作为一名服务端工程师,工作中你肯定和 Redis 打过交道。Redis 为什么快,这点想必你也知道,至少为了面试也做过准备。很多人知道 Redis 快仅仅因为它是基于内存实现的,对于其他原因倒是模棱两可。
图片来自 Pexels
那么今天就和我一起看看:
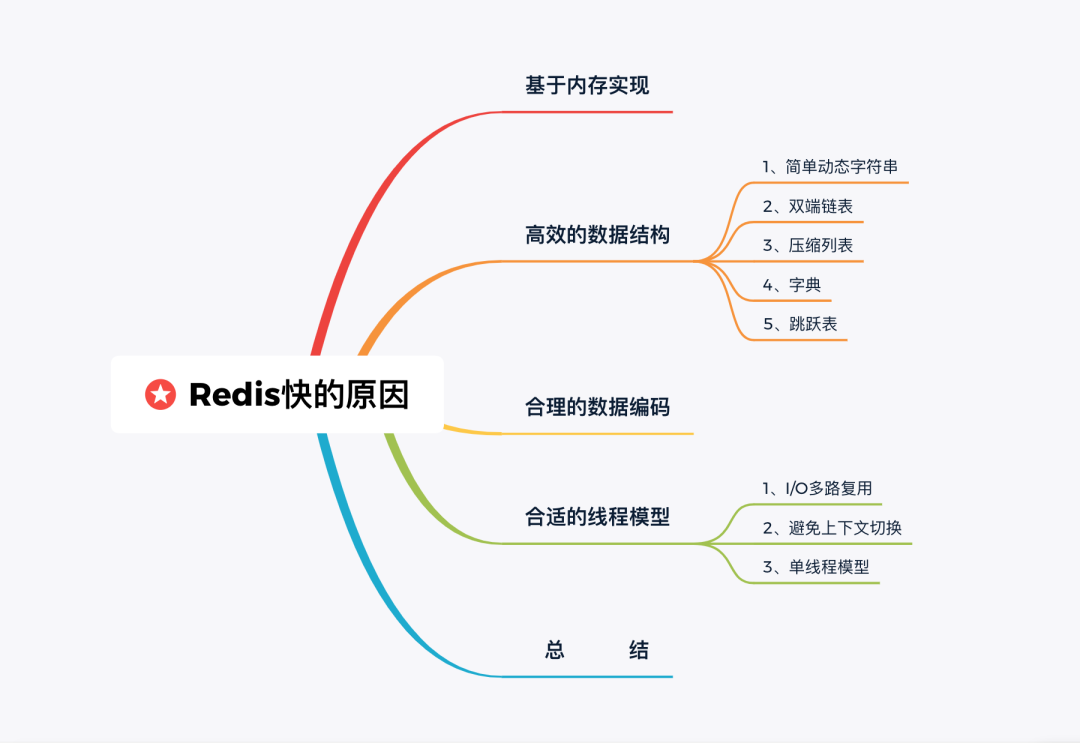
思维导图
基于内存实现
这点在一开始就提到过了,这里再简单说说。
Redis 是基于内存的数据库,那不可避免的就要与磁盘数据库做对比。对于磁盘数据库来说,是需要将数据读取到内存里的,这个过程会受到磁盘 I/O 的限制。
而对于内存数据库来说,本身数据就存在于内存里,也就没有了这方面的开销。
高效的数据结构
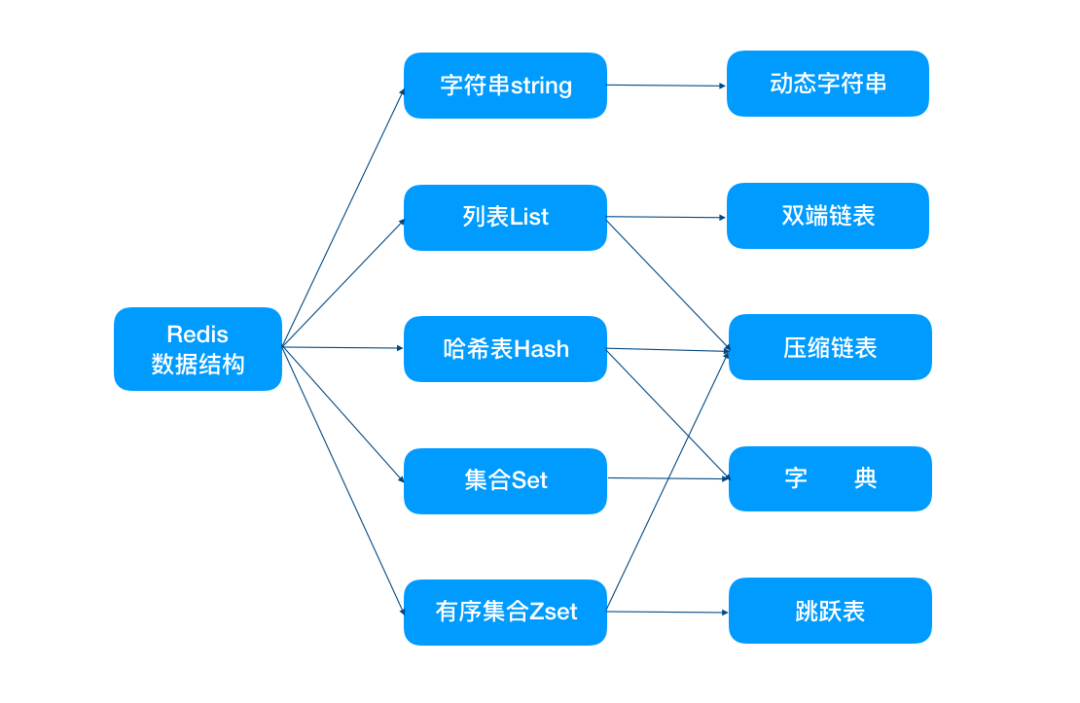
Redis 中有多种数据类型,每种数据类型的底层都由一种或多种数据结构来支持。
正是因为有了这些数据结构,Redis 在存储与读取上的速度才不受阻碍。这些数据结构有什么特别的地方,各位看官接着往下看:
简单动态字符串
这个名词可能你不熟悉,换成 SDS 肯定就知道了。这是用来处理字符串的。了解 C 语言的都知道,它是有处理字符串方法的。
而 Redis 就是 C 语言实现的,那为什么还要重复造轮子?我们从以下几点来看:
①字符串长度处理
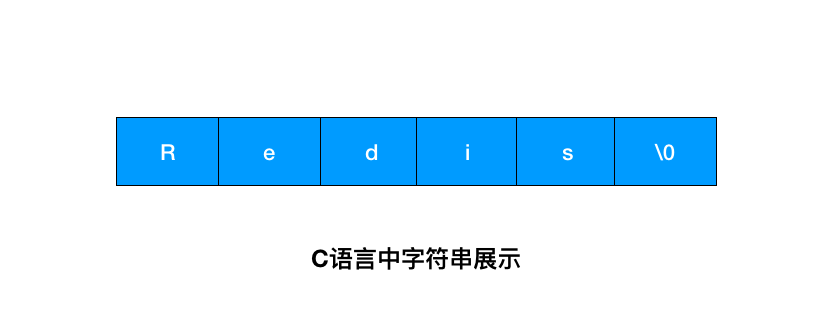
这个图是字符串在 C 语言中的存储方式,想要获取 Redis 的长度,需要从头开始遍历,直到遇到 '\0' 为止。
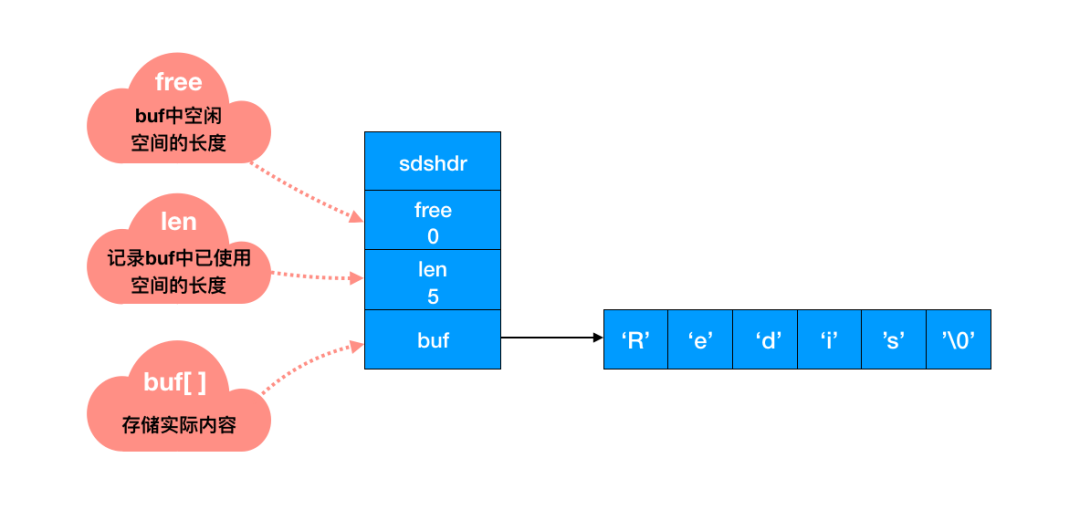
Redis 中怎么操作呢?用一个 len 字段记录当前字符串的长度。想要获取长度只需要获取 len 字段即可。
你看,差距不言自明。前者遍历的时间复杂度为 O(n),Redis 中 O(1) 就能拿到,速度明显提升。
②内存重新分配
C 语言中涉及到修改字符串的时候会重新分配内存。修改地越频繁,内存分配也就越频繁。而内存分配是会消耗性能的,那么性能下降在所难免。
而 Redis 中会涉及到字符串频繁的修改操作,这种内存分配方式显然就不适合了。
于是 SDS 实现了两种优化策略:
空间预分配:对 SDS 修改及空间扩充时,除了分配所必须的空间外,还会额外分配未使用的空间。
具体分配规则是这样的:SDS 修改后,len 长度小于 1M,那么将会额外分配与 len 相同长度的未使用空间。如果修改后长度大于 1M,那么将分配 1M 的使用空间。
惰性空间释放:当然,有空间分配对应的就有空间释放。
SDS 缩短时,并不会回收多余的内存空间,而是使用 free 字段将多出来的空间记录下来。如果后续有变更操作,直接使用 free 中记录的空间,减少了内存的分配。
③二进制安全
你已经知道了 Redis 可以存储各种数据类型,那么二进制数据肯定也不例外。但二进制数据并不是规则的字符串格式,可能会包含一些特殊的字符,比如 '\0' 等。
前面我们提到过,C 中字符串遇到 '\0' 会结束,那 '\0' 之后的数据就读取不上了。但在 SDS 中,是根据 len 长度来判断字符串结束的。
看,二进制安全的问题就解决了。
双端链表
列表 List 更多是被当作队列或栈来使用的。队列和栈的特性一个先进先出,一个先进后出。双端链表很好的支持了这些特性。
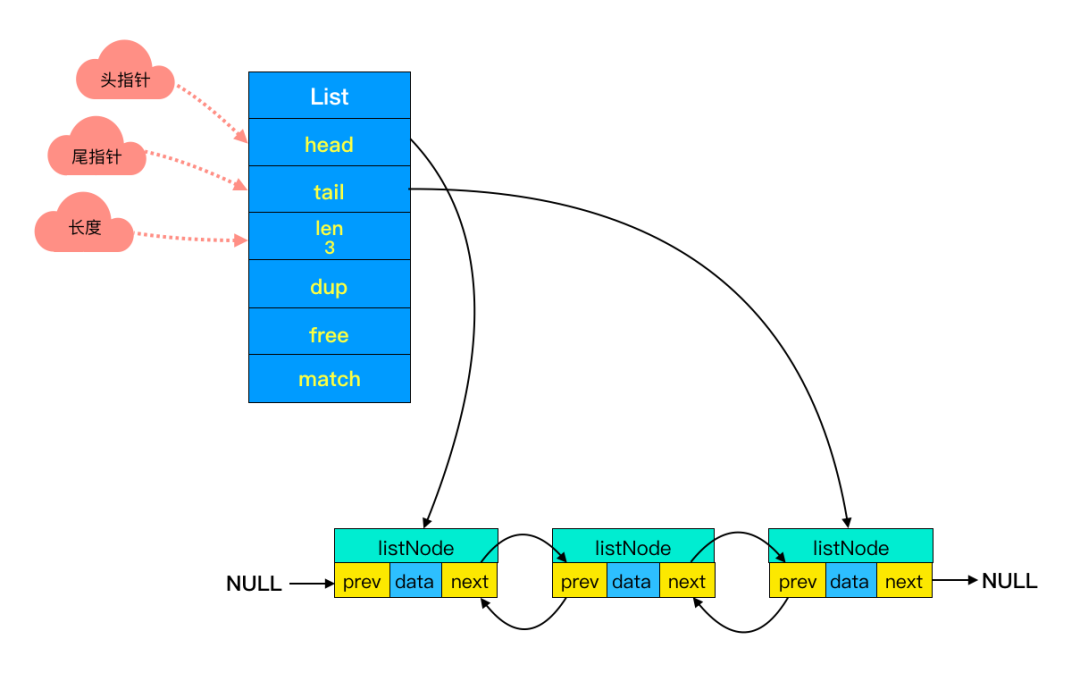
双端链表
①前后节点
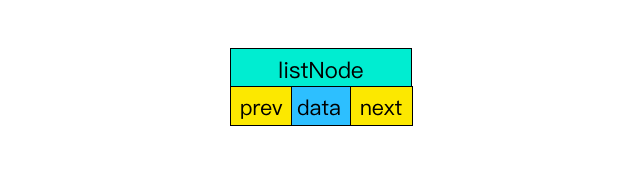
链表里每个节点都带有两个指针,prev 指向前节点,next 指向后节点。这样在时间复杂度为 O(1) 内就能获取到前后节点。
②头尾节点
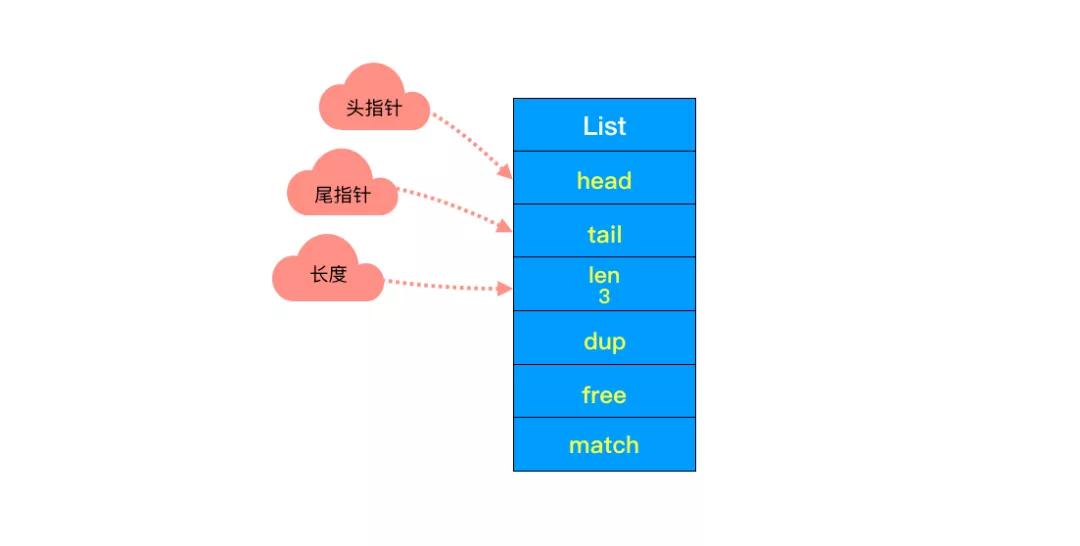
你可能注意到了,头节点里有 head 和 tail 两个参数,分别指向头节点和尾节点。
这样的设计能够对双端节点的处理时间复杂度降至 O(1) ,对于队列和栈来说再适合不过。同时链表迭代时从两端都可以进行。
③链表长度
头节点里同时还有一个参数 len,和上边提到的 SDS 里类似,这里是用来记录链表长度的。
因此获取链表长度时不用再遍历整个链表,直接拿到 len 值就可以了,这个时间复杂度是 O(1)。
你看,这些特性都降低了 List 使用时的时间开销。
压缩列表
双端链表我们已经熟悉了。不知道你有没有注意到一个问题:如果在一个链表节点中存储一个小数据,比如一个字节。那么对应的就要保存头节点,前后指针等额外的数据。
这样就浪费了空间,同时由于反复申请与释放也容易导致内存碎片化。这样内存的使用效率就太低了。
于是,压缩列表上场了!
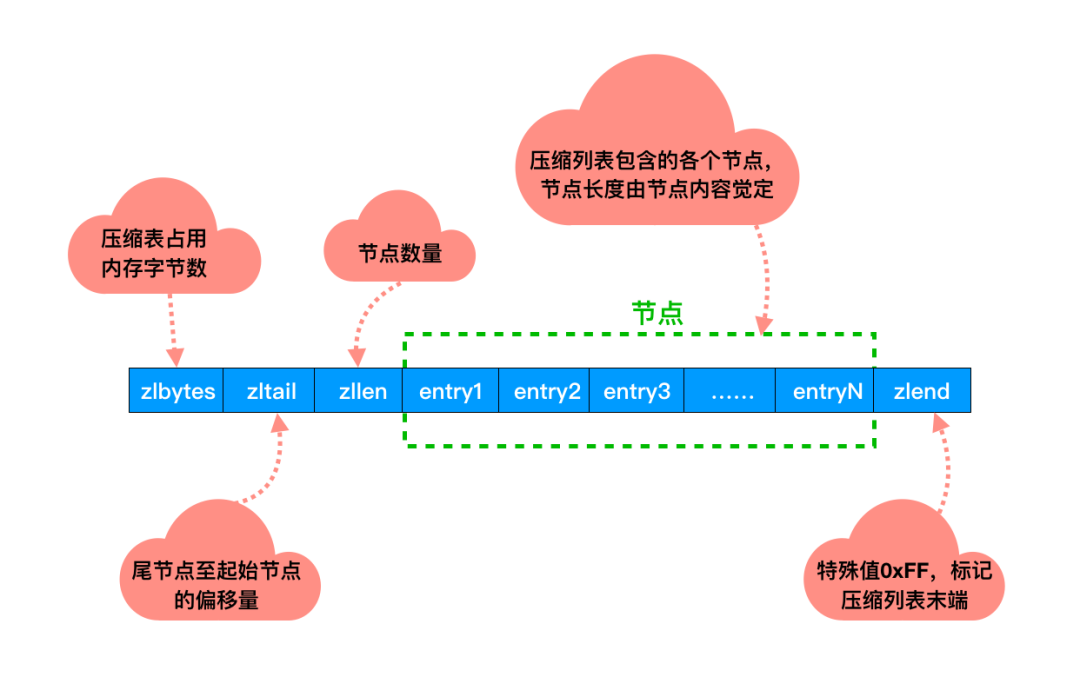
它是经过特殊编码,专门为了提升内存使用效率设计的。所有的操作都是通过指针与解码出来的偏移量进行的。
并且压缩列表的内存是连续分配的,遍历的速度很快。
字典
Redis 作为 K-V 型数据库,所有的键值都是用字典来存储的。
日常学习中使用的字典你应该不会陌生,想查找某个词通过某个字就可以直接定位到,速度非常快。
这里所说的字典原理上是一样的,通过某个 key 可以直接获取到对应的 value。
字典又称为哈希表,这点没什么可说的。哈希表的特性大家都很清楚,能够在 O(1) 时间复杂度内取出和插入关联的值。
跳跃表
作为 Redis 中特有的数据结构-跳跃表,其在链表的基础上增加了多级索引来提升查找效率。
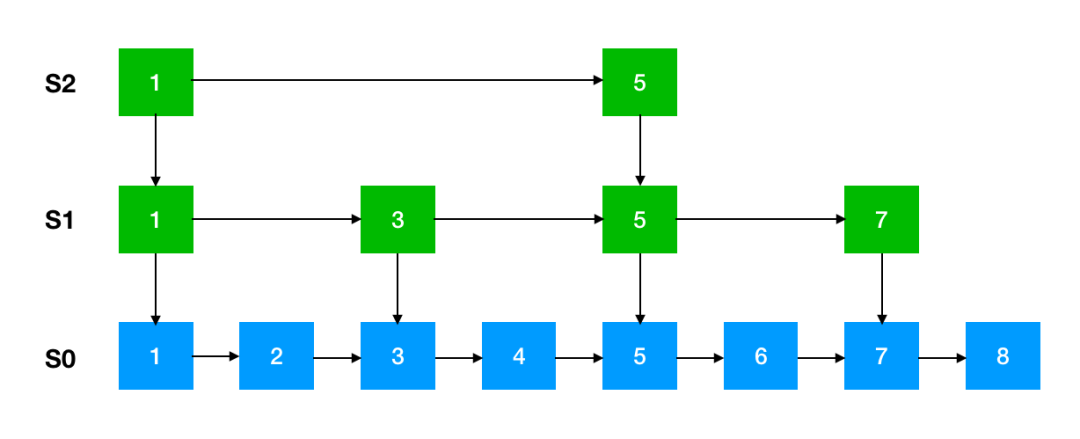
这是跳跃表的简单原理图,每一层都有一条有序的链表,最底层的链表包含了所有的元素。这样跳跃表就可以支持在 O(logN) 的时间复杂度里查找到对应的节点。
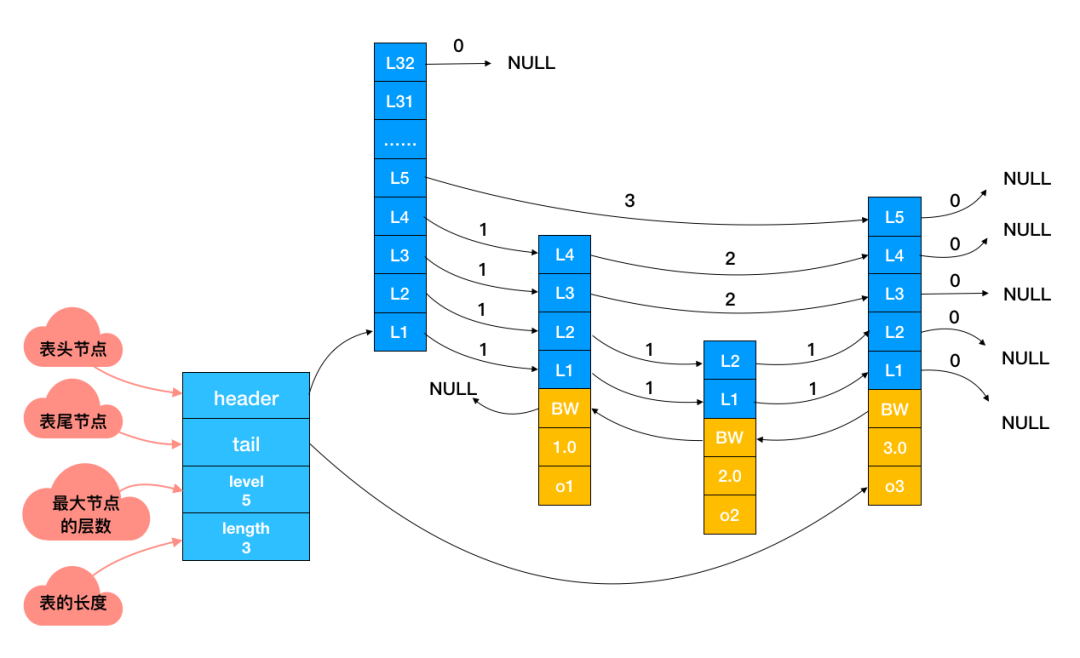
下面这张是跳表真实的存储结构,和其它数据结构一样,都在头节点里记录了相应的信息,减少了一些不必要的系统开销。
合理的数据编码
对于每一种数据类型来说,底层的支持可能是多种数据结构,什么时候使用哪种数据结构,这就涉及到了编码转化的问题。
那我们就来看看,不同的数据类型是如何进行编码转化的:
- String:存储数字的话,采用 int 类型的编码,如果是非数字的话,采用 raw 编码。
- List:字符串长度及元素个数小于一定范围使用 ziplist 编码,任意条件不满足,则转化为 linkedlist 编码。
- Hash:hash 对象保存的键值对内的键和值字符串长度小于一定值及键值对。
- Set:保存元素为整数及元素个数小于一定范围使用 intset 编码,任意条件不满足,则使用 hashtable 编码。
- Zset:zset 对象中保存的元素个数小于及成员长度小于一定值使用 ziplist 编码,任意条件不满足,则使用 skiplist 编码。
合适的线程模型
Redis 快的原因还有一个是因为使用了合适的线程模型:
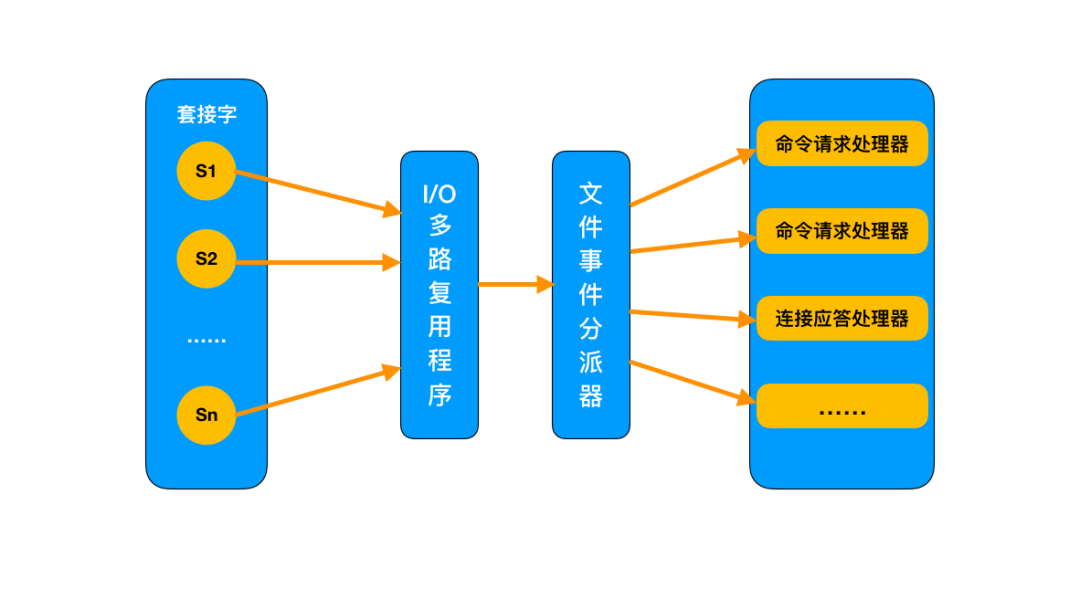
I/O 多路复用模型
I/O :网络 I/O;多路:多个 TCP 连接;复用:共用一个线程或进程。
生产环境中的使用,通常是多个客户端连接 Redis,然后各自发送命令至 Redis 服务器,最后服务端处理这些请求返回结果。
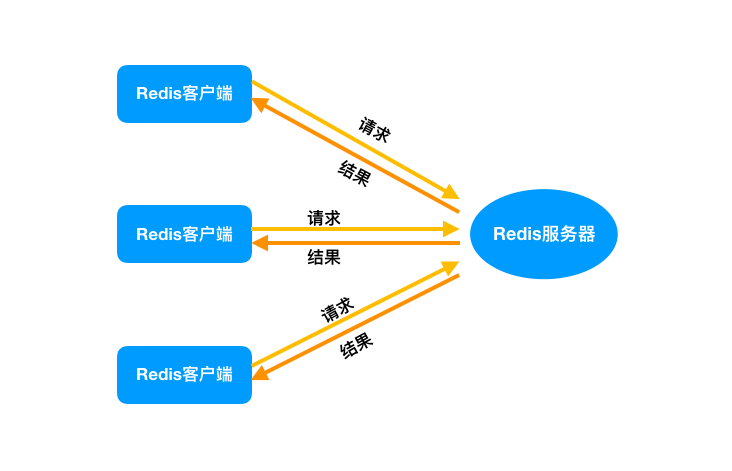
应对大量的请求,Redis 中使用 I/O 多路复用程序同时监听多个套接字,并将这些事件推送到一个队列里,然后逐个被执行。最终将结果返回给客户端。
避免上下文切换
你一定听说过,Redis 是单线程的。那么单线程的 Redis 为什么会快呢?
因为多线程在执行过程中需要进行 CPU 的上下文切换,这个操作比较耗时。
Redis 又是基于内存实现的,对于内存来说,没有上下文切换效率就是最高的。多次读写都在一个CPU 上,对于内存来说就是最佳方案。
单线程模型
顺便提一下,为什么 Redis 是单线程的。
Redis 中使用了 Reactor 单线程模型,你可能对它并不熟悉。没关系,只需要大概了解一下即可。
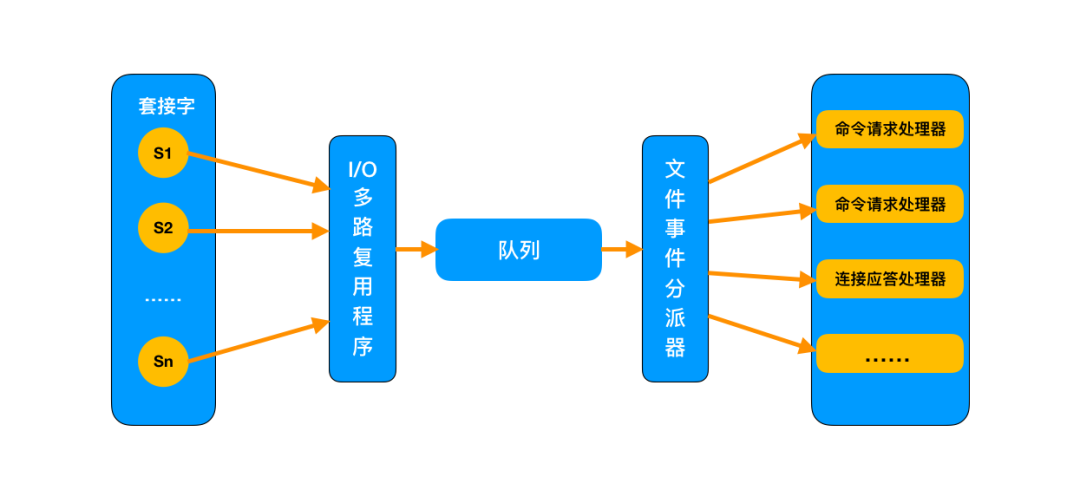
这张图里,接收到用户的请求后,全部推送到一个队列里,然后交给文件事件分派器,而它是单线程的工作方式。Redis 又是基于它工作的,所以说 Redis 是单线程的。
Redis 单线程与多线程
Redis是单线程的,这话搁以前,是横着走的,谁都知道的真理。现在不一样,Redis 变了。再说这句话,多少得有质疑的语气来跟你辩驳一番。意志不坚定的,可能就缴械投降,顺着别人走了。
到底是什么样的,各位看官请跟小莱一起往下看:
Reactor 模式
反应器模式,你可能不太认识,如果看完上文的话应该会有点印象。涉及到 Redis 线程它是一个绕不过去的话题。
①传统阻塞 IO 模型
在讲反应器模式前,这里有必要提一下传统阻塞 IO 模型的处理方式。
在传统阻塞 IO 模型中,由一个独立的 Acceptor 线程来监听客户端的连接,每当有客户端请求过来时,它就会为客户端分配一个新的线程来进行处理。
当同时有多个请求过来,服务端对应的就会分配相应数量的线程。这就会导致 CPU 频繁切换,浪费资源。
有的连接请求过来不做任何事情,但服务端还会分配对应的线程,这样就会造成不必要的线程开销。
这就好比你去餐厅吃饭,你拿着菜单看了半天发现真他娘的贵,然后你就走人了。
这段时间等你点菜的服务员就相当于一个对应的线程,你要点菜可以看作一个连接请求。
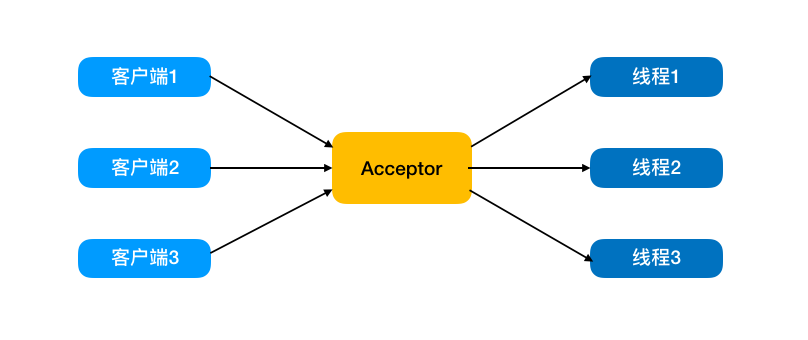
同时,每次建立连接后,当线程调用读写方法时,线程会被阻塞,直到有数据可读可写,在此期间线程不能做其它事情。
还是上边餐厅吃饭的例子,你出去转了一圈发现还是这家性价比最高。回到这家餐厅又拿着菜单看了半天,服务员也在旁边等你点完菜为止。
这个过程中服务员什么也不能做,只能这么干等着,这个过程相当于阻塞。
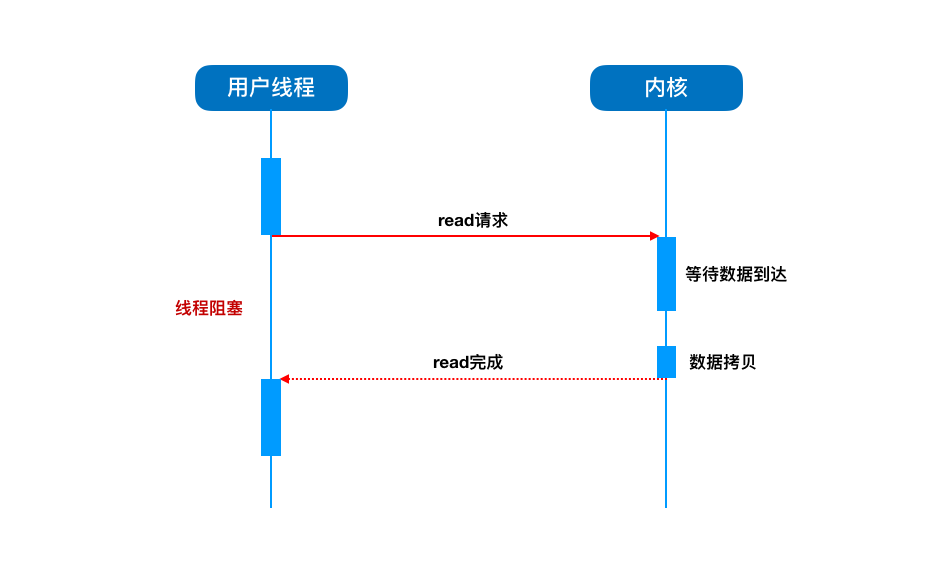
你看这样的方式,每来一个请求就要分配一个线程,并且还得阻塞地等线程处理完。
有的请求还只是过来连接下,什么操作也不干,还得为它分配一个线程,对服务器资源要求那得多高啊。
遇到高并发场景,不敢想象。对于连接数目比较小的的固定架构倒是可以考虑。
②伪异步 IO 模型
你可能了解过一种通过线程池优化的解决方案,采用线程池和任务队列的方式。这种被称作伪异步 IO 模型。
当有客户端接入时,将客户端的请求封装成一个 task 投递到后端线程池中来处理。线程池维护一个消息队列和多个活跃线程,对消息队列中的任务进行处理。
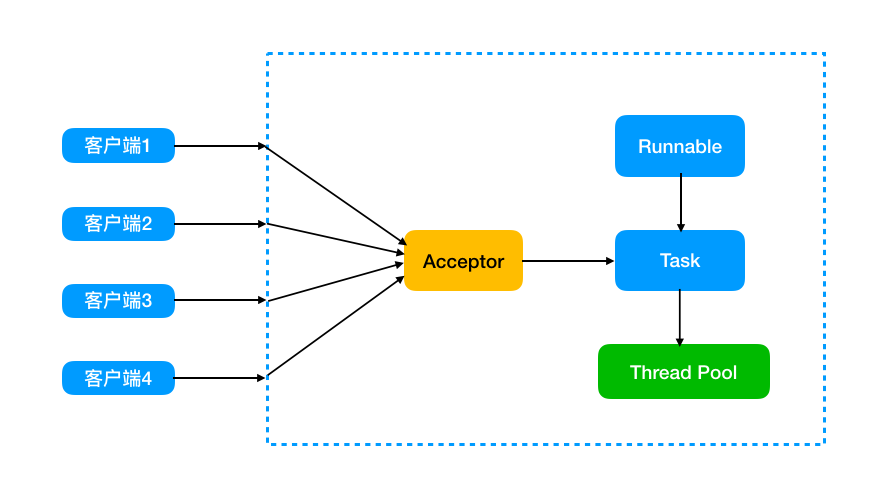
这种解决方案,避免了为每个请求创建一个线程导致的线程资源耗尽问题。但是底层仍然是同步阻塞模型。
如果线程池内的所有线程都阻塞了,那么对于更多请求就无法响应了。因此这种模式会限制最大连接数,并不能从根本上解决问题。
我们继续用上边的餐厅来举例,餐厅老板在经营了一段时间后,顾客多了起来,原本店里的 5 个服务员一对一服务的话根本对付不过来。
于是老板采用 5 个人线程池的方式。服务员服务完一个客人后立刻去服务另一个。
这时问题出现了,有的客人点菜特别慢,服务员就得等待很长时间,直到客人点完为止。
如果 5 个客人都点的特别慢的话,这 5 个服务员就得一直等下去,就会导致其余的顾客没有人服务的状态。这就是我们上边所说的线程池所有线程都被阻塞的情况。
那么这种问题该如何解决呢?别急, Reactor 模式就要出场了。
③Reactor 设计模式
Reactor 模式的基本设计思想是基于 I/O 复用模型来实现的。
这里说下 I/O 复用模型。和传统 IO 多线程阻塞不同,I/O 复用模型中多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象等待。
当某个连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
什么意思呢?餐厅老板也发现了顾客点餐慢的问题,于是他采用了一种大胆的方式,只留了一个服务员。
当客人点餐的时候,这个服务员就去招待别的客人,客人点好餐后直接喊服务员来进行服务。
这里的顾客和服务员可以分别看作多个连接和一个线程。服务员阻塞在一个顾客那里,当有别的顾客点好餐后,她就立刻去服务其他的顾客。
了解了 Reactor 的设计思想后,我们再来看下今天的主角单 Reactor 单线程的实现方案:
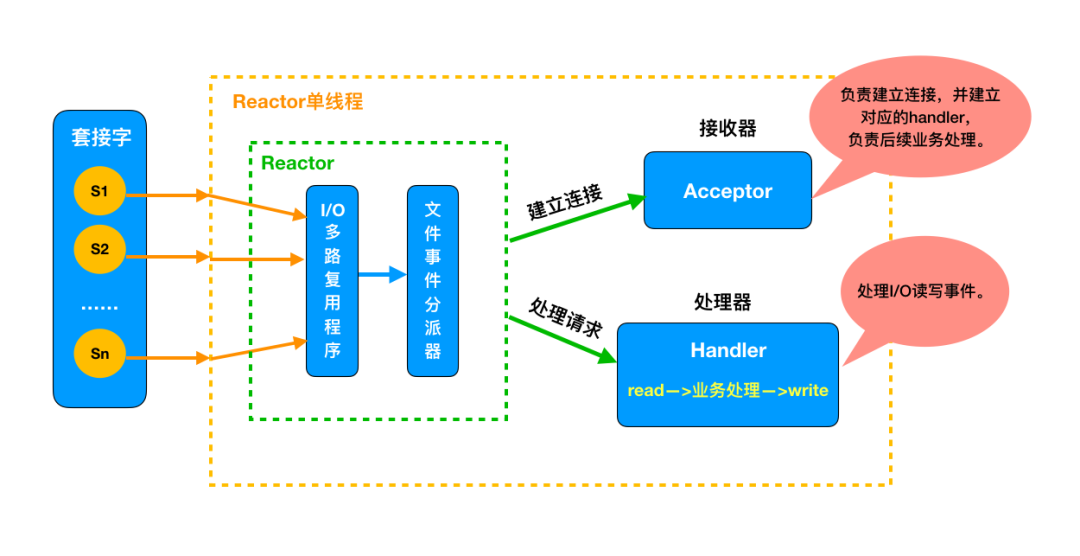
Reactor 通过 I/O 复用程序监控客户端请求事件,收到事件后通过任务分派器进行分发。
针对建立连接请求事件,通过 Acceptor 处理,并建立对应的 handler 负责后续业务处理。
针对非连接事件,Reactor 会调用对应的 handler 完成 read→业务处理→write 处理流程,并将结果返回给客户端。
整个过程都在一个线程里完成:
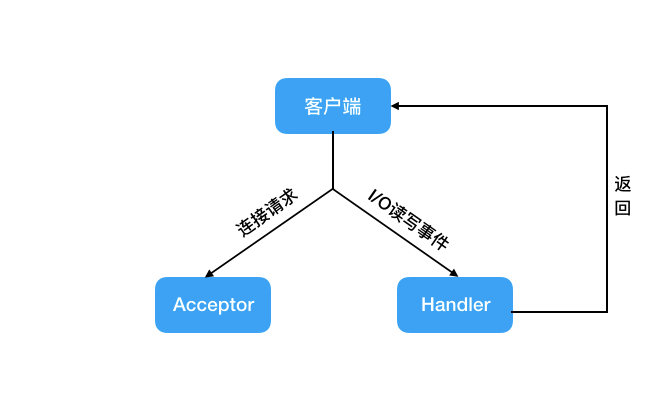
单线程时代
了解了 Reactor 模式后,你可能会有一个疑问,这个和我们今天的主题有什么关系呢。可能你不知道的是,Redis 是基于 Reactor 单线程模式来实现的。
IO多路复用程序接收到用户的请求后,全部推送到一个队列里,交给文件分派器。
对于后续的操作,和在 Reactor 单线程实现方案里看到的一样,整个过程都在一个线程里完成,因此 Redis 被称为是单线程的操作。
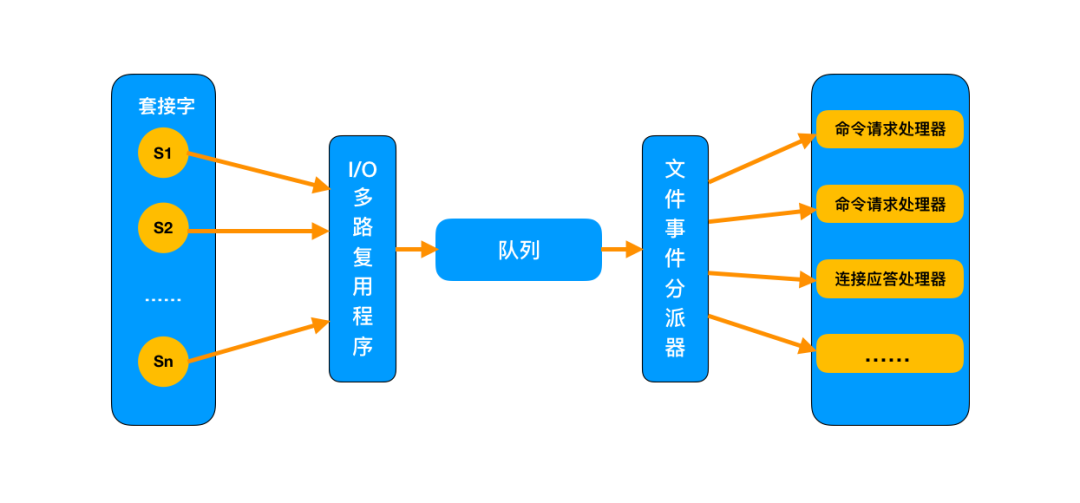
对于单线程的 Redis 来说,基于内存,且命令操作时间复杂度低,因此读写速率是非常快的。
多线程时代
Redis6 版本中引入了多线程。上边已经提到过 Redis 单线程处理有着很快的速度,那为什么还要引入多线程呢?单线程的瓶颈在什么地方?
我们先来看第二个问题,在 Redis 中,单线程的性能瓶颈主要在网络IO操作上。
也就是在读写网络 read/write 系统调用执行期间会占用大部分 CPU 时间。如果你要对一些大的键值对进行删除操作的话,在短时间内是删不完的,那么对于单线程来说就会阻塞后边的操作。
回想下上边讲得 Reactor 模式中单线程的处理方式。针对非连接事件,Reactor 会调用对应的 handler 完成 read→业务处理→write 处理流程,也就是说这一步会造成性能上的瓶颈。
Redis 在设计上采用将网络数据读写和协议解析通过多线程的方式来处理,对于命令执行来说,仍然使用单线程操作。
总结
基于内存实现:
- 数据都存储在内存里,减少了一些不必要的 I/O 操作,操作速率很快。
高效的数据结构:
- 底层多种数据结构支持不同的数据类型,支持 Redis 存储不同的数据。
- 不同数据结构的设计,使得数据存储时间复杂度降到最低。
合理的数据编码:
- 根据字符串的长度及元素的个数适配不同的编码格式。
合适的线程模型:
- I/O 多路复用模型同时监听客户端连接;
- 单线程在执行过程中不需要进行上下文切换,减少了耗时。
Reactor 模式:
- 传统阻塞 IO 模型客户端与服务端线程 1:1 分配,不利于进行扩展。
- 伪异步 IO 模型采用线程池方式,但是底层仍然使用同步阻塞方式,限制了最大连接数。
- Reactor 通过 I/O 复用程序监控客户端请求事件,通过任务分派器进行分发。
单线程时代:
- 基于 Reactor 单线程模式实现,通过 IO 多路复用程序接收到用户的请求后,全部推送到一个队列里,交给文件分派器进行处理。
多线程时代:
- 单线程性能瓶颈主要在网络 IO 上。
- 将网络数据读写和协议解析通过多线程的方式来处理 ,对于命令执行来说,仍然使用单线程操作。
作者:小莱,一枚后端工程师
编辑:陶家龙
出处:转载自公众号IT界农民工(ID:kejishuqian)