













Martin Fowler是谁?
我在之前的文章中写过,他是《重构》、《分析模式》、《企业应用架构模式》、《领域特定语言》等一系列知名书籍的作者,他很少谈论操作系统,数据库,网络这些底层的东西,也很少听他谈什么高并发,海量用户, 他也没有开发过什么知名软件,但是却被奉为软件开发的“教父”。
如果把软件分层的话,他其实生活在最上层:

这一层挤着很多程序员,因为越往下层,路越难走。必须得能耐得住寂寞,经得起诱惑,对某个领域有着极为精深的研究才可以。
但是Martin Fowler在应用层却能呼风唤雨,因为他具备一个特殊的能力:擅长把一些软件开发实践总结成“概念”。
很明显,这需要极强的抽象能力。
Martin Fowler最为知名的作品可能就是《重构》,他把软件编程中各种修改代码的方法抽象、总结、命名,影响了全世界每一个开发人员。
他还有一本书叫《企业应用架构模式》, Martin Fowler把企业应用开发中的一些最佳实践分门别类地总结了出来。
比如讲领域逻辑模式的“事务脚本”,“表模块”,“领域模型”,“Service Layer” 等。
讲ORM的“单表继承”,“类表继承”,“活动记录”等。
Martin Fowler 绝对是在应用层开发的程序员的榜样!
前天在浏览Martin Fowler的个人网站(https://martinfowler.com/)时,发现了这么一个宝贝:“分布式系统模式”(Patterns of Distributed Systems)。
我不由得心头一喜:看来Martin Fowler没闲着,又开始整理模式了,这一次更加宏观,直接进入了分布式系统!
但仔细一看,略有失望,不是Martin Fowler亲自操刀的!是一位叫做Unmesh Joshi 的ThoughtWorks顾问写的,Martin Fowler给了一些模式方面的指导和帮助。
这两天看了一下,我觉得质量还是挺高的,比如开篇先讲了分布式系统的几个通用问题:
- 进程崩溃
- 网络延迟
- 进程暂停
- 非同步的时钟
进而引出分布式系统的模式是如何解决这些问题的 。
比如非常经典的Write-Ahead Log 模式,可以用来解决进程崩溃时数据的持久化问题:
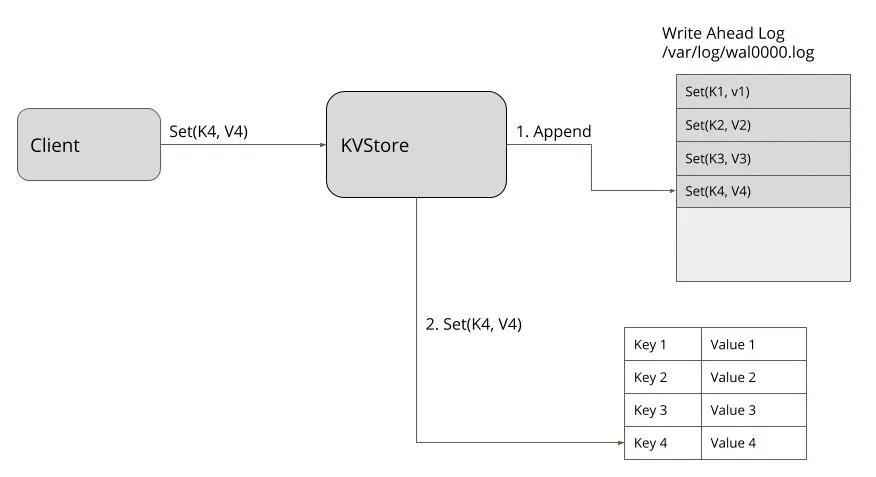
先把数据当作Command放入持久化的日志文件中,这样即使KVStore进程崩溃,在重启以后依然可以从日志中恢复数据。
人家很清楚程序员的交流语言是代码, 所以马上给出了简单的代码片段来帮助理解细节,真是很贴心。
- class KVStore…
- public KVStore(Config config) {
- this.config = config;
- this.wal = WriteAheadLog.openWAL(config);
- this.applyLog();
- }
- public void applyLog() {
- List<WALEntry> walEntries = wal.readAll();
- applyEntries(walEntries);
- }
- private void applyEntries(List<WALEntry> walEntries) {
- for (WALEntry walEntry : walEntries) {
- Command command = deserialize(walEntry);
- if (command instanceof SetValueCommand) {
- SetValueCommand setValueCommand = (SetValueCommand)command;
- kv.put(setValueCommand.key, setValueCommand.value);
- }
- }
- }
- public void initialiseFromSnapshot(SnapShot snapShot) {
- kv.putAll(snapShot.deserializeState());
- }
现在已经整理出来的分布式系统模式有这些:

为什么向大家推荐这个资料呢?是因为网上有很多分布式理论的文章,干巴巴的,看不了一页就想放弃。
网上也有很多源码分析的文章,专注于贴代码,纠缠于细节,让人云里雾里。
Unmesh Joshi的分布式系统模式则是个很好的平衡:既有理论,又有代码细节。
如果你是一个刚入行的新手,看这些东西可能有些吃力,因为需要有分布式系统的基础,不妨先收藏,等待以后再看。
如果是一个经验丰富的老手,我强烈推荐你去看一看,观摩下这些大牛们是怎么从各种复杂的场景中抽取出通用的模式的,绝对受益非浅, 你可能有这样的感觉:这种工作我怎么就没想到呢?
当然,这是英文的材料, 会有一定的障碍,不过你看了就知道,并没有用什么高级的词汇,我列几句大家感受感受:
Processes can crash at any time. Either due to hardware faults or software faults. There are numerous ways in which a process can crash.
It can be taken down for routine maintenance by system administrators.
It can be killed doing some file IO because the disk is full and the exception is not properly handled.
并不难,对吧?尝试看一下吧,阅读英文资料也是一项重要的技能。
链接在此:https://martinfowler.com/articles/patterns-of-distributed-systems/

【本文为51CTO专栏作者“刘欣”的原创稿件,转载请通过作者微信公众号coderising获取授权】























