我妹(亲妹)今年上大学了,学的计算机编程,没成想,她的一名老师竟然是我的读者,我妹是又惊喜又恐慌,惊喜是她哥我的读者群体还挺广泛的嘛,恐慌的是万一学不好岂不是很丢他哥的脸?但我相信她一定能学好!
“二哥,上一节提到了 Java 变量的数据类型,是不是指定了类型就限定了变量的取值范围啊?”三妹吸了一口麦香可可奶茶后对我说。
“三妹,你不得了啊,长进很大嘛,都学会推理判断了。Java 是一种静态类型的编程语言,这意味着所有变量必须在使用之前声明好,也就是必须得先指定变量的类型和名称。”
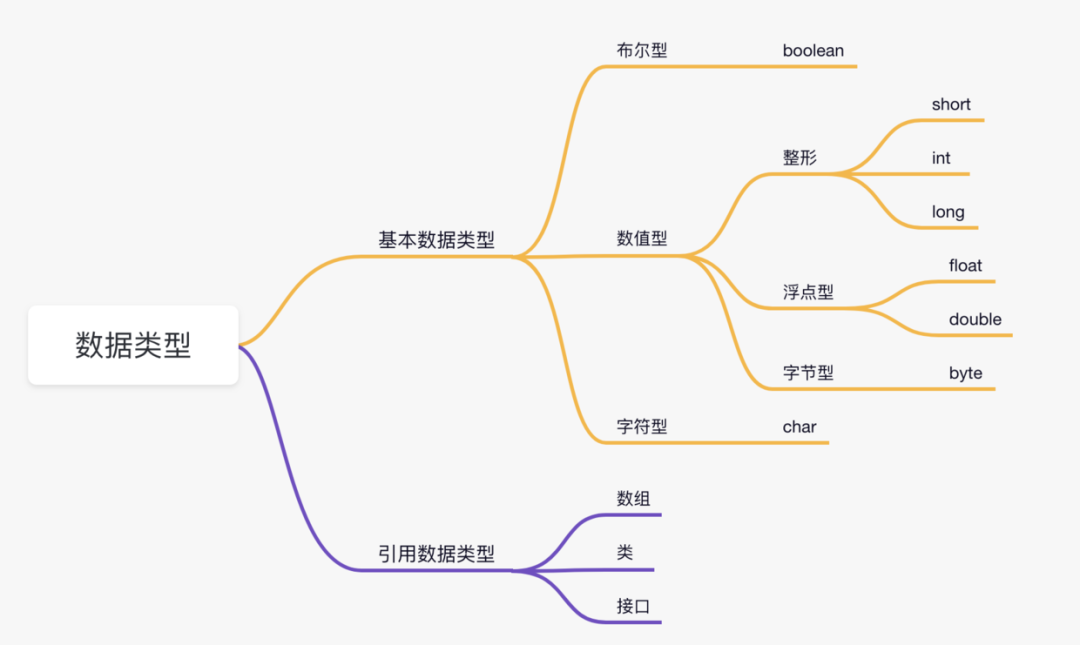
Java 中的数据类型可分为 2 种:
1)基本数据类型。
基本数据类型是 Java 语言操作数据的基础,包括 boolean、char、byte、short、int、long、float 和 double,共 8 种。
2)引用数据类型。
除了基本数据类型以外的类型,都是所谓的引用类型。常见的有数组(对,没错,数组是引用类型)、class(也就是类),以及接口(指向的是实现接口的类的对象)。
来个思维导图,感受下。
通过上一节的学习,我们知道变量可以分为局部变量、成员变量、静态变量。
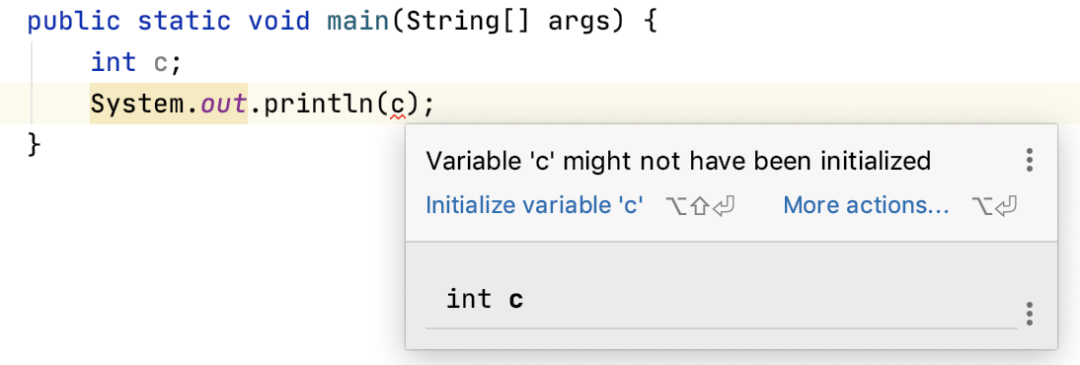
当变量是局部变量的时候,必须得先初始化,否则编译器不允许你使用它。拿 int 来举例吧,看下图。
当变量是成员变量或者静态变量时,可以不进行初始化,它们会有一个默认值,仍然以 int 为例,来看代码:
/**
* @author 微信搜「沉默王二」,回复关键字 PDF
*/
public class LocalVar {
private int a;
static int b;
public static void main(String[] args) {
LocalVar lv = new LocalVar();
System.out.println(lv.a);
System.out.println(b);
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
来看输出结果:
0
0
- 1.
- 2.
瞧见没,int 作为成员变量时或者静态变量时的默认值是 0。那不同的基本数据类型,是有不同的默认值和大小的,来个表格感受下。
| 数据类型 | 默认值 | 大小 |
|---|---|---|
| boolean | false | 1比特 |
| char | '\u0000' | 2字节 |
| byte | 0 | 1字节 |
| short | 0 | 2字节 |
| int | 0 | 4字节 |
| long | 0L | 8字节 |
| float | 0.0f | 4字节 |
| double | 0.0 | 8字节 |
那三妹可能要问,“比特和字节是什么鬼?”
比特币听说过吧?字节跳动听说过吧?这些名字当然不是乱起的,确实和比特、字节有关系。
1)bit(比特)
比特作为信息技术的最基本存储单位,非常小,但大名鼎鼎的比特币就是以此命名的,它的简写为小写字母“b”。
大家都知道,计算机是以二进制存储数据的,二进制的一位,就是 1 比特,也就是说,比特要么为 0 要么为 1。
2)Byte(字节)
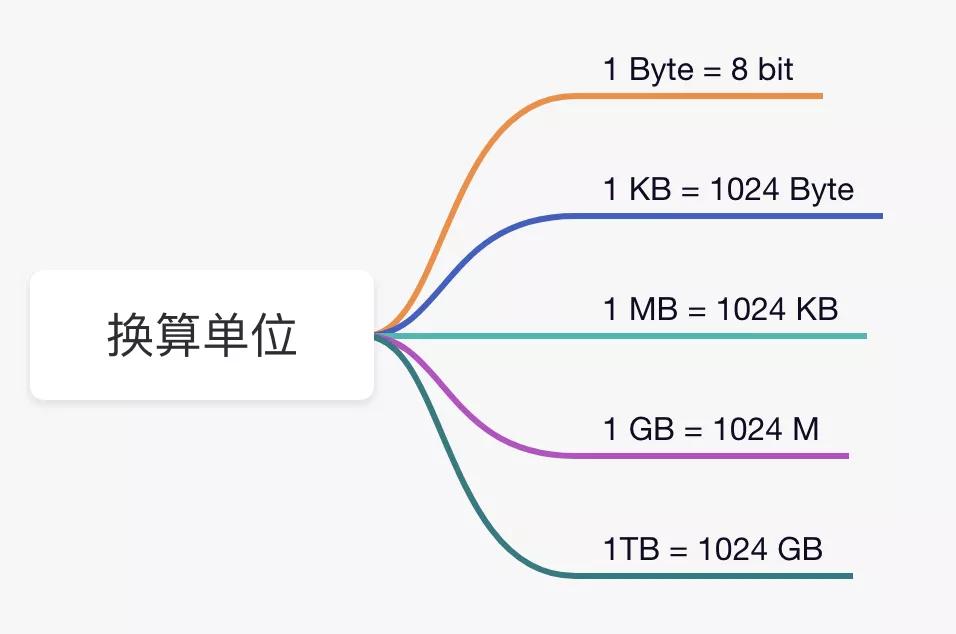
通常来说,一个英文字符是一个字节,一个中文字符是两个字节。字节与比特的换算关系是:1 字节 = 8 比特。
在往上的单位就是 KB,并不是 1000 字节,因为计算机只认识二进制,因此是 2 的 10 次方,也就是 1024 个字节。
(终于知道 1024 和程序员的关系了吧?狗头保命)
接下来,我们再来详细地了解一下 8 种基本数据类型。
01、布尔
布尔(boolean)仅用于存储两个值:true 和 false,也就是真和假,通常用于条件的判断。代码示例:
boolean flag = true;
- 1.
02、byte
byte 的取值范围在 -128 和 127 之间,包含 127。最小值为 -128,最大值为 127,默认值为 0。
在网络传输的过程中,为了节省空间,常用字节来作为数据的传输方式。代码示例:
byte a = 10;
byte b = -10;
- 1.
- 2.
03、short
short 的取值范围在 -32,768 和 32,767 之间,包含 32,767。最小值为 -32,768,最大值为 32,767,默认值为 0。代码示例:
short s = 10000;
short r = -5000;
- 1.
- 2.
04、int
int 的取值范围在 -2,147,483,648(-2 ^ 31)和 2,147,483,647(2 ^ 31 -1)(含)之间,默认值为 0。如果没有特殊需求,整形数据就用 int。代码示例:
int a = 100000;
int b = -200000;
- 1.
- 2.
05、long
long 的取值范围在 -9,223,372,036,854,775,808(-2^63) 和 9,223,372,036,854,775,807(2^63 -1)(含)之间,默认值为 0。如果 int 存储不下,就用 long,整形数据就用 int。代码示例:
long a = 100000L;
long b = -200000L;
- 1.
- 2.
为了和 int 作区分,long 型变量在声明的时候,末尾要带上大写的“L”。不用小写的“l”,是因为小写的“l”容易和数字“1”混淆。
06、float
float 是单精度的浮点数,遵循 IEEE 754(二进制浮点数算术标准),取值范围是无限的,默认值为 0.0f。float 不适合用于精确的数值,比如说货币。代码示例:
float f1 = 234.5f;
- 1.
为了和 double 作区分,float 型变量在声明的时候,末尾要带上小写的“f”。不需要使用大写的“F”,是因为小写的“f”很容易辨别。
07、double
double 是双精度的浮点数,遵循 IEEE 754(二进制浮点数算术标准),取值范围也是无限的,默认值为 0.0。double 同样不适合用于精确的数值,比如说货币。代码示例:
double d1 = 12.3
- 1.
那精确的数值用什么表示呢?最好使用 BigDecimal,它可以表示一个任意大小且精度完全准确的浮点数。针对货币类型的数值,也可以先乘以 100 转成整形进行处理。
Tips:单精度是这样的格式,1 位符号,8 位指数,23 位小数,有效位数为 7 位。

双精度是这样的格式,1 位符号,11 位指数,52 为小数,有效位数为 16 位。
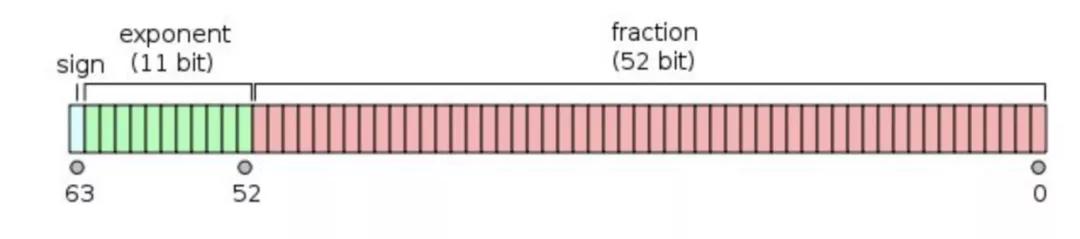
取值范围取决于指数位,计算精度取决于小数位(尾数)。小数位越多,则能表示的数越大,那么计算精度则越高。
一个数由若干位数字组成,其中影响测量精度的数字称作有效数字,也称有效数位。有效数字指科学计算中用以表示一个浮点数精度的那些数字。一般地,指一个用小数形式表示的浮点数中,从第一个非零的数字算起的所有数字。如 1.24 和 0.00124 的有效数字都有 3 位。
08、char
char 可以表示一个 16 位的 Unicode 字符,其值范围在 '\u0000'(0)和 '\uffff'(65,535)(包含)之间。代码示例:
char letterA = 'A'; // 用英文的单引号包裹住。
- 1.
那三妹可能要问,“char 既然只有一个字符,为什么占 2 个字节呢?”
“主要是因为 Java 使用的是 Unicode 字符集而不是 ASCII 字符集。”
这又是为什么呢?我们留到下一节再讲。
基本数据类型在作为成员变量和静态变量的时候有默认值,引用数据类型也有的。
String 是最典型的引用数据类型,所以我们就拿 String 类举例,看下面这段代码:
/**
* @author 微信搜「沉默王二」,回复关键字 PDF
*/
public class LocalRef {
private String a;
static String b;
public static void main(String[] args) {
LocalRef lv = new LocalRef();
System.out.println(lv.a);
System.out.println(b);
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
输出结果如下所示:
null
null
- 1.
- 2.
null 在 Java 中是一个很神奇的存在,在你以后的程序生涯中,见它的次数不会少,尤其是伴随着令人烦恼的“空指针异常”,也就是所谓的 NullPointerException。
也就是说,引用数据类型的默认值为 null,包括数组和接口。
那三妹是不是很好奇,为什么数组和接口也是引用数据类型啊?
先来看数组:
/**
* @author 微信搜「沉默王二」,回复关键字 java
*/
public class ArrayDemo {
public static void main(String[] args) {
int [] arrays = {1,2,3};
System.out.println(arrays);
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
arrays 是一个 int 类型的数组,对吧?打印结果如下所示:
[I@2d209079
- 1.
[I 表示数组是 int 类型的,@ 后面是十六进制的 hashCode——这样的打印结果太“人性化”了,一般人表示看不懂!为什么会这样显示呢?查看一下 java.lang.Object 类的toString() 方法就明白了。

数组虽然没有显式定义成一个类,但它的确是一个对象,继承了祖先类 Object 的所有方法。那为什么数组不单独定义一个类来表示呢?就像字符串 String 类那样呢?
一个合理的解释是 Java 将其隐藏了。假如真的存在一个 Array.java,我们也可以假想它真实的样子,它必须要定义一个容器来存放数组的元素,就像 String 类那样。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
- 1.
- 2.
- 3.
- 4.
- 5.
数组内部定义数组?没必要的!
再来看接口:
/**
* @author 微信搜「沉默王二」,回复关键字 Java
*/
public class IntefaceDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
System.out.println(list);
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
List 是一个非常典型的接口:
public interface List<E> extends Collection<E> {}
- 1.
而 ArrayList 是 List 接口的一个实现:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{}
- 1.
- 2.
- 3.
对于接口类型的引用变量来说,你没法直接 new 一个:

只能 new 一个实现它的类的对象——那自然接口也是引用数据类型了。
来看一下基本数据类型和引用数据类型之间最大的差别。
基本数据类型:
1、变量名指向具体的数值。2、基本数据类型存储在栈上。
引用数据类型:
1、变量名指向的是存储对象的内存地址,在栈上。2、内存地址指向的对象存储在堆上。
看到这,三妹是不是又要问,“堆是什么,栈又是什么?”
堆是堆(heap),栈是栈(stack),如果看到“堆栈”的话,请不要怀疑自己,那是翻译的错,堆栈也是栈,反正我很不喜欢“堆栈”这种叫法,容易让新人掉坑里。
堆是在程序运行时在内存中申请的空间(可理解为动态的过程);切记,不是在编译时;因此,Java 中的对象就放在这里,这样做的好处就是:
当需要一个对象时,只需要通过 new 关键字写一行代码即可,当执行这行代码时,会自动在内存的“堆”区分配空间——这样就很灵活。
栈,能够和处理器(CPU,也就是脑子)直接关联,因此访问速度更快。既然访问速度快,要好好利用啊!Java 就把对象的引用放在栈里。为什么呢?因为引用的使用频率高吗?
不是的,因为 Java 在编译程序时,必须明确的知道存储在栈里的东西的生命周期,否则就没法释放旧的内存来开辟新的内存空间存放引用——空间就那么大,前浪要把后浪拍死在沙滩上啊。
这么说就理解了吧?
“好了,三妹,关于 Java 中的数据类型就先说这么多吧,你是不是已经清楚了?”转动了一下僵硬的脖子后,我对三妹说。
“差不多,二哥,我觉得还得再消化会。”
本文转载自微信公众号「沉默王二」,可以通过以下二维码关注。转载本文请联系沉默王二公众号。