此可以在序列化过程中使用其缓冲区。
最终结果是gRPC for .NET将Protobuf消息直接序列化到Kestrel的请求和响应缓冲区。中间数组分配和字节副本已从gRPC消息序列化中删除。
总结
性能是.NET和gRPC的基本功能,随着云应用崛起,性能变得越来越重要。较低的延迟和较高的吞吐量意味着更少的服务器。高性能的应用可以节省金钱,减少能耗和构建绿色应用程序的机会。
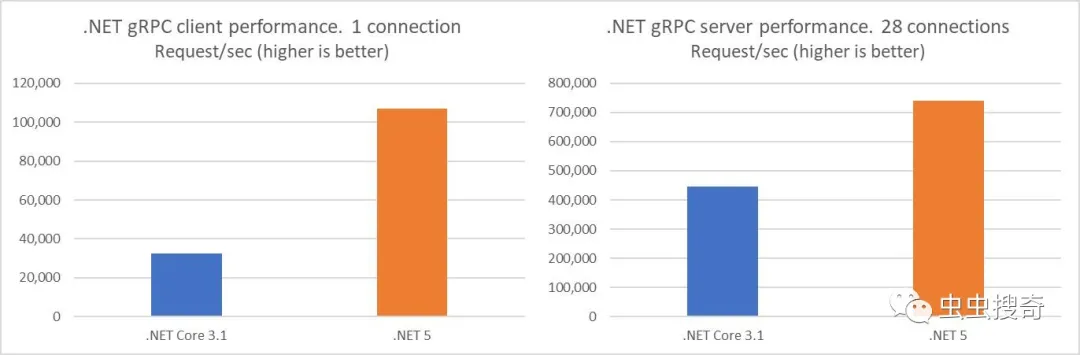
gRPC,Protobuf和.NET 5进行大量的尝试和更改,用来提高性能。基准测试表明,gRPC服务器RPS提高了60%,gRPC客户端RPS提高了230%。