【51CTO.com快译】自2017年推出以来,Facebook的机器学习框架PyTorch已得到很好的利用,应用广泛,从支持Elon Musk的自动驾驶汽车到驱动机器人耕种项目,不一而足。
现在制药公司阿斯利康(AstraZeneca)透露了其内部工程师团队如何利用PyTorch,同样重要的是简化和加快药物发现。
阿斯利康的技术将PyTorch与微软Azure机器学习相结合,可以梳理大量数据,对于药物、疾病、基因、蛋白质或分子之间的复杂关系有一番新的了解。
这番了解可用于馈送给算法,算法进而可以为某种疾病推荐许多药物靶标,供科学家在实验室进行测试。
这种方法便于在药物发现之类的领域取得巨大进展,迄今为止,该领域一直基于昂贵且耗时的反复试验方法。
为了研制出对付某种疾病的新药,科学家通常要在实验室测试不同的蛋白质设计和组合,直至找到可行的解决方案,这就是为什么从药物设计到准备上市需要10到15年的时间。另一方面,阿斯利康的算法可以更快地确定科学家应针对某种疾病寻找的十大药物靶标。
将自动化应用于药物发现尤其有用,因为科学家可以访问以帮助开展研究的数据量每年急剧增长。分析每天越来越庞大的数据库以了解它们如何为药物发现提供信息,实际上成了一项超人才能完成的任务。
阿斯利康的机器学习工程师Gavin Edwards告诉ZDNet:“每年,可供研究人员使用的科学信息和数据的绝对量在增长。通过利用AI和机器学习工具(比如PyTorch和Azure),我们就能迅速提取、整合和解读来自多个来源的信息,旨在比我们手动分析这些数据更迅速地得到更准确的科学结论。”
许多可用数据是非结构化文本,这时候PyTorch有了用武之地。Facebook开发的这个软件包基于Python编程语言,是一种开源机器学习库,尤其适用于在计算机视觉和自然语言处理(NLP)等领域处理密集数据科学任务的开发人员。
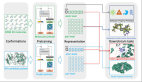
阿斯利康的NLP团队使用PyTorch来定义和训练生物医学文本挖掘算法,这种算法可以遍历数据,查找模式和趋势,并最终确定可用信息的结构。
然后数据馈入到知识图中,知识图可以智能地将零星的信息连接起来,以便可以将每个数据点置于上下文中来研究。图用起来就像信息网络,不仅能反映每个数据的属性(基因、蛋白质、疾病和化合物),还能反映不同类别之间的关系。
换句话说,知识图全面地组织所有可用的科学数据。阿斯利康的工程师随后利用微软Azure机器学习的计算功能,使用知识图来训练向科学家推荐新药物靶标的算法。
Edwards说:“我们将公共领域的研究和内部研究结合到对复杂信息轻松编码的图中。通过在此基础上使用机器学习,我们可以训练机器学习模型,这些模型可以推荐新颖的药物靶标,并有助于为管道决策提供信息。”
对于在实验室不懈地尝试新药物设计的科学家而言,用于药物发现的推荐算法无疑听起来可以节省大量时间。但是Edwards及其团队还希望,他们在创建的知识图可帮助研究人员找到新的联系,探索新的路径,并测试未经证实的理论,又不浪费太多时间。
可以缩小数点知识图以便详细查看问题的某个方面,也可以扩展知识图以便提供跨不同研究分支的更广泛视图。因此,研究人员就能轻松获得未利用的信息,这些信息可以为其项目带来更多价值。
Edwards说:“我们的知识图使研究人员可以提出有关基因、疾病、药物和安全信息等方面的关键问题,帮助识别药物靶标并确定优先级。而且,随着我们的数据和知识越来越丰富,我们的图会随之庞大,这意味着每个新试验都将得益于以前学到的知识。”
对于Edwards来说,这项技术的应用范围可能很大。在全球疫情持续不断的情况下,这无疑是个好消息。
原文标题:AstraZeneca is using PyTorch-powered algorithms to discover new drugs,作者:Daphne Leprince-Ringuet
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】