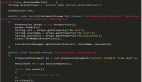
函数连续调用
- def add(x):
- class AddNum(int):
- def __call__(self, x):
- return AddNum(self.numerator + x)
- return AddNum(x)
- print add(2)(3)(5)
- # 10
- print add(2)(3)(4)(5)(6)(7)
- # 27
- # javascript 版
- var add = function(x){
- var addNum = function(x){
- return add(addNum + x);
- };
- addNum.toString = function(){
- return x;
- }
- return addNum;
- }
- add(2)(3)(5)//10
- add(2)(3)(4)(5)(6)(7)//27
默认值陷阱
- >>> def evil(v=[]):
- ... v.append(1)
- ... print v
- ...
- >>> evil()
- [1]
- >>> evil()
- [1, 1]
读写csv文件
- import csv
- with open('data.csv', 'rb') as f:
- reader = csv.reader(f)
- for row in reader:
- print row
- # 向csv文件写入
- import csv
- with open( 'data.csv', 'wb') as f:
- writer = csv.writer(f)
- writer.writerow(['name', 'address', 'age']) # 单行写入
- data = [
- ( 'xiaoming ','china','10'),
- ( 'Lily', 'USA', '12')]
- writer.writerows(data) # 多行写入
数制转换
- >>> int('1000', 2)
- 8
- >>> int('A', 16)
- 10
格式化 json
- echo'{"k": "v"}' | python-m json.tool
list 扁平化
- list_ = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
- [k for i in list_ for k in i] #[1, 2, 3, 4, 5, 6, 7, 8, 9]
- import numpy as np
- print np.r_[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
- import itertools
- print list(itertools.chain(*[[1, 2, 3], [4, 5, 6], [7, 8, 9]]))
- sum(list_, [])
- flatten = lambda x: [y for l in x for y in flatten(l)] if type(x) is list else [x]
- flatten(list_)
list 合并
- >>> a = [1, 3, 5, 7, 9]
- >>> b = [2, 3, 4, 5, 6]
- >>> c = [5, 6, 7, 8, 9]
- >>> list(set().union(a, b, c))
- [1, 2, 3, 4, 5, 6, 7, 8, 9]
出现次数最多的 2 个字母
- from collections import Counter
- c = Counter('hello world')
- print(c.most_common(2)) #[('l', 3), ('o', 2)]
谨慎使用
- eval("__import__('os').system('rm -rf /')", {})
置换矩阵
- matrix = [[1, 2, 3],[4, 5, 6]]
- res = zip( *matrix ) # res = [(1, 4), (2, 5), (3, 6)]
列表推导
- [item**2 for item in lst if item % 2]
- map(lambda item: item ** 2, filter(lambda item: item % 2, lst))
- >>> list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
- ['1', '2', '3', '4', '5', '6', '7', '8', '9']
排列组合
- >>> for p in itertools.permutations([1, 2, 3, 4]):
- ... print ''.join(str(x) for x in p)
- ...
- 1234
- 1243
- 1324
- 1342
- 1423
- 1432
- 2134
- 2143
- 2314
- 2341
- 2413
- 2431
- 3124
- 3142
- 3214
- 3241
- 3412
- 3421
- 4123
- 4132
- 4213
- 4231
- 4312
- 4321
- >>> for c in itertools.combinations([1, 2, 3, 4, 5], 3):
- ... print ''.join(str(x) for x in c)
- ...
- 123
- 124
- 125
- 134
- 135
- 145
- 234
- 235
- 245
- 345
- >>> for c in itertools.combinations_with_replacement([1, 2, 3], 2):
- ... print ''.join(str(x) for x in c)
- ...
- 11
- 12
- 13
- 22
- 23
- 33
- >>> for p in itertools.product([1, 2, 3], [4, 5]):
- (1, 4)
- (1, 5)
- (2, 4)
- (2, 5)
- (3, 4)
- (3, 5)
默认字典
- >>> m = dict()
- >>> m['a']
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- KeyError: 'a'
- >>>
- >>> m = collections.defaultdict(int)
- >>> m['a']
- 0
- >>> m['b']
- 0
- >>> m = collections.defaultdict(str)
- >>> m['a']
- ''
- >>> m['b'] += 'a'
- >>> m['b']
- 'a'
- >>> m = collections.defaultdict(lambda: '[default value]')
- >>> m['a']
- '[default value]'
- >>> m['b']
- '[default value]'
反转字典
- >>> m = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
- >>> m
- {'d': 4, 'a': 1, 'b': 2, 'c': 3}
- >>> {v: k for k, v in m.items()}
- {1: 'a', 2: 'b', 3: 'c', 4: 'd'}