稳定性目前不再局限于大促时的保障和平时的稳定性轮值,越来越体系化。本文基于作者在业务团队工作过程中的沉淀,以及在盒马两年SRE的实战经验,从稳定性心态、监控体系、故障应急体系、资源体系、大促保障机制、日常保障机制等几个层面,就如何做好SRE的工作进行了分享。
前言
2013年,当我第一次接触稳定性的时候,我是有些懵的,当时完全不知道稳定性是什么,也不清楚要做什么。在接下来的8年里,我先后在菜鸟、天猫、盒马从事中间件、业务系统、架构等方面的工作,期间一直穿插着负责稳定性和大促的保障工作。我的心态,大致经历过以下几个阶段:
- low:完全不懂,觉得稳定性就是做别人安排好的一些表格和梳理,不知道自己该做啥,稳定性好low。
- 烦:各种重复的会议,做好了是应该的,做不好就是责任,很烦很焦虑。
- 知道该做什么,但是累:各种报警和风险,每天需要担心,想要不管又过不了自己心里那关;大促时候天天熬夜,各种压测,最终自己累得够呛。
- 发现结合点:发现在采用系统化思维之后,稳定性与系统自身的结合变得紧密,稳定性成为一种基线,找到了稳定性中的关键点和重点。
- 主动驱动:发现线上业务和线下业务的稳定性差别,理解并主动调整在不同业务团队采取的稳定性策略,探究在稳定性中的自动化、工具化,系统化建立稳定性机制。
- 形成体系:形成稳定性体系化思考,明确稳定性每一个点在业务团队大图中的位置,探究系统弹性建设。
近两年来,稳定性不再仅仅局限于之前的大促保障和平时的稳定性轮值,越来越体系化,在保障体系、监控体系、资源体系、质量保障、变更管控等多个方面,越来越系统。阿里的各个事业部,也纷纷成立专职的SRE安全生产团队。然而仍有很多人和业务团队,对于稳定性的理解和认知未形成一个体系化的机制,下面就结合我在业务团队系统稳定性上的认识,以及最近2年在盒马的一些思考,做一个分享。
什么是SRE
SRE(Site Reliability Engineering,站点可靠性/稳定性工程师),与普通的开发工程师(Dev)不同,也与传统的运维工程师(Ops)不同,SRE更接近是两者的结合,也就是2008年末提出的一个概念:DevOps,这个概念最近也越来越流行起来。SRE模型是Google对Dev+Ops模型的一种实践和拓展(可以参考《Google运维解密》一书),SRE这个概念我比较喜欢,因为这个词不简单是两个概念的叠加,而是一种对系统稳定性、高可用、团队持续迭代和持续建设的体系化解决方案。
那么要如何做好一个SRE呢,这是本文要探讨的话题。
一 心态&态度
1 谁适合做稳定性?
就像前言里我做稳定性前期的心态一样,稳定性最初上手,是提心吊胆、不得其门而入的,所以想要做好稳定性,心态最重要,业务团队想要找到合适做稳定性的人,态度也很重要。对于业务团队,要如何挑选和培养团队中最合适做稳定性的人呢?
必须选择负责任的人
负责任是第一要素,主动承担,对报警、工单、线上问题、风险主动响应,不怕吃苦;一个不负责任的人,遇到问题与我无关的人,边界感太强的人,难以做好稳定性的工作。
原则上不要选择新人
对于团队leader而言,“用新人做别人不愿意做的工作”,这个决定比较容易做出,但是这也相当于是把团队的稳定性放在了一定程度的风险上,用新人做稳定性,其实只是用新人占了稳定性的一个坑而已。新人不熟悉业务,不了解上下游,最多只能凭借一腔热血,对业务和系统感知不足,容易导致线上风险无法被快速发现、故障应急无法迅速组织。
不要用过于"老实"的人
这里的“老实”的定义是不去主动想优化的办法,不主动出头解决问题,但是很能吃苦,任劳任怨,也很能忍耐系统的腐烂和低效;这样的人平时很踏实,用起来也顺手,但是却无法主动提高系统稳定性,有的时候反而会给系统稳定性造成伤害(稳定性就像大堤,不主动升级,就早晚会腐烂)。
2 业务团队如何支持稳定性SRE人员
给资源
稳定性从来不只是稳定性负责人的事情,而是全团队的事情,稳定性负责人要做的是建立机制,主动承担,但是稳定性意识,要深入到团队所有人脑子里,稳定性的事情,要能够调动团队一切资源参与。
给空间
做稳定性的人,往往面临一个尴尬场景:晋升困难,主要是因为在技术深度和业务价值两个方面,很容易被挑战,对于业务团队,一定要留给做稳定性的人足够的思考和上升空间,将稳定性与团队的技术架构升级、业务项目结合起来,共同推动。经过集团安全生产团队的推动,目前在阿里,SRE已经有了自己专门的晋升体系。
区分责任
当出现故障时,区分清楚责任,到底是稳定性工作没有做到位,还是做到位了,但是团队同学疏忽了,还是说只是单纯的业务变化。
3 开发和SRE的区别
都是做技术的,很多开发刚刚转向负责稳定性时,有些弯转不过来。
举个例子:对于“问题”,传统的开发人员更多的倾向于是“bug/错误”,而SRE倾向于是一种“风险/故障”,所以,两者对“问题”的处理方法是不一样的:
- 开发:了解业务 -> 定位问题 -> 排查问题 -> 解决问题
- SRE:了解业务归属 -> 快速定位问题范围 -> 协调相关人投入排查 -> 评估影响面 -> 决策恢复手段
可见,开发人员面对问题,会首先尝试去探究根因,研究解决方案;而SRE人员首先是评估影响,快速定位,快速止损恢复。目标和侧重点的不同,造成了SRE思考问题的特殊性。
所以,成为一名SRE,就一定要从态度和方式上进行转变,切换到一个“团队稳定性负责人”的角度上去思考问题。
4 SRE心态上的一些释疑
下面这些疑惑,有很多是我最初做稳定性的时候面临的问题,这里给大家分享和解释一下我的解决方法:
疑惑1:做好了是应该的,出了问题就要负责任
不出问题,就是稳定性的基线,也是SRE的基本目标,所以这个话虽然残酷,但是也不能说错,关键在于:你要如何去做。
如果抱着一个“背锅” / “打杂”的思想去做稳定性,那么“做好没好处、做不好背锅”这句话就会成为击垮心理防线的最重的稻草。
应对这种心态的最关键一点,在于“做好”不出问题这条基线,要从下面3个方面去做:
(1)及时、快速的响应
这是最关键的一点,作为一个SRE,能够及时、快速的响应是第一要务,遇到报警、工单、线上问题,能够第一时间冲上去,不要去问是不是自己的,而是要问这个事情的影响是什么,有没有坑,有没有需要优化的风险?这是对自己负责;
同时,快速的响应,还需要让你的老板第一时间知悉,这个不是在老板面前爱表现拍马屁,而是要让你的老板第一时间了解风险的发生,一个好的团队leader,一定是对质量、稳定性和风险非常敏感的leader,所以,你要将风险第一时间反馈。这是对老板负责。
反馈也是有技巧的,不仅仅是告知这么简单,你需要快速的说明以下几个信息:
- 尽快告知当前告警已经有人接手,是谁接手的,表明问题有人在处理了(这一步叫“响应”)。
- 组织人员,快速定位问题,告知问题初步定位原因。(这一步叫“定位”)
- 初步影响范围是什么?给出大致数据。(这一步方便后面做决策)
- 有哪些需要老板、产品、业务方决策的?你的建议是什么?(这一步很关键,很多时候是:两害相权取其轻,你的评估和建议,直接影响老板的决策)
- 当前进展如何,是否已经止血?(这一步是“恢复”,要给出“进展”,让决策者和业务方了解情况)
需要注意的是:如果你响应了,但是没有及时的同步出来,等于没响应,默默把事情做了,是开发者(Dev)的思维,作为SRE,风险和进展的及时组织和通报,才是你应该做的。
当然,你的通报要注意控制范围,最好优先同步给你的主管和产品进行评估,避免范围过大引起恐慌,要根据事情的严重程度来共同决定,这是对团队负责。
及时、快速的响应,是保证不出问题的关键,也是SRE人员赢得领导、业务方、产品和其他合作方信任的关键,赢得信任,是解决“做好没好处、做不好背锅”的基石。
(2)把机制建立好,切实落地
前面已经说过,“稳定性从来不只是稳定性负责人的事情”,这一点,要深入到团队每个人的心里,更要深入到SRE自己心里,一人抗下所有,不是英雄的行为,在SRE工作中,也不值得赞许,很多时候一人抗下所有只会让事情变得更糟糕。
作为一个SRE,想做到“不出问题”这个基线,关键还是要靠大家,如何靠大家呢?就是要落地一套稳定性的机制体系,用机制的严格执行来约束大家,这套机制也必须得到团队leader的全力支持,不然无法展开,这套机制包括:
- 稳定性意识
- 日常值班机制
- 报警响应机制
- 复盘机制
- 故障演练机制
- 故障奖惩机制
- 大促保障机制
比如,如果总是SRE人员去响应报警和值班,就会非常疲惫劳累,人不可能永远关注报警,那怎么办呢?可以从报警机制、自动化、值班机制3个方面入手:
一方面,让报警更加准确和完善,减少误报和漏报,防止大家不必要的介入,另一方面产出自动化机器人,自动进行一些机器重启,工单查询,问题简单排查之类的工作,还有就是建立值班轮班,让每个人都参与进来,既能让大家熟悉业务,又能提高每个人的稳定性意识。
对于SRE来说,指定机制并且严格落地,比事必躬亲更加重要。上面这些机制,将在后面的章节中详细论述。
(3)主动走到最前线
SRE工作,容易给人一种错觉:“是做后勤保障的”,如果有这种思想,是一定做不好的,也会把“做好没好处、做不好背锅”这个疑惑无限放大。作为SRE人员,一定要主动走到最前线,把责任担起来,主动做以下几个事情:
- 梳理。主动梳理团队的业务时序、核心链路流程、流量地图、依赖风险,通过这个过程明确链路风险,流量水位,时序冗余;
- 治理。主动组织风险治理,将梳理出来的风险,以专项的形式治理掉,防患于未然。
- 演练。把风险化成攻击,在没有故障时制造一些可控的故障点,通过演练来提高大家响应的能力和对风险点的认知。这一点将在后面详述。
- 值班。不能仅仅为了值班而值班,值班不止是解决问题,还要能够发现风险,发现问题之后,推动上下游解决,减少值班中的重复问题,才是目标。
- 报警。除了前面说过的主动响应之外,还要经常做报警保险和机制调整,保证报警的准确度和大家对报警的敏感度。同时也要做到不疏忽任何一个点,因为疏忽的点,就可能导致问题。
疑惑2:稳定性总是做擦屁股的工作
这么想,是因为没有看到稳定性的前瞻性和价值,如果你走在系统的后面,你能看到的就只有系统的屁股,也只能做擦屁股的工作,如果你走到了系统的前面,你就能看到系统的方向,做的也就是探索性的工作。
所以,要让稳定性变成不“擦屁股”的工作,建议从下面2个方面思考:
(1)不能只做当下,要看到未来的风险,善于总结
暖曰:“ 王独不闻魏文王之问扁鹊耶?曰:‘子昆弟三人其孰最善为医?’扁鹊曰:‘长兄最善,中兄次之,扁鹊最为下。’魏文侯曰:‘可得闻邪?’扁鹊曰:‘长兄于病视神,未有形而除之,故名不出于家。中兄治病,其在毫毛,故名不出于闾。若扁鹊者,镵血脉,投毒药,副肌肤,闲而名出闻于诸侯。’魏文侯曰:‘善。使管子行医术以扁鹊之道,曰桓公几能成其霸乎!’凡此者不病病,治之无名,使之无形,至功之成,其下谓之自然。故良医化之,拙医败之,虽幸不死,创伸股维。”
——《鶡冠子·卷下·世贤第十六》
与扁鹊三兄弟一样,如果想要让稳定性有价值,SRE同学一定不能站到系统的屁股后面等着擦屁股,必须走到前面,看到未来的风险。既要在发生问题时快速解决问题(做扁鹊),也要把风险归纳总结,推动解决(做二哥),还要在系统健康的时候评估链路,发现隐藏的问题(做大哥)。
- 做扁鹊大哥:在系统健康时发现问题
- 做扁鹊二哥:在系统有隐患时发现问题
- 做扁鹊:在系统发生问题时快速解决问题
(2)自动化、系统化、数据化
SRE不是在做一种收尾型、擦屁股的工作,而是在做一种探索性、前瞻性的工作,但SRE不可避免的,会面对很多重复性的工作,所以除了要在组织和机制上做好分工,让恰当的人做恰当的事之外,SRE人员要经常思考产品的系统化和弹性化,要常常思考下面几个问题:
- 常常思考产品和系统哪里有问题,如何优化,如何体系化?
- 常常思考有没有更好的办法,有没有提高效率的办法?
- 常常思考如何让稳定性本身更加有价值,有意义?
这3个问题,我觉得可以从3个方面着手:
(1)自动化
这里自动化,包括自动和自助2个部分。自动是指能够系统能够对一些异常自动恢复、自动运维,这部分,也可以叫做“弹性”,它一方面包括兜底、容灾,另一方面也包括智能化、机器人和规则判断。比如,对一些可能导致问题的服务失败,能够自动走兜底处理逻辑,能够建立一个调度任务,自动对这部分数据进行调度处理;对一些机器的load飚高、服务抖动等,能自动重启,自动置换机器。
自助是让你的客户自己动手,通过提供机器人,自动识别订单类型,自动排查订单状态和节点,自动告知服务规则特征,自动匹配问题类型给出排查结果或排查过程等。
Google SRE设置了一个50%的上限值,要求SRE人员最多只在手工处理上花费50%的时间,其他时间都用来编码或者自动化处理。这个可以供我们参考。
(2)系统化
系统化,可以体现在SRE工作的方方面面,我觉得,可以主要在“监控、链路治理、演练” 3方面入手。这3个方面也正好对应着“发现问题、解决风险、因事修人” 3个核心。通过系统化,目的是让我们SRE的工作形成体系,不再是一个个“点”的工作,而是能够连成“面”,让SRE工作不再局限于“后期保障/兜底保障”,而是能够通过监控体系、链路风险、演练体系发现问题。
监控、链路治理和演练的系统化,将在后面的章节中详细探讨。
(3)数据化
稳定性工作,如果要拿到结果,做到可量化,可度量,就一定要在数据化上下功夫,这个数据化,包括如下几个方面:
- 数据驱动:包括日志标准化和错误码标准化,能够对日志和错误码反馈的情况进行量化。
- 数据对账:包括上下游对账、业务对账,能够通过对账,保障域内数据校准。
- 轨迹跟踪:包括变更轨迹和数据轨迹,目标是实现数据的可跟踪,和变更的可回溯、可回滚。
- 数据化运营:主要是将稳定性的指标量化,比如工单解决时间、工单数、报警数、报警响应时间、故障风险数、代码CR量,变更灰度时长等,通过量化指标,驱动团队同学建立量化意识,并且能给老板一份量化数据。
疑惑3:稳定性似乎总是新人的垃圾场
虽然前文中说过,对于团队而言,最好不要让新人从事稳定性工作,但是稳定性毕竟是很多希望“专注工作”的开发人员不愿意做的,这个时候,团队leader很容易做出让一个刚进入团队的人从事稳定性工作,毕竟其他核心开发岗位的人似乎对团队更加重要,也不能调开去从事这种“重要不紧急”的工作,不是吗?
所以这个时候,新人被安排了稳定性工作,也是敢怒不敢言,充满抱怨的做已经约定好的工作,或者浑浑噩噩的划划水,只在需要“应急”的时候出现一下。
这个现状要解决,就要涉及到一个人的“被认可度”,也是我们经常说一个人的价值(在个人自我感知上,我们认为这是“成就感”),很多人可能觉得一个人是因为有价值,才会被认可。而我认为,一个人是因为被认可,才会觉得自己有价值,这样才会产生做一件事情的成就感。
毕竟,能一开始就找到自己喜欢并且愿意去创造价值的事情,是很少的。大多数人是在不情不愿的去做自己并不知道方向也无所谓成败的事情。这个时候,是做的事情被认可,让自己感觉有价值,产生兴趣,而不是反过来,爱一行做一行是幸运的,做一行爱一行是勇敢的。
那么对于稳定性的新人,如果你“被安排”从事了稳定性,那么首先要注意下面3个点:
- 对于稳定性新人,一定要优先考虑如何响应问题,而不是如何解决问题。
- 稳定性从来都不是简单的,他的关键,是要做细,这需要细心和耐心。
- 稳定性不是一个人的事情,要团结团队内的同学,上下游的同学。
在有了上面3点心理建设之后,要开始在自己的心里,构建3张图,3张表:
(1)3张图
- 系统间依赖图(也包括业务时序,熟悉业务流程),参考5.4节系统依赖梳理方法。
- 流量地图(知道上下游系统,团队内系统的流量关系和流量水位,也同时把控系统架构),参考5.3节流量地图。
- 系统保障图(知道稳定性保障的步骤和打法),参考5.2节作战地图。
(2)3张表
- 机器资源表(做到占用多少资源,了然于胸,团队需要时能拿得出来),参考第4章资源管控。
- 异常场景应急表(出现问题时知道怎么应对,演练知道哪里容易出问题),参考3.2节故障场景梳理。
- 业务近30日单量表(知道哪些业务影响大,哪些业务是重点),参考6.1节黄金链路治理。
心中3张图,3张表,可以让自己心中有数,不会抓瞎,这就像林彪在《怎样当好一个师长》一文中写的那样,心里要有个“活地图”。这样,一个新人才能快速熟悉起团队的业务和系统,明白风险在哪里,要往哪里打。才能让自己的工作变得被认可,直击痛点,有价值。
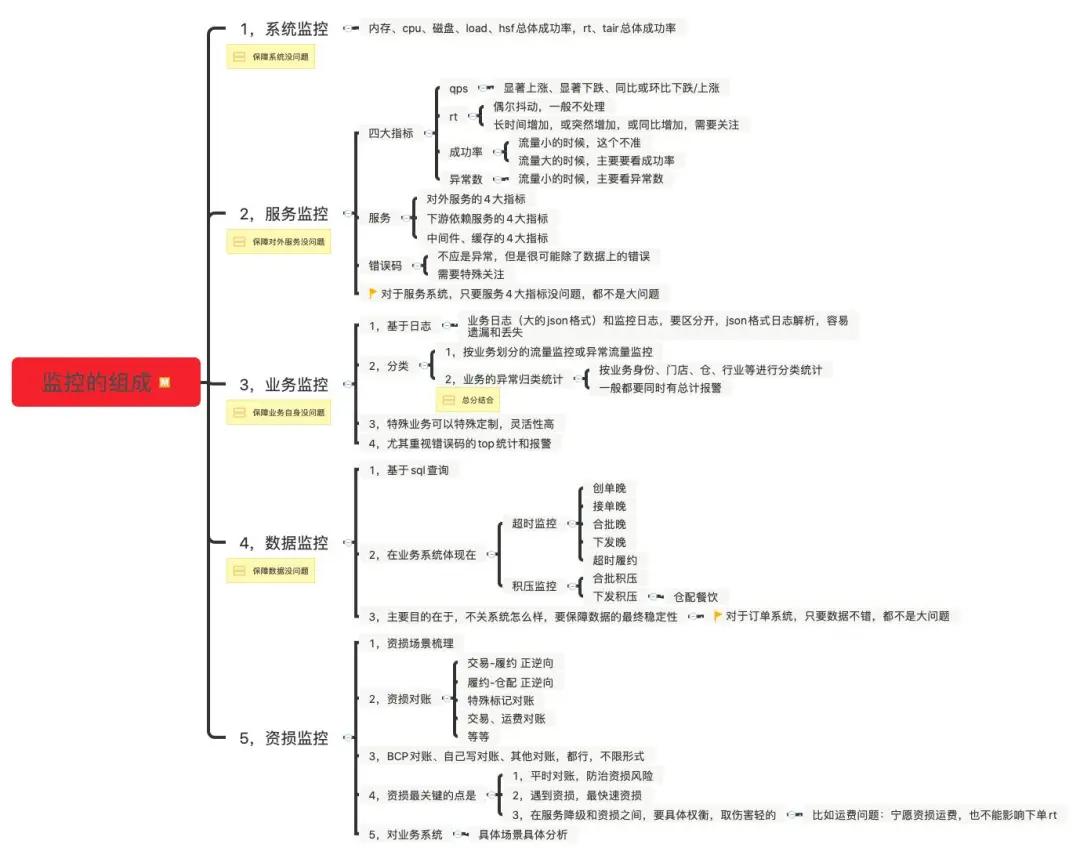
二 监控
再牛的SRE,也不可能对整个复杂系统了如指掌,也不可能做到对每次变更和发布,都在掌控之内,所以对于SRE人员来说,就必须要有一双敏锐的“眼睛”,这双“眼睛”,无论是要快速响应,还是要发现风险,都能快速发现问题,这就是“监控”。
从运维意义上讲,“发现问题”的描述 和 “监控”的实现之间的对应关系如下:
发现问题的需求描述 | 监控的实现 |
减少人力发现成本 | 自动监控、多种报警手段 |
及时、准确 | 实时监控、同比、环比、对账 |
防止出错 | 减少误报、同比环比、削峰 |
不遗漏 | 减少漏报,多维监控 |
直观评估影响面 | 对账&统计 |
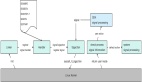
1 监控的5个维度
监控的核心目标,是快速发现“异常”。那如何定位异常呢?是不是低于我们设置的阈值的,都是异常?如果要是这么定义的话,你会发现,报警非常多,应接不暇。
要定义异常,就要考虑一个问题:兼容系统的弹性,也就是系统要有一定的容错能力和自愈能力,不然就会非常脆弱和敏感。因此,我对“异常”的定义,是:在服务(体验)、数据、资金3个方面中至少1个方面出现了损失 或 错误。我认为,一个系统,如果在下面3个方面没有出现问题,那么即使中间过程出现了偏差,或者没有按既定路径达到最终结果,我也认为没有出现“异常”(这也是一种弹性):
- 在服务方面没有异常(我把服务错误造成的用户体验,也认为是服务异常)。
- 在数据上没有出错(我把订单超时等体验,也认为是数据出现了偏差)。
- 在资金上没有资损(走了兜底逻辑,且按照业务可接受的预定范围兜底造成的损失,不算资损,如兜底运费)。
所以监控一个系统是否具有健壮性(即:弹性(Resilient),这一点在后面【弹性建设】中详细论述),就要从这3个最终目标去实现,为了达到这3个目标,我们可以从 系统自身、服务接口、业务特征、数据、资金对账 5个维度保障监控的准确性。
下图详细解释了这5个维度:
image
2 监控大盘
建立监控大盘的目的,是在大促等关键时期,在一张图上能够看到所有的关键指标。所以大盘的key point应该是“直观简洁、指标核心、集中聚焦”。在大盘上,我认为要包括以下要素:
- 最核心业务入口的qps、rt、错误数、成功率,从这个维度可以看到入口流量的大小和相应时间,成功率。这一点,是在知道入口的健康情况。
- 错误码top N,这个维度可以看到系统运行过程中最核心的错误,快速直观定位问题原因(这个需要打通上下游错误码透传)。这一点,是在快速知晓问题出在哪里。
- 按业务维度(业务身份、行业、仓储、地区等,根据实际需要决定)分类统计计算的单量、或分钟级下单数量,用于确定核心业务的单量趋势。这一点,只在知道自身业务的健康情况。
- 核心下游依赖接口、tair、db的qps、rt、错误数、成功率,需要注意的是,这个一般比较多,建议只放最核心、量最大的几个。这一点,是在知道下游依赖的健康情况。
- 其他影响系统稳定性的核心指标,如限单量,核心计数器等,根据各个团队的核心来决定。这一点,是在个性化定义关键影响点的监控情况。
3 避免监控信息爆炸
在SRE的实践过程中,为了保证监控的全面,往往会增加很多报警项,报警多了之后,就会像洪水一样,渐渐的SRE对于监控就不再敏感了,让SRE比较烦恼的一个问题,就是如何做监控报警瘦身?
目前一般来说,我们的监控报警至少包括2种方式:
- 推送到手机的报警,如电话、短信报警。
- 推送到钉钉的报警,如报警小助手、报警。
我个人的建议是:
谨慎使用电话报警
因为这会让人非常疲惫,尤其是夜间,而且容易导致接收者将电话加入骚扰拦截,当真正需要电话报警的时候,就会通知不到位;因此电话报警,一定要设置在不处理要死人的大面积/关键问题上;
设置专门的唯一的钉钉报警群
一定一定要建设专门钉钉报警群,而且1个团队只能建1个群,中间可以用多个报警机器人进行区分。报警群的目的只有1个:让所有的报警能够在这个群里通知出来。只建一个群,是为了报警集中,且利于值班同学在报警群中集中响应。
报警留底
所有报警,一定要能留底,也就是有地方可以查到历史报警,所以建议所有报警,不管最终用什么方式通知,都要在钉钉报警群里同时通知一份,这样大家只看这个群,也能查到历史报警。在进行复盘的时候,历史报警作用非常关键,可以看到问题发现时间,监控遗漏,问题恢复时间。
日常报警数量限制
一般来说,如果一段时间内,报警短信的数量超过99条,显示了99+,大家就会失去查看报警的兴趣,因此,一定要不断调整报警的阈值,使其在业务正常的情况下,不会频繁报警。在盒马履约,我们基本可以做到24小时内,报警群内的报警总数,在不出故障/风险的情况下小于100条;这样的好处是明显的,因为我们基本上可以做到1个小时以上才查看报警群,只要看到报警群的新增条数不多(比如只有10条左右),就能大致判断过去的一个小时内,没有严重的报警发生;减少报警的方法,可以采用如下手段:
- 对于系统监控报警,采用范围报警,比如load,设置集群内超过N %且机器数大于M的机器load都升高了才报警。毕竟对于一个集群而言,偶尔一台机器的load抖动,是不需要响应的。
- 对于业务报警,一定要做好同比,不但要同比昨天,还要同比上周,通过对比确认,对于一些流量不是很大的业务来说,这一点尤其重要,有些时候错误高,纯粹是ERROR级别日志过度打印,所以只要相对于昨天和上周没有明显增加,就不用报警。
- 对于qps、rt等服务报警,要注意持续性,一般来说,要考虑持续N分钟,才需要报警,偶尔的抖动,是不用报警的。当然,对于成功率下跌,异常数增加,一般要立即报出来。
- 复合报警,比如一方面要持续N分钟,一方面要同比昨天和上周,这样来减少一些无需报警的情况。
- 根据需要设置报警的阈值,避免设置>0就报警这种,这种报警没有意义,一般来说,如果一个报警,连续重复报10条以上,都没有处理,一般是这个报警的通知级别不够,但是如果一个报警,重复10条以上,经过处理人判断,不需要处理,那就肯定是这个报警的阈值有问题。
报警要能够互补
我们经常提到监控的覆盖率,但是覆盖还是不够的,因为监控可能出现多种可能性的缺失(丢日志、通信异常等),因此要能够从多个维度覆盖,比如,除了要直接用指标覆盖qps,还需要通过日志来覆盖一遍,除了要用日志覆盖一些订单趋势,还要从db统计上覆盖一遍,这样一个报警丢失,还至少有另外一个报警可以backup。
4 有效发现监控问题
作为一个SRE人员,很容易发现一个点,如果有几次线上问题或报警响应不及时,就会被老板和同事质疑。同样的,如果每次线上问题都能先于同事们发现和响应,就会赢得大家信任,那要如何做到先于大家发现呢?我的建议是:像刷抖音一样刷监控群和值班群。
一般来说,一个团队的稳定性问题在3类群里发现:BU级消防群、团队的监控报警群、业务值班群;所以没有必要红着眼睛盯着监控大盘,也没必要对每个报警都做的好像惊弓之鸟,这样很快自己就会疲惫厌烦。
我的经验是按下面的步骤:
- 首先当然是要监控治理,做到监控准确,全面,然后按照前面说的,控制报警数量,集中报警群,做到可控、合理。
- 然后像刷抖音一样,隔三差五(一般至少1个小时要有一次)刷一下报警群,如果报警群里的新增条数在20条以内,问题一般不大,刷一刷就行。
- 如果突然一段时间内报警陡增,就要看一下具体是什么问题了,小问题直接处理,大问题分工组织协调。
- 消防群中的问题,要及时同步到团队中。
- 值班群中的工单,需要关注,并有一个初步的判断:是否是大面积出现的业务反馈,是否有扩大的隐患。
要做到“有效”两个字,SRE人员,需要有一个精确的判断:当前报警是否需要处理?当前报警是否意味着问题?当前报警的影响范围和涉及人员是谁?当前工单/问题是否可能进一步扩大,不同的判断,采取的行动是不同的。
三 故障应急
前面1.4.1中,有提到如何及时、快速的响应,这一点是作为SRE人员在故障应急时的关键,也是平时处理线上问题的关键。除此之外,在应对故障方面,还有很多事情需要做。
1 系统可用性的定义
ufried 在2017年的经典弹性设计PPT:《Resilient software design in a nutshell》中,对系统可用性的定义如下:

image
可见,影响系统可用性的指标包括2个方面:MTTF(不出故障的时间)和MTTR(出故障后的恢复时间),所以,要提高系统可用性,要从2个方面入手:
- 尽量增加无故障时间
- 尽量缩短出故障后的恢复时间
对故障应急来说,也要从这两个方面入手,首先要增加无故障时间,包括日常的风险发现和风险治理,借大促机会进行的链路梳理和风险治理。只有不断的发现风险,治理风险,才能防止系统稳定性腐烂,才能增加无故障时间。
其次,要缩短出故障之后的恢复时间,这一点上,首先要把功夫花在平时,防止出现故障时的慌张无助。平时的功夫,主要就是场景梳理和故障演练。
2 场景梳理
故障场景梳理,重点在于要把可能出现故障的核心场景、表现、定位方法、应对策略梳理清楚,做到应对人员烂熟于心,为演练、故障应急提供脚本。
业务域 | 关键场景 | 问题表现 | 问题定位 | 止血措施 | 预案执行 | 业务影响 | 上游影响 | 下游影响 | 数据影响(操作人) | 服务侧、业务侧应对策略 | 产品端应对策略 |
相关域,要分别梳理上游和下游 | 服务场景,每行列出一个场景,要列出所有可能的场景 | 逐条列出当前场景的所有可能表现 | 对应前面的问题表现,列出每一个表现的定位方法和指标 | 对每个定位的原因,给出快速止血的措施 | 逐条列出可以执行的预案 | 逐条列出可能导致的业务影响和严重程度、范围 | 逐条列出在上游的影响 |
通过这种程度的梳理,SRE以及其掌控的故障应对人员,能够快速的明确发生问题的场景,以及场景下的影响、表现、定位方法、应对策略。当然,如果要把这些场景牢记,做到快速应对,就需要依靠:演练。
3 故障演练
演练对故障应急无比重要,但是,我个人十分反对把演练作为解决一切问题的手段。演练本身,应该是验证可行性和增加成熟度的方式,只能锦上添花,而不能解决问题,真正解决问题的应该是方案本身。
不要进行无场景演练
有些演练,不设置场景,纯粹考察大家的反应,这种演练,上有政策下有对策,表面上是在搞突然袭击,其实已经预设了时间段,预设了参加的域,不太可能做到完全毫无准备,到了演练的时间点,大家可以通过死盯着报警群,调整各种报警阈值的方式,更快的发现问题;而且完全无场景的演练,一般只能演练如fullGC,线程池满,机器load高,接口注入异常,对于一些数据错误,消息丢失,异步任务积压等场景,很难演练。
针对性的,我建议多进行场景演练,各域要提前进行3.2节这种详细的场景梳理,通过场景攻击,提高大家的应对成熟度。事实上,现在横向安全生产团队不对各个业务团队进行场景攻击的原因,也是因为横向安全生产团队自己也不熟悉各个业务团队的业务场景,这个就需要加强对业务场景攻击方式的规范化,横向安全生产团队也要加强机制建设,让纵向业务团队能够产出场景,而不是每次都在线程池、fullGC、磁盘空间这些方面进行攻击。
不要无意义的提速演练
演练本身虽然确实有一个重要目的是提高应对熟练度,但是不同的业务是有区别的,有些业务的发现本身,就不止1分钟(比如某些单据积压场景,消息消费场景),这些场景,如果不参加评比,或者流于形式了,就会让攻击本身没有意义。
针对性的,我建议各个业务根据各自的特点,定制演练。如:普通电商业务,关注下单成功率,有大量的实时同步调用;新零售业务,关注单据履约效率,有大量的异步调度;每个业务,根据实际场景和业务需要,制定“有各自特色的要求”的演练标准,演练不一定要千篇一律,但是一定要达到业务的需求标准。这样也更加有利于演练场景的落地,有利于蓝军针对性的制定攻击策略。
各个SRE同学,不管大的政策怎么样,还是要关注团队内部的场景本身:
- 对于系统性故障注入(load、cpu、fullGC、线程池等),直接套用集团的mk注入即可。
- 对于服务型故障注入(下游异常、超时,接口超时、限流),mk也有比较好的支持。
- 对于订单异常型故障注入,要自主开发较好的错误订单生成工具,注入异常订单,触发故障报警。
- 对于调度、积压型故障注入,要关注schedulex、异步消息的故障注入方式,同时防止积压阻塞正常订单影响真正的线上业务。
同时,在演练前后,要注意跟老板的沟通,要让老板理解到你组织的演练的目标和效果,不然就不是演习,而是演戏了。要和老板的目标契合,在演练过程中,通过演练提高大家对业务场景的理解深度和对问题的应对速度,增加大家的稳定性意识,达到“因事修人”的目的。
4 故障应急过程
如果不幸真的产生了故障,作为SRE,要记得如下信息:
- 冷静。作为SRE,首先不能慌,没有什么比尽快定位和止损更重要的事情。
- 拉电话会议同步给大家信息。记住,在出现故障时,没什么比电话会议更加高效的沟通方式了。
- 参考前面1.4.1节中的SRE人员快速响应流程,在电话会议中同步给大家:
- 尽快告知当前告警已经有人接手,是谁接手的,表明问题有人在处理了。(这一步叫“响应”)
- 组织人员,快速定位问题,告知问题初步定位原因(这一步叫“定位”)。
- 初步影响范围是什么?给出大致数据(这一步方便后面做决策)
- 有哪些需要老板、产品、业务方决策的?你的建议是什么?(这一步很关键,很多时候是:两害相权取其轻,你的评估和建议,直接影响老板的决策)
- 当前进展如何,是否已经止血?(这一步是“恢复”,要给出“进展”,让决策者和业务方了解情况)
- 组织大家按照故障场景梳理的应对方案进行应对,如果没有在故障场景列表中,一定要组织最熟练的人员进行定位和恢复。
- 故障过程中,对外通信要跟团队和老板统一评估过再说;
- 处理故障过程中,要随时组织同学们进行影响数据捞取和评估,捞出来的数据,要优先跟老板、业务熟练的同学一起评估是否有错漏。
- 在处理完故障后,要及时组织复盘(不管GOC是不是统一组织复盘,内部都要更加深刻的复盘),复盘流程至少包括:详细的时间线,详细的原因,详细的定位和解决方案,后续action和改进措施,本次故障的处理结果。
我个人其实不太赞同预案自动化和强运营的故障应急方案,这一点也是给安全生产同学的建议,比如预案自动化,有很强的局限性,只有在明确预案的执行肯定不会有问题、或者明显有优化作用的情况下,才能自动执行。否则都应该有人为判断。
强运营类的工作,会导致人走茶凉,比如GOC上自动推送的预案,故障场景关联的监控这种,一方面应该尽量减少强运营的工作,另一方面应该定期组织维护一些必要预案。
5 与兄弟团队的关系
如果兄弟团队发生故障,一定注意:
- 不能嘲笑别人,看笑话。
- 不能当没事人,高高挂起,要检查自身。
- 不能话说的太满,比如说我肯定没故障。
尤其是1和3,非常邪性,嘲笑别人的团队,或者觉得自己万事大吉,很容易沾染故障。(其实本身是由科学依据的,嘲笑别人的,一般容易放松警惕)
4 资源管控
作为一个SRE,在资源管控领域,一定要保证自己域有足够的机器,同时又不会浪费太多。我个人的建议是,核心应用,应该控制load在1-1.5左右(日常峰值或A级活动场景下),控制核心应用在10个以内,非核心应用,应该控制load在1.5-2左右(日常峰值或A级活动场景下)。目前集团很多应用load不到1,甚至只有0.几,其实很浪费的。
同时,一个团队的SRE,至少随时手上应该握有20%左右的空余额度buffer,方便随时扩容,或者应对新业务增长。这些额度,目前按照集团的预算策略,只要不真的扩容上去,都是不收费的,所以应当持有。
除了机器以外,tair、db、消息、精卫等,也要如上操作,除了年初准备好一年的预算,还要额外准备20%左右的buffer。
SRE要自己梳理一份资源表,表中一方面要明确有哪些资源,余量多少,另一方面要明确资源的当前水位、压力。
比如机器资源,要关注当前机器数、额度、load,如:

再比如对数据库资源,要关注数据库的配置、空间、日常和峰值qps、单均访问量(创建一个订单,要读和写DB多少次,这一点很关键)。

【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】