













【51CTO.com原创稿件】小李今天刚上班就收到客户的反馈,说查询用户信息会非常的慢,有时甚至会出现超时的现象。
图片来自 Pexels
小李这就纳闷了分明已经给表加上了索引为什么还这么慢呢。小李分析了好久都没分析出原因,于是只能找到同部门的扫地僧大林子。
大林子一边听着小李的描述一边看着项目,就在小李刚把问题描述完大林子就对小李说:“问题解决了”,小李震惊不已,问道:“这么 6,是什么原因导致的呢?分明我已经加了索引了啊?”
大林子说:“这是很多开发人员很容易忽视的问题......”听完大林子的讲解小李瞬间茅塞顿开。那么具体什么原因呢,下面我就给大家讲解一下。
原因讲解
首先,我们来创建一个存储引擎为 InnoDB 的 User 表,这个表包含三个字段分别是 id,name 和 age。
其中 id 为主键 name 上添加了一个普通索引名字叫 n,接着我们像这条表中插入 10 亿条数据。
表和数据都创建完了,下面我们就来说说为什么加上了索引还是查询很慢,以及解决方案。
MySQL 会根据语句的执行时间来判断 SQL 语句是否是慢查询语句。
当一个 SQL 语句在执行时,MySQL 把语句执行时间和系统参数 long_query_time(这个参数的默认值是 10 秒,但是在实际项目中我们会将这个参数值设置为1秒甚至更短的时间) 作比较。
如果执行时间大于这个参数的值,那么就把这个语句记录到慢查询日志中。那么在语句执行过程中我们如何得知是否使用了索引呢?
这时我们就可以使用 explain 语句来查看数据结果中 Key 的值是否 null ,如果是 null 则说明没有使用索引。
下面我们来看一个例子:
- explain select * from user;
- explain select * from user where id=1;
- explain select name from user;
上面三个 explain 语句返回的 key 如下表所示:
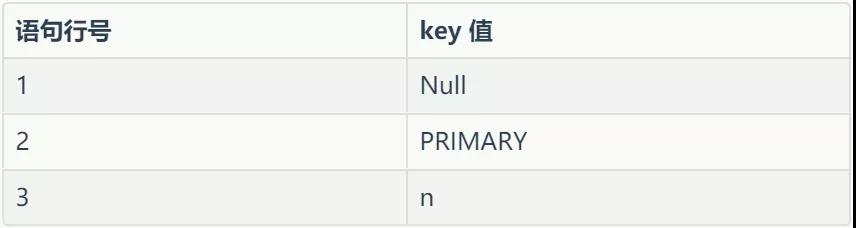
从上表我们可以看出第一个语句没有使用索引,第二个使用了主键索引,第三个语句使用 n 这个索引。
我们的 user 表有 10 亿条数据,可想而知第一条查询语句执行效率肯定低,第二个查询语句看似执行效率高,其实在极端环境下(比如 CPU 高负载)也会出现查询效率低的问题。
最后一个查询语句呢虽然使用了 n 这个索引,但是它实际上执行了扫描整个索引树的操作,因此查询效率也高不到哪去。
综上所述,我们可知索引是否使用和是否被记录到慢查询中几乎没有联系,索引只是 SQL 的一个执行过程,SQL 的执行时间才是决定是否被记录到慢查询中的关键。
前面一小节我们只是简单的分析了一下问题,下面我们进一步看这个问题。我们知道 InnoDB 是索引组织表,所有数据都存储在索引树上。
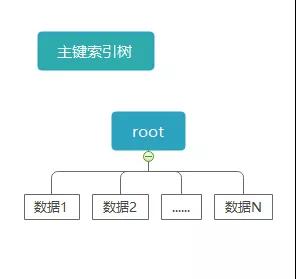
在 InnoDB 中数据放在主键索引里,因此理论上来说所有在 InnoDB 表中的查询至少使用了一个索引。
比如这个 SQL 查询语句 select * from user where id > 1000,很明显它使用主键索引,并且这个语句一定执行了整个索引树的扫描。
在 InnoDB 中只有一种情况叫不使用索引,就是从主键索引的最左边的叶子结点开始向右扫描整个索引树。
到目前为止我们已经知道了全索引扫描会造成查询变慢,下面我们就来说一下另一个知识点过滤性 。
假如我们要查询 user 表中 age 在 70 岁以上 80 岁以下的人员信息,你一定会在 age 字段上加入索引来避免全局扫描。
不错,这是个好的想法,但是当你运行查询语句时就会发现它依然执行的很慢,这是为什么呢?
要解答这个问题我们先来看一下 SQL 查询语句的执行流程:
- 搜索 age 索引树,获取到第一个 age 为 70 的记录。
- 拿到主键值,根据主键值去主键索引树上获取对应的信息,并将信息加入结果集。
- 在 age 索引树上向右侧扫描,获取到下一个主键值,执行第二部的操作。
- 不断执行上面的步骤,直到遇到第一个 age 大于 80 的记录为止。
从上面的步骤中我们可以看出虽然使用了索引,但是查询过程中扫描了上万行甚至上亿行。
因此我们可以得出结论:对于这种数据非常多的表,我们所要做的不仅仅是加入索引,还要保证索引的过滤性足够优秀。
假如说我们把索引的过滤性也处理好了,是不是查询时要扫描的行数就一定会表少呢?
这个答案是否定的,比如说我们的 user 表中的 name 和 age 字段共同组成了联合索引并处理好了过滤性,这时当我们查询姓李的并且年龄是 60 岁的数据时查询效率依然很低。

我们先来看一下查询语句的执行流程:
- 首先从联合索引上找到姓名字段是李字开头的数据记录。
- 拿到主键值,根据主键值在主键索引书上去除匹配的数据。
- 接着根据 age 字段去判断年龄是否等于 60,如果符合就加入结果集。
- 然后再联合所以上向右侧遍历,并不断做回表和判断,直到遇到 name 的第一个字不是李的为止。
Tip:所谓的回表就是根据主键值去主键索引树上查找对应的数据。
从上面的步骤中我们可以看出最耗时的就是回表,如果姓李的数据有 2 亿条那么就要回表 2 亿次,并且 SQL 在定位第一行数据时只能使用最左前缀原则。
这种耗时的回表操作步骤在 MySQL 5.6 及其以后的版本中已经做了 index condition pushdown 优化。
优化后的流程很简单:
- 首先从联合索引上找到姓名字段是李字开头的数据记录,并判断这个记录里 age 是不是 60,如果是就执行回表取出数据假如结果集。
- 重复步骤1,直到配当第一个字不是李字的记录为止。
优化后和优化前的区别是把 age 的对比步骤放在了遍历联合索引树上,减少了回表次数。
但是虽然减少了回表次数,联合索引树的遍历去没有减少依然要遍历 2 亿次,那么有没有更好的优化方案呢?答案是有的,我们可以实虚拟列来进行处理。
首先我们需要把 name 的第一个字和 age 做一个联合索引,让虚拟列的值总是等于 name 字段的前两个字节,这里需要注意的是虚拟列不随着 insert 和 update 变化,它的值是自定义生成的。
语句如下:
- alter table user add name_first varchar(2) generated (left(name,1)),add index(name_first,age);
经过上述的优化后联合索引树的查询次数也降低了,本质上就是创建一个紧凑的索引加快查询。
总结
这篇文章主要介绍了查询优化的基本思路,只要记住优化查询的过程都是减少扫描行数的过程,就可以做到在 SQL 查询面前百战百胜。
作者:朱钢,笔名喵叔
简介:.NET 高级开发人员,2019 年度博客之星 20 强,长期从事电子政务系统和AI客服系统的设计与开发,目前就职于国内某 BIM 大厂从事招投标软件的开发。
编辑:陶家龙
征稿:有投稿、寻求报道意向技术人请联络 editor@51cto.com
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】






















