













在日常工作中,发现 MySQL 的状态不太对劲的时候,一般都会看看监控指标,很多时候会看到熟悉的一幕:CPU 使用率又爆了。本文将给大家介绍 MySQL 和 CPU 之间的关系,对此有一定的了解之后可以更准确的判断出问题的原因,也能够提前发现一些引发 CPU 问题的隐患。
怎么看懂CPU使用率
以 Linux 的 top 命令为例,效果如下:

Top 命令
在 %CPU 这一列就展示了 CPU 的使用情况,百分比指代的是总体上占用的时间百分比:
- %us:表示用户进程的 CPU 使用时间(没有通过 nice 调度)
- %sy:表示系统进程的 CPU 使用时间,主要是内核使用。
- %ni:表示用户进程中,通过 CPU 调度(nice)过的使用时间。
- %id:空闲的 CPU 时间
- %wa:CPU 运行时在等待 IO 的时间
- %hi:CPU 处理硬中断花费的时间
- %si:CPU 处理软中断花费的时间
- %st:被虚拟机偷走的 CPU 时间
通常情况下,我们讨论的 CPU 使用率过高,指的是 %us 这个指标,监控里面的 CPU 使用率通常也是这个值(也有用其他的方法计算出来的,不过简单起见,不考虑其他的情况 )。其他几个指标过高也代表出 MySQL 的状态异常,简单起见,这里主要还是指 %us 过高的场景。
MySQL和线程
MySQL 是单进程多线程的结构,意味着独占的 MySQL 服务器里面,只能用 top 命令看到一行数据。
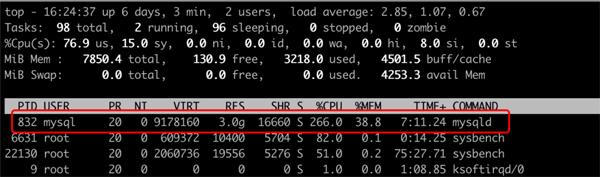
TOP 命令效果
这里能看到的是 MySQL 的进程 ID,如果要看到线程的情况,需要用top -H
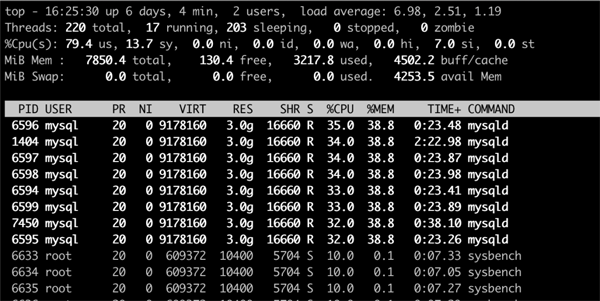
TOP 命令效果
在这里能看到的是 MySQL 各个线程的 ID,可以看到 MySQL 在启动之后,会创建非常多的内部线程来工作。
这些内部线程包括 MySQL 自己用来刷脏,读写数据等操作的系统线程,也包括处理用户 SQL 的线程,姑且叫做用户线程吧。用户线程有一个特殊的地方:程序端发送到 MySQL 端的 SQL,只会由一个用户线程来执行(one-thread-per-connection),所以 MySQL 在处理复杂查询的时候,会出现“一核有难,多核围观”的尴尬现象。
参考 %us 的定义,对于 Linux 系统来说,MySQL 进程和它启动的所有线程都不算内核进程,因此 MySQL 的系统线程和用户线程在繁忙的时候,都会体现在 CPU 使用率的 %us 指标上。
什么时候CPU会100%
MySQL 干什么的时候,CPU 会 100%?从前文的分析来看,MySQL 主要是两类线程占用 CPU:系统线程和用户线程。因此 MySQL 独占的服务器上,只需要留意一下这两类线程的情况,就能 Cover 住绝大部分的问题场景。
系统线程
在实际的环境中,系统线程遇到问题的情况会比较少,一般来说,多个系统线程很少会同时跑满,只要服务器的可用核心数大于等于 4 的话,一般也不会遇到 CPU 100%,当然有一些 bug 可能会有影响,比如这个:
MySQL BUG
虽然情况比较少,但是在面对问题的常规排查过程中,系统线程的问题也是需要关注的。
用户线程
提到用户线程繁忙,很多时候肯定会第一时间凭经验想到慢查询。确实 90% 以上的时候都是“慢查询”引起的,不过作为方法论,还是要根据分析再去得出结论的~
参考 us% 的定义,是指用户线程占用 CPU 的时间多少,这代表着用户线程占用了大量的时间。
一方面是在进行长时间的计算,例如:order by,group by,临时表,join 等。这一类问题可能是查询效率不高,导致单个 SQL 语句长时间占用 CPU 时间,也有可能是单纯的数据量比较多,导致计算量巨大。另一方面是单纯的 QPS 压力高,所以 CPU 的时间被用满了,比如 4 核的服务器用来支撑 20k 到 30k 的点查询,每个 SQL 占用的 CPU 时间并不多,但是因为整体的 QPS 很高,所以 CPU 的时间被占满了。
问题的定位
分析完之后,就要开始实战了,这里根据前文的分析给出一些经典的 CPU 100% 场景,并给出简要的定位方法作为参考。
PS:系统线程的 bug 的场景 skip,以后有机会再作为详细的案例来分析。
慢查询
在 CPU 100% 这个问题已经发生之后,真实的慢查询和因为 CPU 100% 导致被影响的普通查询会混在一起,难以直观的看 processlist 或者 slowlog 来发现元凶,这时候就需要一些比较明确的特征来进行甄别。
从前文的简单分析可以看出来,查询效率不高的慢查询通常有以下几种情况:
- 全表扫描:Handler_read_rnd_next 这个值会大幅度突增,且这一类查询在 slowlog 中 row_examined 的值也会非常高。
- 索引效率不高,索引选错了:Handler_read_next 这个值会大幅度的突增,不过要注意这种情况也有可能是业务量突增引起的,需要结合 QPS/TPS 一起看。这一类查询在 slowlog 中找起来会比较麻烦,row_examined 的值一般在故障前后会有比较明显的不同,或者是不合理的偏高。
- 比如数据倾斜的场景,一个小范围的 range 查询在某个特定的范围内 row_examined 非常高,而其他的范围时 row_examined 比较低,那么就可能是这个索引效率不高。
- 排序比较多:order by,group by 这一类查询通常不太好从 Handler 的指标直接判断,如果没有索引或者索引不好,导致排序操作没有消除的话,那么在 processlist 和 slowlog 通常能看到这一类查询语句出现的比较多。
当然,不想详细的分析 MySQL 指标或者是情况比较紧急的话,可以直接在 slowlog 里面用 rows_sent 和 row_examined 做个简单的除法,比如 row_examined/rows_sent > 1000 的都可以拿出来作为“嫌疑人”处理。这类问题一般在索引方面做好优化就能解决。
PS:1000 只是个经验值,具体要根据实际业务情况来定。
计算量大
这一类问题通常是因为数据量比较大,即使索引没什么问题,执行计划也 OK,也会导致 CPU 100%,而且结合 MySQL one-thread-per-connection 的特性,并不需要太多的并发就能把 CPU 使用率跑满。这一类查询其实是是比较好查的,因为执行时间一般会比较久,在 processlist 里面就会非常显眼,反而是 slowlog 里面可能找不到,因为没有执行完的语句是不会记录的。
这一类问题一般来说有三种比较常规的解决方案:
- 读写分离,把这一类查询放到平时业务不怎么用的只读从库去。
- 在程序段拆分 SQL,把单个大查询拆分成多个小查询。
- 使用 HBASE,Spark 等 OLAP 的方案来支持。
高 QPS
这一类问题单纯的就是硬件资源的瓶颈,不论是 row_examined/rows_sent 的比值,还是 SQL 的索引、执行计划,或者是 SQL 的计算量都不会有什么明显问题,只是 QPS 指标会比较高,而且 processlist 里面可能什么内容都看不到,例如:
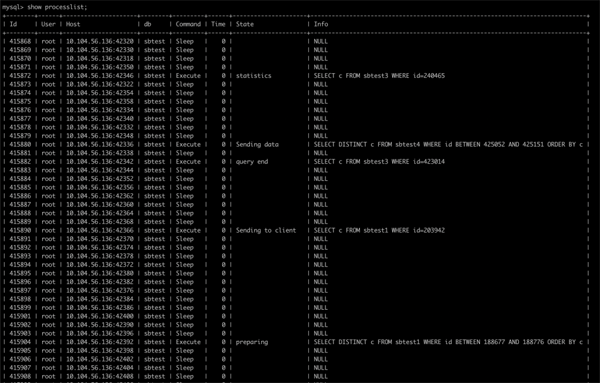
processlist
总结
实际上 CPU 100% 的问题其实不仅仅是单纯的 %us,还会有 %io,%sys 等,这些会涉及到 MySQL 与 Linux 相关联的一部分内容,展开来就会比较多了。本文仅从 %us 出发尝试梳理一下排查&定位的思路和方法,在分析 %io,%sys 等方面的问题时,也可以用类似的思路,从这些指标的意义开始,结合 MySQL 的一些特性或者特点,逐步理清楚表象背后的原因。

















