在百花齐放的交互式分析领域,ClickHouse 绝对是后起之秀,它虽然年轻,却有非常大的发展空间。
图片来自 Pexels
本文将分享 PB 级分析型数据库 ClickHouse 的应用场景、整体架构、众多核心特性等,帮助理解 ClickHouse 如何实现极致性能的存储引擎,希望与大家一起交流。
交互式分析之 ClickHouse
交互式分析简介
交互式分析,也称 OLAP(Online Analytical Processing),它赋予用户对海量数据进行多维度、交互式的统计分析能力,以充分利用数据的价值进行量化运营、辅助决策等,帮助用户提高生产效率。
交互式分析主要应用于统计报表、即席查询(Ad Hoc)等领域,前者查询模式较固定,后者即兴进行探索分析。
代表场景例如:移动互联网中 PV、UV、活跃度等典型实时报表;互联网内容领域中人群洞察、关联分析等即席查询。
交互式分析是数据分析的一种重要方式,与离线分析、流式分析、检索分析一起,共同组成完整的数据分析解决方案,在互联网、物联网快速发展的背景下,从不同维度满足用户对海量数据的全方位分析需求。
相比专注于事务处理的传统关系型数据库,交互式分析解决了 PB 级数据分析带来的性能、扩展性问题。
相比离线分析长达 T+1 的时效性、流式分析较为固定的分析模式、检索分析受限的分析性能,交互式分析的分钟级时效性、灵活多维度的分析能力、超高性能的扫描分析性能,可以大幅度提高数据分析的效率,拓展数据分析的应用范围。

从数据访问特性角度来看,交互式分析场景具有如下典型特点:
- 大多数访问是读请求。
- 写入通常为追加写,较少更新、删除操作。
- 读写不关注事务、强一致等特性。
- 查询通常会访问大量的行,但仅部分列是必须的。
- 查询结果通常明显小于访问的原始数据,且具有可理解的统计意义。
百花齐放下的 ClickHouse
近十年,交互式分析领域经历了百花齐放式的发展,大量解决方案爆发式涌现,尚未有产品达到类似 Oracle/MySQL 在关系型数据库领域中绝对领先的状态。
业界提出的开源或闭源的交互式解决方案,主要从大数据、NoSQL 两个不同的方向进行演进,以期望提供用户最好的交互式分析体验。
下图所示是不同维度下的代表性解决方案,供大家参考了解:
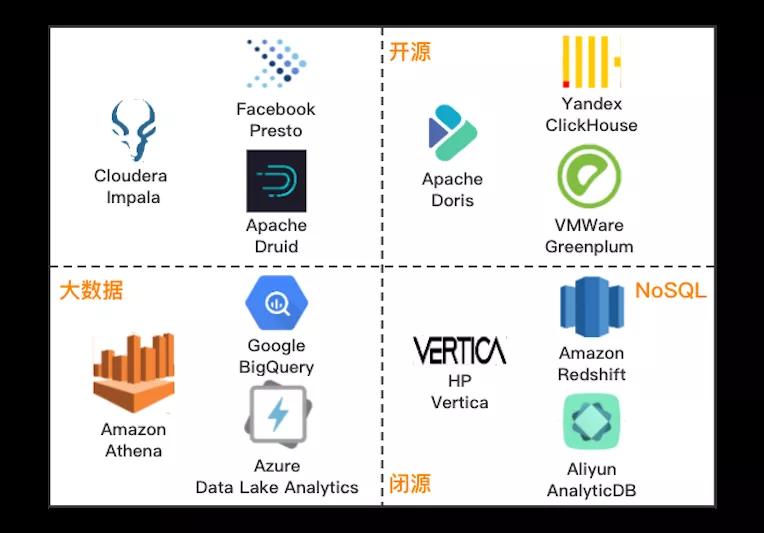
其中,ClickHouse 作为一款 PB 级的交互式分析数据库,最初是由号称 “ 俄罗斯 Google ” 的 Yandex 公司开发,主要作为世界第二大 Web 流量分析平台 Yandex.Metrica(类 Google Analytic、友盟统计)的核心存储,为 Web 站点、移动 App 实时在线的生成流量统计报表。
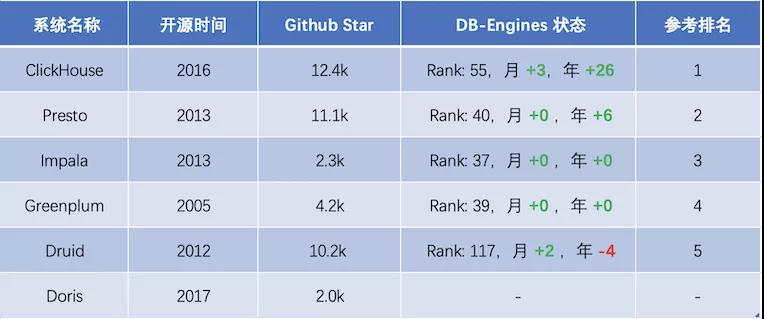
自 2016 年开源以来,ClickHouse 凭借其数倍于业界顶尖分析型数据库的极致性能,成为交互式分析领域的后起之秀,发展速度非常快,Github 上获得 12.4K Star,DB-Engines 排名近一年上升 26 位,并获得思科、Splunk、腾讯、阿里等顶级企业的采用。
下面是 ClickHouse 及其他开源 OLAP 产品的发展趋势统计:
性能是衡量 OLAP 数据库的关键指标,我们可以通过 ClickHouse 官方测试结果感受下 ClickHouse 的极致性能,其中绿色代表性能最佳,红色代表性能较差,红色越深代表性能越弱。
从测试结果看,ClickHouse 几乎在所有场景下性能都最佳,并且从所有查询整体看,ClickHouse 领先图灵奖得主 Michael Stonebraker 所创建的 Vertica 达 6 倍,领先 Greenplum 达到 18 倍。
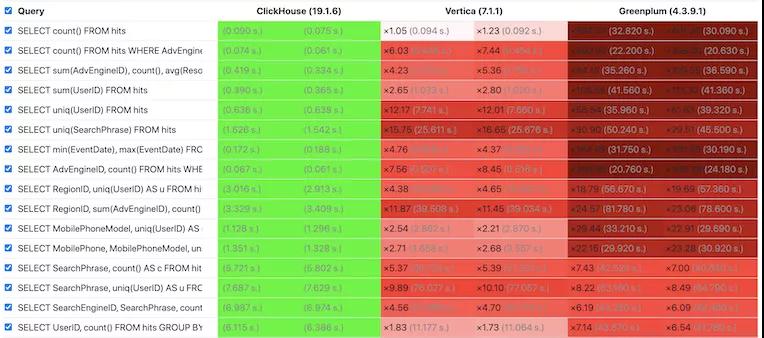
更多测试结果可参考 OLAP 系统第三方评测 ,尽管该测试使用了无索引的表引擎(或称表类型),ClickHouse 仍然在单表模式下体现了强劲的领先优势。
ClickHouse 架构
集群架构
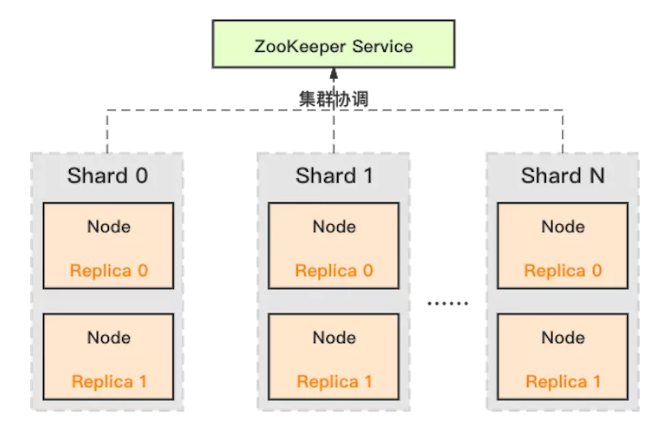
ClickHouse 采用典型的分组式的分布式架构,具体集群架构如上图所示:
- Shard:集群内划分为多个分片或分组(Shard 0 … Shard N),通过 Shard 的线性扩展能力,支持海量数据的分布式存储计算。
- Node:每个 Shard 内包含一定数量的节点(Node,即进程),同一 Shard 内的节点互为副本,保障数据可靠。ClickHouse 中副本数可按需建设,且逻辑上不同 Shard 内的副本数可不同。
- ZooKeeper Service:集群所有节点对等,节点间通过 ZooKeeper 服务进行分布式协调。
数据模型
ClickHouse 采用经典的表格存储模型,属于结构化数据存储系统。我们分别从面向用户的逻辑数据模型和面向底层存储的物理数据模型进行介绍。
①逻辑数据模型
从用户使用角度看,ClickHouse 的逻辑数据模型与关系型数据库有一定的相似:一个集群包含多个数据库,一个数据库包含多张表,表用于实际存储数据。
与传统关系型数据库不同的是,ClickHouse 是分布式系统,如何创建分布式表呢?
ClickHouse 的设计是:先在每个 Shard 每个节点上创建本地表(即 Shard 的副本),本地表只在对应节点内可见;然后再创建分布式表,映射到前面创建的本地表。
这样用户在访问分布式表时,ClickHouse 会自动根据集群架构信息,把请求转发给对应的本地表。
创建分布式表的具体样例如下:
# 首先,创建本地表
CREATE TABLE table_local ON CLUSTER cluster_test
(
OrderKey UInt32, # 列定义
OrderDate Date,
Quantity UInt8,
TotalPrice UInt32,
……
)
ENGINE = MergeTree() # 表引擎
PARTITION BY toYYYYMM(OrderDate) # 分区方式
ORDER BY (OrderDate, OrderKey); # 排序方式
SETTINGS index_granularity = 8192; # 数据块大小
# 然后,创建分布式表
CREATE TABLE table_distribute ON CLUSTER cluster_test AS table_local
ENGINE = Distributed(cluster_test, default, table_local, rand()) # 关系映射引擎
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
其中部分关键概念介绍如下,分区、数据块、排序等概念会在物理存储模型部分展开介绍:
- MergeTree:ClickHouse 中使用非常多的表引擎,底层采用 LSM Tree 架构,写入生成的小文件会持续 Merge。
- Distributed:ClickHouse 中的关系映射引擎,它把分布式表映射到指定集群、数据库下对应的本地表上。
更直观的,ClickHouse 中的逻辑数据模型如下:
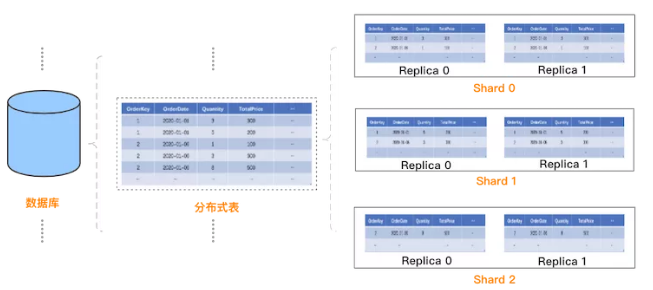
②物理存储模型
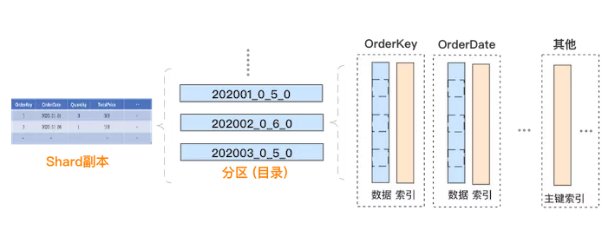
接下来,我们来介绍每个分片副本内部的物理存储模型,具体如下:
- 数据分区:每个分片副本的内部,数据按照 PARTITION BY 列进行分区,分区以目录的方式管理,本文样例中表按照时间进行分区。
- 列式存储:每个数据分区内部,采用列式存储,每个列涉及两个文件,分别是存储数据的 .bin 文件和存储偏移等索引信息的 .mrk2 文件。
- 数据排序:每个数据分区内部,所有列的数据是按照 ORDER BY 列进行排序的。可以理解为:对于生成这个分区的原始记录行,先按 ORDER BY 列进行排序,然后再按列拆分存储。
- 数据分块:每个列的数据文件中,实际是分块存储的,方便数据压缩及查询裁剪,每个块中的记录数不超过 index_granularity,默认 8192。
- 主键索引:主键默认与 ORDER BY 列一致,或为 ORDER BY 列的前缀。由于整个分区内部是有序的,且切割为数据块存储,ClickHouse 抽取每个数据块第一行的主键,生成一份稀疏的排序索引,可在查询时结合过滤条件快速裁剪数据块。
ClickHouse 核心特性
ClickHouse 为什么会有如此高的性能,获得如此快速的发展速度?下面我们来从 ClickHouse 的核心特性角度来进一步介绍。
列存储
ClickHouse 采用列存储,这对于分析型请求非常高效。
一个典型且真实的情况是:如果我们需要分析的数据有 50 列,而每次分析仅读取其中的 5 列,那么通过列存储,我们仅需读取必要的列数据。
相比于普通行存,可减少 10 倍左右的读取、解压、处理等开销,对性能会有质的影响。
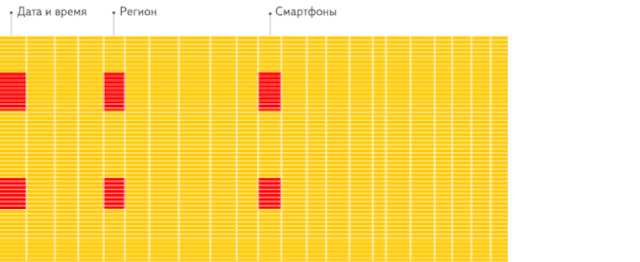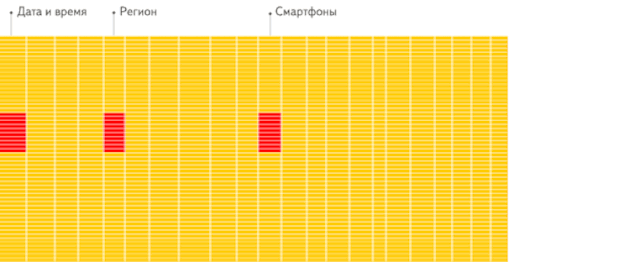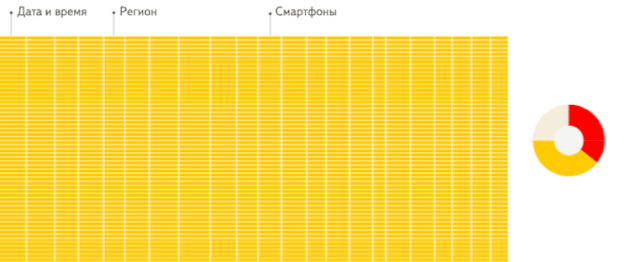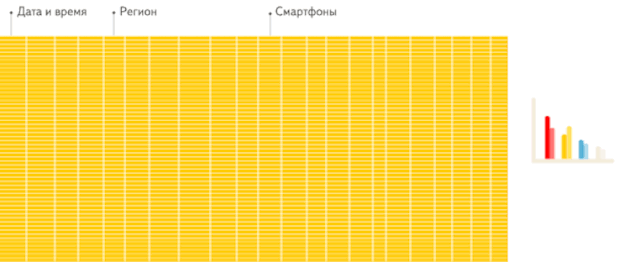
这是分析场景下,列存储数据库相比行存储数据库的重要优势。这里引用 ClickHouse 官方一个生动形象的动画,方便大家理解。
行存储:从存储系统读取所有满足条件的行数据,然后在内存中过滤出需要的字段,速度较慢。
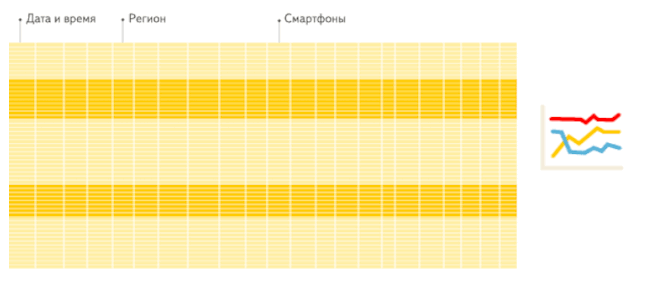
列存储:仅从存储系统中读取必要的列数据,无用列不读取,速度非常快。
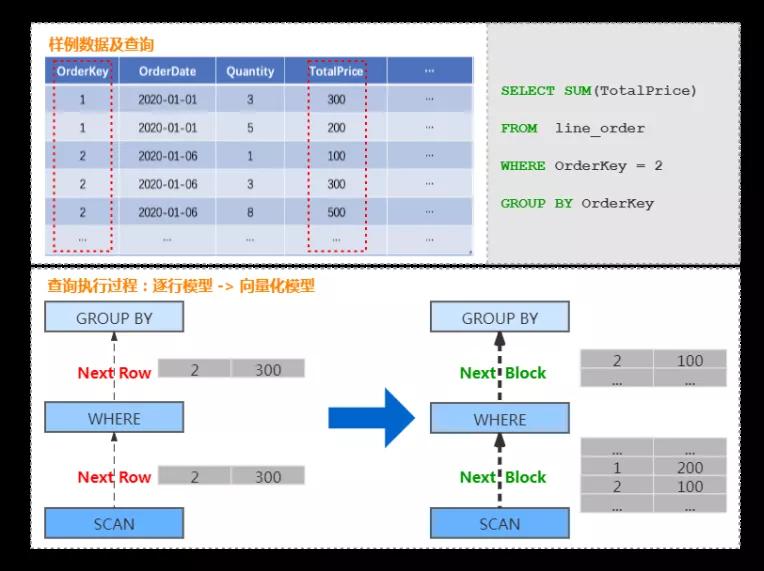
向量化执行
在支持列存的基础上,ClickHouse 实现了一套面向向量化处理的计算引擎,大量的处理操作都是向量化执行的。
相比于传统火山模型中的逐行处理模式,向量化执行引擎采用批量处理模式,可以大幅减少函数调用开销,降低指令、数据的 Cache Miss,提升 CPU 利用效率。
并且 ClickHouse 可利用 SIMD 指令进一步加速执行效率。这部分是 ClickHouse 优于大量同类 OLAP 产品的重要因素。
以商品订单数据为例,查询某个订单总价格的处理过程,由传统的按行遍历处理的过程,转换为按 Block 处理的过程。
具体如下图:
编码压缩
由于 ClickHouse 采用列存储,相同列的数据连续存储,且底层数据在存储时是经过排序的,这样数据的局部规律性非常强,有利于获得更高的数据压缩比。
此外,ClickHouse 除了支持 LZ4、ZSTD 等通用压缩算法外,还支持 Delta、DoubleDelta、Gorilla 等专用编码算法,用于进一步提高数据压缩比。
其中 DoubleDelta、Gorilla 是 Facebook 专为时间序数据而设计的编码算法,理论上在列存储环境下,可接近专用时序存储的压缩比,详细可参考 Gorilla 论文。
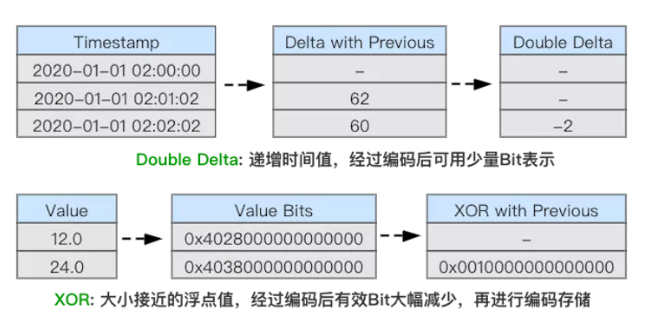
在实际场景下,ClickHouse 通常可以达到 10:1 的压缩比,大幅降低存储成本。
同时,超高的压缩比又可以降低存储读取开销、提升系统缓存能力,从而提高查询性能。
多索引
列存用于裁剪不必要的字段读取,而索引则用于裁剪不必要的记录读取。ClickHouse 支持丰富的索引,从而在查询时尽可能的裁剪不必要的记录读取,提高查询性能。
ClickHouse 中最基础的索引是主键索引。前面我们在物理存储模型中介绍,ClickHouse 的底层数据按建表时指定的 ORDER BY 列进行排序,并按 index_granularity 参数切分成数据块,然后抽取每个数据块的第一行形成一份稀疏的排序索引。
用户在查询时,如果查询条件包含主键列,则可以基于稀疏索引进行快速的裁剪。
这里通过下面的样例数据及对应的主键索引进行说明:

样例中的主键列为 CounterID、Date,这里按每 7 个值作为一个数据块,抽取生成了主键索引 Marks 部分。
当用户查询 CounterID equal ‘h’ 的数据时,根据索引信息,只需要读取 Mark number 为 6 和 7 的两个数据块。
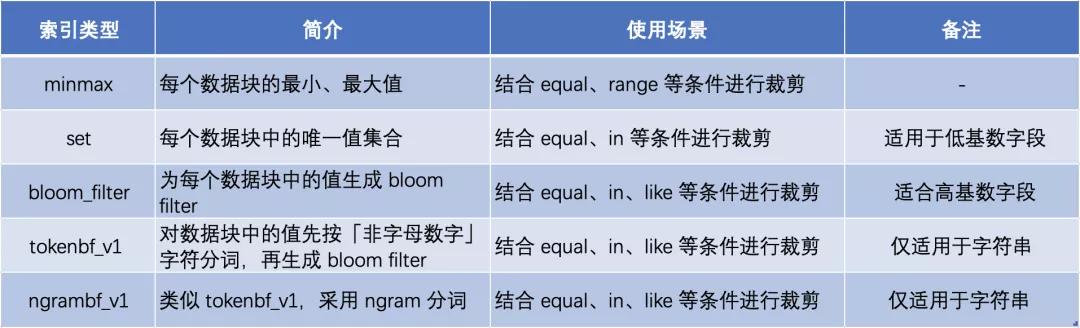
ClickHouse 支持更多其他的索引类型,不同索引用于不同场景下的查询裁剪,具体汇总如下,更详细的介绍参考 ClickHouse 官方文档:
物化视图(Cube/Rollup)
OLAP 分析领域有两个典型的方向:
- 一是 ROLAP,通过列存、索引等各类技术手段,提升查询时性能。
- 另一是 MOLAP,通过预计算提前生成聚合后的结果数据,降低查询读取的数据量,属于计算换性能方式。
前者更为灵活,但需要的技术栈相对复杂;后者实现相对简单,但要达到的极致性能,需要生成所有常见查询对应的物化视图,消耗大量计算、存储资源。
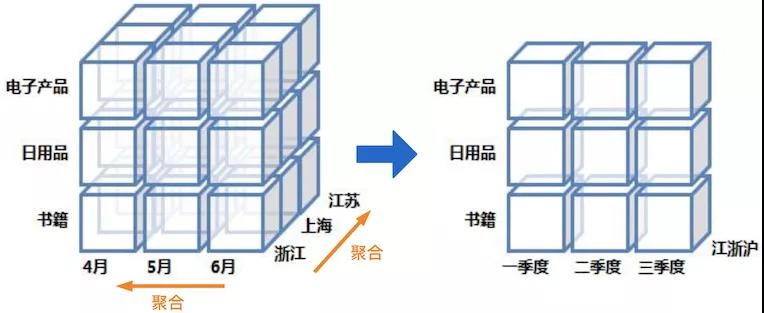
物化视图的原理如下图所示,可以在不同维度上对原始数据进行预计算汇总:
ClickHouse 一定程度上做了两者的结合,在尽可能采用 ROLAP 方式提高性能的同时,支持一定的 MOLAP 能力,具体实现方式为 MergeTree 系列表引擎和 MATERIALIZED VIEW。
事实上,Yandex.Metrica 的存储系统也经历过使用纯粹 MOLAP 方案的发展过程,具体参考 ClickHouse的发展历史。
用户在使用时,可优先按照 ROLAP 思路进行调优,例如主键选择、索引优化、编码压缩等。
当希望性能更高时,可考虑结合 MOLAP 方式,针对高频查询模式,建立少量的物化视图,消耗可接受的计算、存储资源,进一步换取查询性能。
其他特性
除了前面所述,ClickHouse 还有非常多其他特性,抽取列举如下,更多详细内容可参考 ClickHouse官方文档:
- SQL 方言:在常用场景下,兼容 ANSI SQL,并支持 JDBC、ODBC 等丰富接口。
- 权限管控:支持 Role-Based 权限控制,与关系型数据库使用体验类似。
- 多机多核并行计算:ClickHouse 会充分利用集群中的多节点、多线程进行并行计算,提高性能。
- 近似查询:支持近似查询算法、数据抽样等近似查询方案,加速查询性能。
- Colocated Join:数据打散规则一致的多表进行 Join 时,支持本地化的 Colocated Join,提升查询性能。
- ……
ClickHouse 的不足
前面介绍了大量 ClickHouse 的核心特性,方便读者了解 ClickHouse 高性能、快速发展的背后原因。
当然,ClickHouse 作为后起之秀,远没有达到尽善尽美,还有不少需要待完善的方面,典型代表如下:
分布式管控
分布式系统通常包含三个重要组成部分:
- 存储引擎
- 计算引擎
- 分布式管控层
ClickHouse 有一个非常突出的高性能存储引擎,但在分布式管控层显得较为薄弱,使得运营、使用成本偏高。
主要体现在:
①分布式表
ClickHouse 对分布式表的抽象并不完整,在多数分布式系统中,用户仅感知集群和表,对分片和副本的管理透明,而在 ClickHouse 中,用户需要自己去管理分片、副本。
例如前面介绍的建表过程:用户需要先创建本地表(分片的副本),然后再创建分布式表,并完成分布式表到本地表的映射。
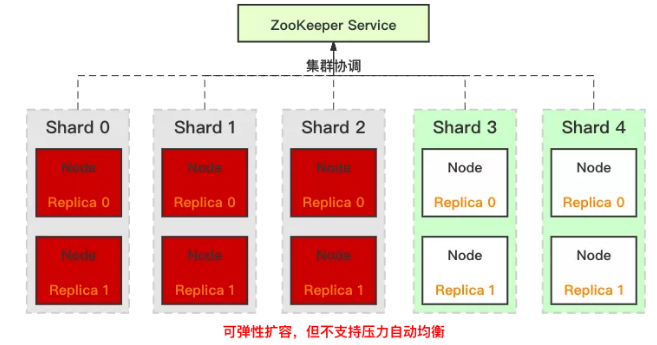
②弹性伸缩
ClickHouse 集群自身虽然可以方便的水平增加节点,但并不支持自动的数据均衡。
例如,当包含 6 个节点的线上生产集群因存储或计算压力大,需要进行扩容时,我们可以方便的扩容到 10 个节点。
但是数据并不会自动均衡,需要用户给已有表增加分片或者重新建表,再把写入压力重新在整个集群内打散,而存储压力的均衡则依赖于历史数据过期。
ClickHouse在弹性伸缩方面的不足,大幅增加了业务在进行水平伸缩时运营压力。
基于 ClickHouse 的当前架构,实现自动均衡相对复杂,导致相关问题的根因在于 ClickHouse 分组式的分布式架构:同一分片的主从副本绑定在一组节点上。
更直接的说,分片间数据打散是按照节点进行的,自动均衡过程不能简单的搬迁分片到新节点,会导致路由信息错误。
而创建新表并在集群中进行全量数据重新打散的方式,操作开销过高。
③故障恢复
与弹性伸缩类似,在节点故障的情况下,ClickHouse 并不会利用其它机器补齐缺失的副本数据。需要用户先补齐节点后,然后系统再自动在副本间进行数据同步。
计算引擎
虽然 ClickHouse 在单表性能方面表现非常出色,但是在复杂场景仍有不足,缺乏成熟的 MPP 计算引擎和执行优化器。
例如:多表关联查询、复杂嵌套子查询等场景下查询性能一般,需要人工优化;缺乏 UDF 等能力,在复杂需求下扩展能力较弱等。
这也和 OLAP 系统第三方评测的结果相符。这对于性能如此出众的存储引擎来说,非常可惜。
实时写入
ClickHouse 采用类 LSM Tree 架构,并且建议用户通过批量方式进行写入,每个批次不少于 1000 行 或 每秒钟不超过一个批次,从而提高集群写入性能。
实际测试情况下,32 vCPU&128G 内存的情况下,单节点写性能可达 50 MB/s~200 MB/s,对应 5w~20w TPS。
但 ClickHouse 并不适合实时写入,原因在于 ClickHouse 并非典型的 LSM Tree 架构,它没有实现 Memory Table 结构,每批次写入直接落盘作为一棵 Tree(如果单批次过大,会拆分为多棵 Tree),每条记录实时写入会导致底层大量的小文件,影响查询性能。
这使得 ClickHouse 不适合有实时写入需求的业务,通常需要在业务和 ClickHouse 之间引入一层数据缓存层,实现批量写入。
结语
本文重点分享了 ClickHouse 的整体架构及众多核心特性,分析了 ClickHouse 如何实现极致性能的存储引擎,从而成为 OLAP 领域的后起之秀。
ClickHouse 仍然年轻,虽然在某些方面存在不足,但极致性能的存储引擎,使得 ClickHouse 成为一个非常优秀的存储底座。
后续我们会在不断拓展业务的同时,优先从分布式管控层和计算引擎层着手,持续优化 ClickHouse 的易用性、性能,打造业界领先的 OLAP 分析数据库。
同时,我们会持续输出内核优化、最佳实践等经验,欢迎更多技术爱好者们一起探索、交流。
参考资料:
- 采用文档:
https://clickhouse.tech/docs/zh/introduction/adopters/
- ClickHouse 官方测试结果:
https://clickhouse.tech/benchmark/dbms/
- OLAP 系统第三方评测:
http://www.clickhouse.com.cn/topic/5c453371389ad55f127768ea
- 专用编码算法支持:
https://clickhouse.tech/docs/zh/sql-reference/statements/create/#codecs
- Gorilla 论文:
http://www.vldb.org/pvldb/vol8/p1816-teller.pdf
- 索引支持:
https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/mergetree/#table_engine-mergetree-data_skipping-indexes
- MergeTree系列表引擎:
https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/mergetree/
- MATERIALIZED VIEW:
https://clickhouse.tech/docs/en/sql-reference/statements/create/view/#materialized
- ClickHouse的发展历史:
https://clickhouse.tech/docs/en/introduction/history/
- ClickHouse官方文档:
https://clickhouse.tech/docs/en/
作者:姜国强
简介:腾讯实时检索研发工程师
编辑:陶家龙
出处:转载自公众号云加社区(ID:QcloudCommunity)