这一篇是我重写的,之前写过一篇发现面试的时候问的问题虽然大概能解决,但是有几个点没有整理到位,所以自己给自己列出了很多面试常见的问题,准备一篇一篇去解决。本文整体思路是延续之前的那篇文章,在此基础之上添加了几个点而已。
布隆过滤器主要是在redis中问的比较多,因此像这种数据结构类的,主要是考原理以及使用场景。下面一点一点开始逐步介绍。
一、认识布隆过滤器
1、概念
布隆过滤器其实就是加快判定一个元素是否在集合中出现的方法。比如说在一个大字典中,要查找某个单词是否存在,于是我们就可以使用布隆过滤器,快速高效省时省力。
这里有一个考察点,那就是布隆过滤器只能判定一个元素不在集合里面,不能判断存在,什么意思呢!就是说一个苹果不在篮子里,这个我可以通过布隆过滤器知道,但是一定在篮子里嘛?这个通过布隆过滤器我是不能判定的。
下面通过原理就能理解这个了。
2、原理
先举一个例子,在我们身边充斥着各种各样的XX网站,为了不毒害我们祖国的花朵,于是国家网警就开始对这些网站进行割除过滤,问题来了,这些网站的地址其实是不停的更换的,这些垃圾网站和正常网站加起来全世界据统计也有几十亿个。因此就会带来如下的问题:
(1)网站数量太多,存储起来比较麻烦。一个地址最起码有32个字节,一亿个地址就需要1.6G的内存。
(2)一个一个比较,太费时间了。
因此布隆过滤器被设计出来了,他是如何做到高效的呢?本质上其实就是一个HASH映射器。他的底层其实是一个超大的二进制向量和一系列随机映射函数。现在我们按照之前的那个例子,我们存储1亿个垃圾网站地址。
(1)第一步:建立一个32亿二进制(比特),也就是4亿字节的向量。全部置0。
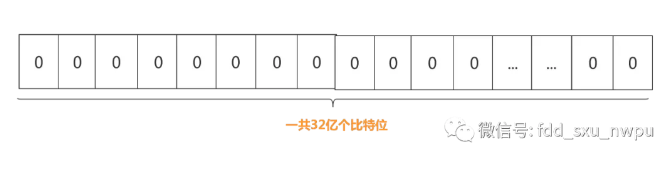
img
(2)第二步:网警用八个不同的随机数产生器(F1,F2, …,F8) 产生八个信息指纹(f1, f2, …, f8)。
(3)第三步:用一个随机数产生器 G 把这八个信息指纹映射到 1 到32亿中的八个自然数 g1, g2, …,g8。
(4)第四步:把这八个位置的二进制全部设置为一。
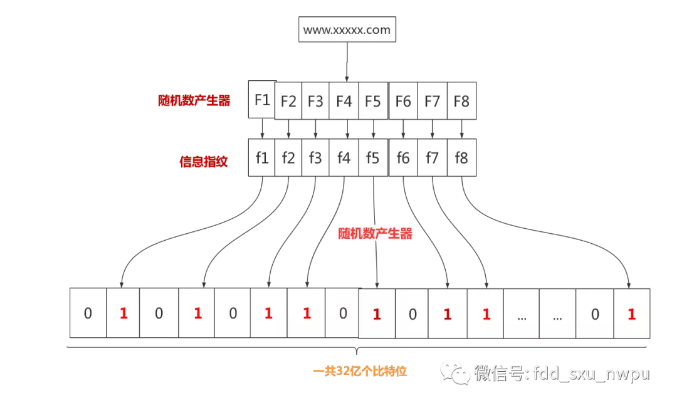
img
OK,有一天网警查到了一个可疑的网站,想判断一下是否是XX网站,于是就开始检查了。通过同样的方法将XX网站通过哈希映射到32亿个比特位数组上的8个点。如果8个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。
注意:现在你可能会发现一个问题,如果两个XX网站通过上面的步骤映射到了相同的8个点上,或者是有一部分点是重合的,这时候该怎么办?于是就出现了误报,也就是说A网站在12345678个点上全部置1,B网站通过同样的方式在23456789上全部置1,这时候B网站来了是不能确定是否包含的。这个逻辑相信各位都理解。这个是最基础的面试问题。
3、误报率
这一小节是稍微高级一点点,某中厂问到了一次,于是这一次就添加了进来。
通过上面的解释相信都大概了解的差不多了,其实就是hash函数映射,由于有hash冲突产生了误报率,误报率也就是判断失败的情况。
既然是由于hash冲突,那我把布隆过滤器的二进制向量调到很大,这样不就解决了嘛,但是由于数据量比较大,因此现在就要考虑一下误报率和存储效率之间选择一个折中值了。有一个计算公式如下:公式来源于github
假设位数组的长度为m,哈希函数的个数为k。检测某一元素是否在该集合中的误报率是:
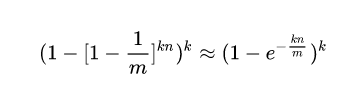
[公式]
如何使得误报率最小,数学问题,求导就可以了。
4、使用场景
(1)google的guava包中有对Bloom Filter的实现
(2)通常使用布隆过滤器去解决redis中的缓存穿透,解决方案是redis中bitmap的实现,
(3)钓鱼网站、垃圾邮件检测
大体就这些,可能还有很多!!!
二、代码实现布隆过滤器
上面只是给出了其原理,下面我们代码实现一下。
- public class MyBloomFilter {
- // 2 << 25表示32亿个比特位
- private static final int DEFAULT_SIZE = 2 << 25 ;
- private static final int[] seeds = new int [] {3,5,7,11,13,19,23,37 };
- //这么大存储在BitSet
- private BitSet bits = new BitSet(DEFAULT_SIZE);
- private SimpleHash[] func = new SimpleHash[seeds.length];
- public static void main(String[] args) {
- //可疑网站
- String value = "www.愚公要移山.com" ;
- MyBloomFilter filter = new MyBloomFilter();
- //加入之前判断一下
- System.out.println(filter.contains(value));
- filter.add(value);
- //加入之后判断一下
- System.out.println(filter.contains(value));
- }
- //构造函数
- public MyBloomFilter() {
- for ( int i = 0 ; i < seeds.length; i ++ ) {
- func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
- }
- }
- //添加网站
- public void add(String value) {
- for (SimpleHash f : func) {
- bits.set(f.hash(value), true );
- }
- }
- //判断可疑网站是否存在
- public boolean contains(String value) {
- if (value == null ) {
- return false ;
- }
- boolean ret = true ;
- for (SimpleHash f : func) {
- //核心就是通过“与”的操作
- ret = ret && bits.get(f.hash(value));
- }
- return ret;
- }
- }
还有一个SimpleHash,我们看一下
- public static class SimpleHash {
- private int cap;
- private int seed;
- public SimpleHash( int cap, int seed) {
- this .cap = cap;
- this .seed = seed;
- }
- public int hash(String value) {
- int result = 0 ;
- int len = value.length();
- for ( int i = 0 ; i < len; i ++ ) {
- result = seed * result + value.charAt(i);
- }
- return (cap - 1 ) & result;
- }
- }
这就是布隆过滤器的实现。
本文转载自微信公众号「愚公要移山」,可以通过以下二维码关注。转载本文请联系愚公要移山公众号。