












为什么这么设计(Why’s THE Design)是一系列关于计算机领域中程序设计决策的文章,我们在这个系列的每一篇文章中都会提出一个具体的问题并从不同的角度讨论这种设计的优缺点、对具体实现造成的影响。如果你有想要了解的问题,可以在文章下面留言。
非一致性内存访问(Non-Uniform Memory Access、NUMA)是一种计算机内存的设计方式[^1],与 NUMA 相对的还有一致性内存访问(Uniform Memory Access、UMA),也被称作对称多处理器架构(Symmetric Multi-Processor、SMP),早期的计算机都会使用 SMP,然而现代的多数计算机都会采用 NUMA 架构管理 CPU 和内存资源。
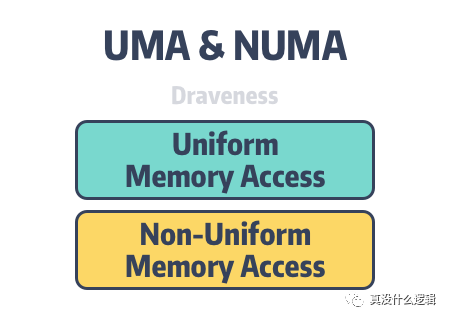
uma-and-numa
图 1 - UMA 和 NUMA
作为应用程序的开发者,因为操作系统为我们屏蔽了很多硬件层面的实现细节,所以不太需要直接接触硬件,不过因为 NUMA 会影响应用程序,所以想要写出高性能、低延迟的服务,NUMA 是我们必须要了解并熟悉的,本文将从以下两个方面介绍它的影响:
- NUMA 引入了本地内存和远程内存,CPU 访问本地内存的延迟会小于访问远程内存;
- NUMA 的内存分配与内存回收策略结合时会可能会导致 Linux 的频繁交换分区(Swap)进而影响系统的稳定性;
本地内存
如果主机使用 NUMA 这种架构设计,那么 CPU 访问本地内存的延迟会小于访问远程内存,这种现象并不是 CPU 设计者刻意制造的,而是物理层面的限制。不过 NUMA 这种设计并不是与计算机一同诞生的,我们在继续分析 NUMA 对程序的影响之前先来分析一下 CPU 架构的演进过程。
在计算机诞生的最初几十年,处理器基本都是单核的,根据摩尔定律,随着技术的进步,处理器的性能每隔两年就会翻一倍[^2],这一定律在上个世纪基本都是生效的,然而在过去十几年,单个处理器中晶体管数目的增加速度逐渐放缓,很多厂商开始推出了双核以及多核的计算机。
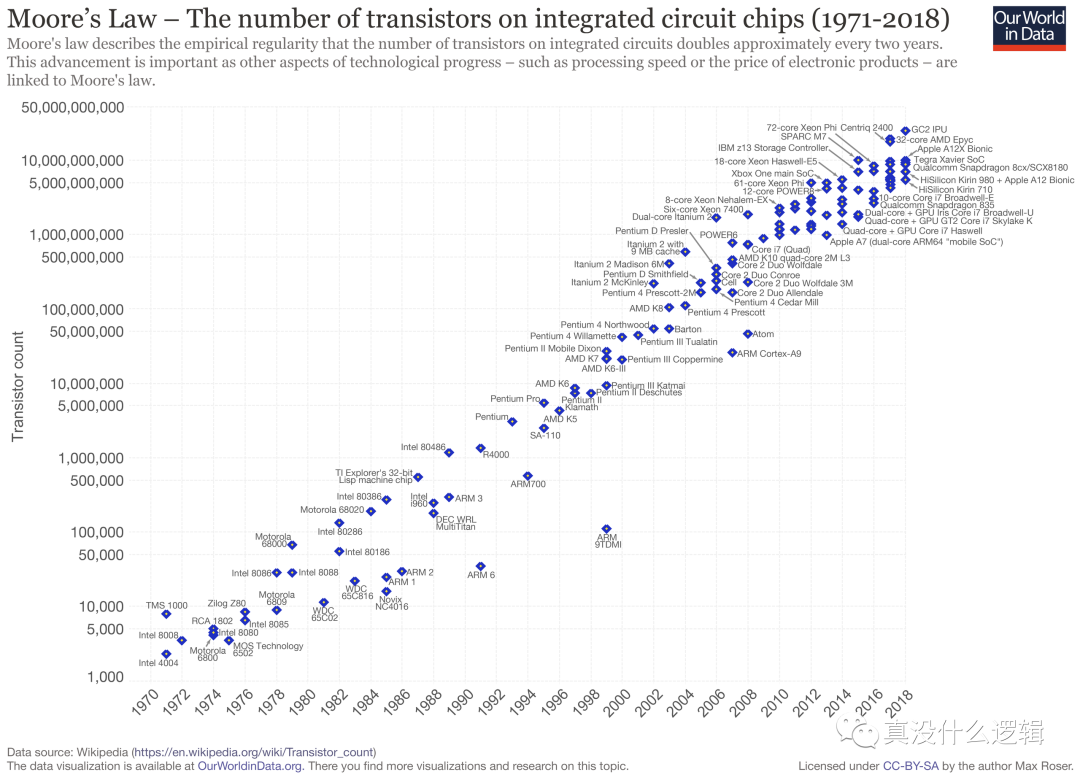
moores-law
图 2 - 摩尔定律
单核或者多核计算机上的 CPU 最早会通过前端总线(Front-side bus)、北桥(Northbridge)和内存总线(Memory bus)访问内存槽中的内存,所有的 CPU 会通过相同的总线访问相同的内存以及 I/O 设备,计算机中的所有资源都是共享的,这种架构被称作对称多处理器架构(Symmetric Multi-Processor、SMP),也被称为一致存储器访问结构(Uniform Memory Access、UMA)。
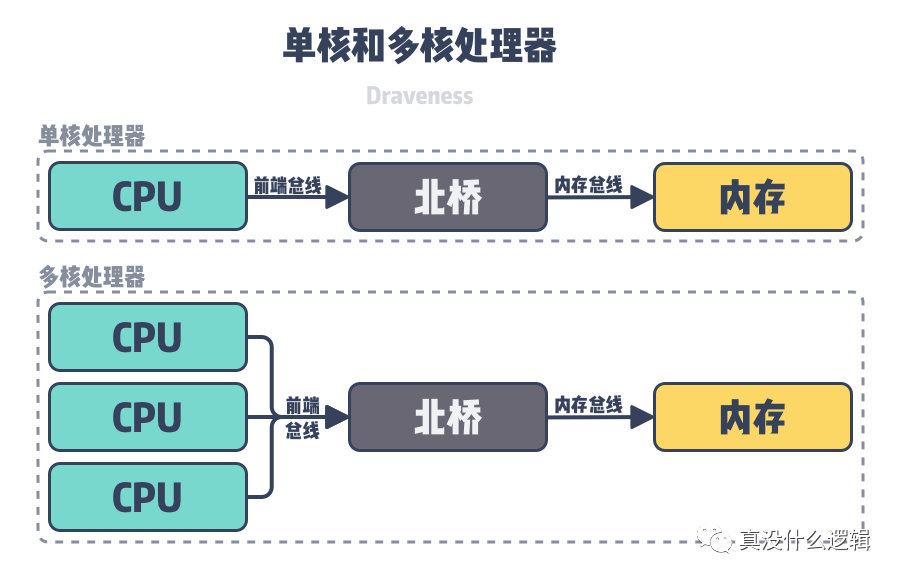
single-and-multi-core
图 3 - 单核和多核处理器
然而随着计算机中 CPU 数量的增加,多个 CPU 都需要通过总线和北桥访问内存,当同一个主机中包含几十个 CPU 时,总线和北桥两个模块成为了系统的瓶颈,为了解决这一问题,CPU 架构的设计者使用如下所示的多个 CPU 模块解决了这个问题:
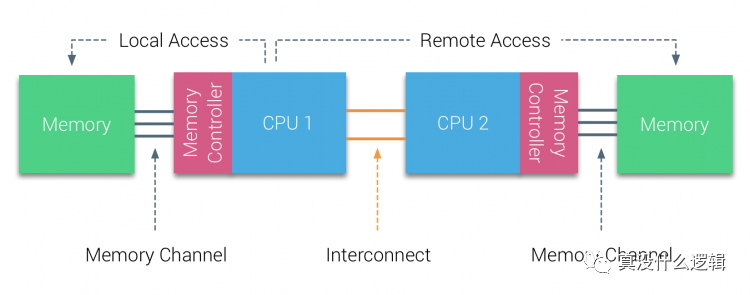
numa-local-remote-access
图 4 - 双节点 NUMA 架构
如上图所示,该主机中包含 2 个 NUMA 节点,每个 NUMA 节点都包含物理 CPU 和内存,从图中我们可以看出 CPU 1 访问本地内存和远程内存会经过不同的通道,这是访问内存时间不同的根本原因。
操作系统作为管理计算机硬件、软件资源并为应用程序提供通用服务的软件,它本身就会与底层的硬件打交道,Linux 操作系统就会为我们提供硬件相关的 NUMA 信息,你可以直接通过 numactl 命令查看机器上的 NUMA 节点[^3]:
- $ numactl -H
- available: 2 nodes (0-1)
- node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35
- node 0 size: 63539 MB
- node 0 free: 18566 MB
- node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45 46 47
- node 1 size: 64485 MB
- node 1 free: 20716 MB
- node distances:
- node 0 1
- 0: 10 21
- 1: 21 10
从上述输出结果我们可以看出,该机器上包含两个 NUMA 节点,每个节点上都包含 24 个 CPU 以及 64GB 的内存,最后的节点距离(node distances)告诉我们两个 NUMA 节点访问内存的开销,其中 NUMA 节点 0 和 NUMA 节点 1 互相访问对方内存的延迟是各自节点访问本地内存的 2.1 倍(21 / 10 = 2.1),所以如果 NUMA 节点 0 上的进程如果在节点 1 上分配内存,会增加进程的延迟。
正是因为 NUMA 节点访问不同内存的开销不同,所以操作系统会为应用程序提供接口控制 CPU 和内存的分配策略,在 Linux 系统中,我们可以使用 numactl 命令控制进程使用的 CPU 和内存。
numactl 提供了 cpunodebind 和 physcpubind 两种策略为进程分配 CPU,这两种策略分别提供了不同粒度的绑定方法:
- cpunodebind — 将进程绑定到某几个 NUMA 节点上;
- physcpubind — 将进程绑定到某几个物理 CPU 上;
除了这两种 CPU 分配策略之外,numactl 还提供四种不同的内存分配策略,分别是:localalloc、preferred、membind 和 interleave:
- localalloc — 总是在当前节点上分配内存;
- preferred — 倾向于在特定节点上分配内存,当指定节点的内存不足时,操作系统会在其他节点上分配;
- membind — 只能在传入的几个节点上分配内存,当指定节点的内存不足时,内存的分配就会失败;
- interleave — 内存会在传入的节点上依次分配(Round Robin),当指定节点的内存不足时,操作系统会在其他节点上分配;
上述的两种 CPU 分配策略和四种内存分配策略是我们与 NUMA 打交道时经常需要接触的,当进程的性能受到 NUMA 的影响时,我们可能需要通过 numactl 命令调整 CPU 或者内存的分配策略。
交换分区
NUMA 架构虽然能够解决总线上的性能瓶颈并可以让我们在同一个主机上运行更多的 CPU,但是如果不了解 NUMA 的工作原理或者使用错误的策略会带来一些问题,Jeremy Cole 的文章 The MySQL “swap insanity” problem and the effects of the NUMA architecture 就曾经分析过 NUMA 架构下 MySQL 可能出现的问题 — 频繁发生的交换分区影响服务延迟[^4],我们在这里简单介绍一下该问题背后的原因:
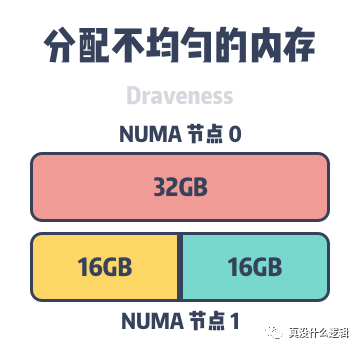
uneven-memory-node
图 5 - 分配不均匀的内存
因为 MySQL 等数据库的运行会占用大量的内存,在默认情况进程会先在所在的 NUMA 节点上分配内存,当本地内存不足时,才会在远程分配内存。如上图所示,主机上包含两个 NUMA 节点,其中每个节点都有 32GB 的内存,但是当 MySQL InnoDB 的缓存池占用 48GB 的内存时,它会在 NUMA 节点 0 和 NUMA 节点 1 分别分配 32GB 和 16GB 的内存。
虽然 48GB 的内存远远没有到达主机 64GB 的内存上限,但是当某些数据必须要在 NUMA 节点 0 的内存上分配时,就会导致 NUMA 节点 0 中的内存被交换到了文件系统上为新的内存请求让出位置[^5],InnoDB 缓存池中内存的频繁换入和换出会使 MySQL 的查询随机地出现延迟,而一旦发生了交换分区,可能就是性能螺旋下降的开始。
Linux 中的 zone_reclaim_mode 可以允许工程师设置在 NUMA 节点内存不足时内存的回收策略,在默认情况下该模式都会处于关闭状态[^6],如果我们在 NUMA 系统中通过该配置启用了激进的内存回收策略,可能会影响程序的性能[^7],MySQL 也会受到内存回收策略的影响,但是仅仅关闭该策略并不会解决它遇到的频繁触发交换分区的问题[^8]。
- $ cat /proc/sys/vm/zone_reclaim_mode
- 0
想要解决该问题,我们需要使用上一节提到的 numactl 将内存的分配策略改为 interleave,使用该内存分配策略会使得 MySQL 的内存均匀地分配到不同的 NUMA 节点上,能够降低页面频繁换入换出的可能性。

even-memory-node
图 6 - 分配均匀的内存
该问题并不是 MySQL 独有的,很多占用大量内存的数据库都会遇到上述问题,虽然使用 interleave 能够暂时解决这些问题,但是 MySQL 进程访问远程内存时,与本地内存相比仍然会遇到性能损失,想要一劳永逸地避免服务在 NUMA 上运行的额外开销,最好的办法还是开发能够感知底层 NUMA 架构的应用程序。以 MySQL 为例,Jeremy Cole 在文章中提出了如下的修改,可以更好地利用 NUMA 的本地内存[^9]:
- 将缓存池中的数据按照块或者索引智能地分配到不同节点上;
- 为正常的查询线程保留默认的分配策略,内存还是会优先分配本地节点上;
- 将简单的查询线程重新调度到能够访问本地内存的节点上;
除了 MySQL 可以利用 NUMA 来提高性能之外,一些框架或者编程语言也可以通过感知底层的 NUMA 信息来提升服务的响应速度,例如 Go 语言社区中就有关于 NUMA 感知调度的设计文档[^10],虽然由于该特性的实现过于复杂,目前没有投入到开发中,但是这仍然是调度器未来的发展方向。
总结
很多软件工程师可能认为操作系统以及底层的硬件与我们的距离非常遥远,我们在开发软件时不需要考虑这么多细节,对于绝大多数的应用程序来说,这一点都是成立的,操作系统能够为我们屏蔽很多底层的实现细节,让我们能够将更多的精力投入到业务逻辑的实现上。
不过正如我们在文章中提到的,哪怕操作系统做出再多的隔离和抽象,物理世界存在的限制还是会在暗处影响我们的应用程序,想要开发高性能的软件必须要关注下两层甚至更底层的实现细节,NUMA 这种硬件层面的设计就会深刻的影响我们的软件,这里再来回顾一下文章开头提到的两点影响:
- NUMA 引入了本地内存和远程内存,CPU 访问本地内存的延迟会小于访问远程内存;
- NUMA 的内存分配与内存回收策略结合时会可能会导致 Linux 的频繁交换分区(Swap)进而影响系统的稳定性;
我们当然更希望主机上的所有 CPU 都能够快速地访问全部的内存,但是硬件的限制导致我们无法实现这么理想的情况,而 NUMA 可能是 CPU 架构发展的必然方向,通过将 CPU 和内存资源分组降低总线的压力,让单个主机容纳很多的 CPU。到最后,我们还是来看一些比较开放的相关问题,有兴趣的读者可以仔细思考一下下面的问题:
NUMA 架构最多可以支持多少 CPU?该架构又存在哪些瓶颈?
MPP(Massive Parallel Processing)是如何扩展系统的?它解决了哪些问题?
- Optimizing Linux Memory Management for Low-latency / High-throughput Databases https://engineering.linkedin.com/performance/optimizing-linux-memory-management-low-latency-high-throughput-databases
- NUMA (Non-Uniform Memory Access): An Overview https://queue.acm.org/detail.cfm?id=2513149
- PostgreSQL, NUMA and zone reclaim mode on linux http://frosty-postgres.blogspot.com/2012/08/postgresql-numa-and-zone-reclaim-mode.html
本文转载自微信公众号「真没什么逻辑」,可以通过以下二维码关注。转载本文请联系真没什么逻辑公众号。
















